| 精通Python自然语言处理 4 :词性标注 | 您所在的位置:网站首页 › 表示惊艳的英语单词有哪些词性 › 精通Python自然语言处理 4 :词性标注 |
精通Python自然语言处理 4 :词性标注
|
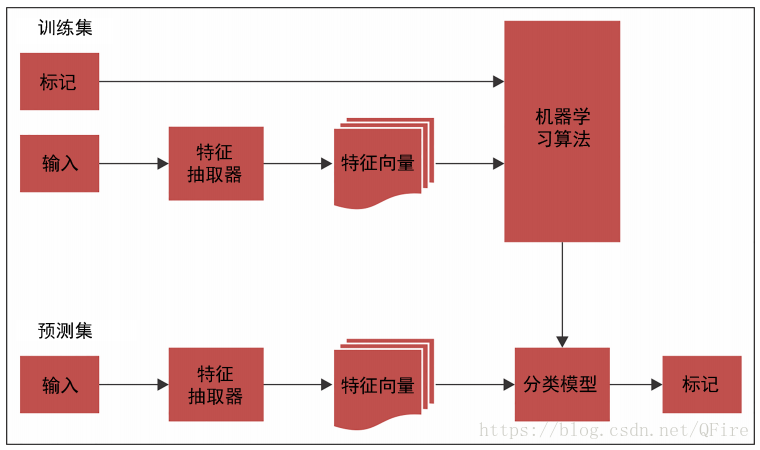
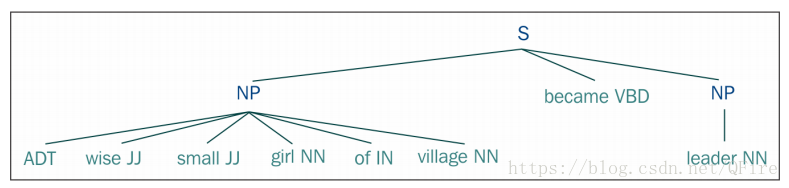
词性标注被用于信息检索、机器翻译、NER、语言分析等 1、词性标注简介一个对句中的每个标识符分配词类(如名词、动词、形容词等)标记的过程。在nltk.tag包中并被TaggerIbase类所继承。 >>> text1 = nltk.word_tokenize("It is a pleasnat day today") >>> nltk.pos_tag(text1) [('It', 'PRP'), ('is', 'VBZ'), ('a', 'DT'), ('pleasnat', 'JJ'), ('day', 'NN'), ('today', 'NN')]Penn Treebank的标记列表 https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html >>> nltk.help.upenn_tagset('VB.*')在NLTK中,已标注的标识符呈现为一个由标识符及其标记组成的元组。 >>> taggedword = nltk.tag.str2tuple('bear/NN') # 标识符及其标记组成的元组 >>> taggedword ('bear', 'NN') >>> taggedtok = ('bear', 'NN') # 单词及其词性标记 >>> nltk.tag.util.tuple2str(taggedtok) 'bear/NN' 默认标识:DefaultTagger类 2、创建词性标注语料库一个语料库可以认为是文档的集合。一个语料库是多个语料库的集合。 >>> from nltk.corpus import words >>> words.fileids() [u'en', u'en-basic'] >>> len(words.words('en')) 235886 3、选择一种机器学习算法词性标注也被称为词义消歧或语法标注 在训练词性分类器时,会生成一个特征集。大体组成如下: 当前单词的信息上一个单词或前缀的信息下一个单词或后缀的信息在NLTK中,FastBrillTagger类是基于一元语法的。它使用一个包含已知单词及其词性标记信息的字典。 一元语法意味着一个独立的单词,在一元语法标注器中,单个的标识符用于查找特定的词性标记。 可以通过在初始化标注器时提供一个句子的列表来执行UnigramTagger的训练 >>> from nltk.tag import UnigramTagger >>> from nltk.corpus import treebank >>> training = treebank.tagged_sents()[:7000] # 使用前7000个句子进行训练 >>> unitagger = UnigramTagger(training) >>> treebank.sents()[0] [u'Pierre', u'Vinken', u',', u'61', u'years', u'old', u',', u'will', u'join', u'the', u'board', u'as', u'a', u'nonexecutive', u'director', u'Nov.', u'29', u'.'] >>> unitagger.tag(treebank.sents()[0]) [(u'Pierre', u'NNP'), (u'Vinken', u'NNP'), (u',', u','), (u'61', u'CD'), (u'years', u'NNS'), (u'old', u'JJ'), (u',', u','), (u'will', u'MD'), (u'join', u'VB'), (u'the', u'DT'), (u'board', u'NN'), (u'as', u'IN'), (u'a', u'DT'), (u'nonexecutive', u'JJ'), (u'director', u'NN'), (u'Nov.', u'NNP'), (u'29', u'CD'), (u'.', u'.')]要评估UnigramTagger,下面用于计算其准确性的代码:准确率为96% >>> testing = treebank.tagged_sents()[2000:] >>> unitagger.evaluate(testing) 0.9634419196584355 --> 96% 5、使用词性标注语料库开发分块器分块是一个可用于执行实体识别的过程。它用于分割和标记居中的多个标识符序列 首先定义分块语法,包含了有关如何进行分块的规则。如下名词短语分块: >>> sent = [("A","DT"),("wise","JJ"),("small","JJ"),("girl","NN"),("of","IN"),("village","NN"),("became","VBD"),("leader","NN")] >>> grammar = "NP: {?*?*}" >>> find = nltk.RegexpParser(grammar) >>> res = find.parse(sent) >>> print(res) (S (NP A/DT wise/JJ small/JJ girl/NN of/IN village/NN) became/VBD (NP leader/NN))生成解析树: res.draw() 分块是语块的一部分被消除的过程,既可以使用整个语块,也可以使用语块中间的一部分并删除剩余的部分,或者也可以使用语块从开始或结尾截取的一部分并删除剩余的部分。 |
【本文地址】
公司简介
联系我们