| 大数据开发技术课程报告(搭建Hadoop完全分布式集群&&操作集群) | 您所在的位置:网站首页 › 蓝鲸大数据平台实训课报告 › 大数据开发技术课程报告(搭建Hadoop完全分布式集群&&操作集群) |
大数据开发技术课程报告(搭建Hadoop完全分布式集群&&操作集群)
|
文章目录
大数据开发技术课程报告内容及要求
一、 项目简介和实验环境
二、 虚拟机的各项准备工作
三、 安装JDK并配置环境变量
四、 安装Hadoop并配置环境变量
五、 配置Hadoop完全分布式集群
六、 启动Hadoop完全分布式集群
七、 Hadoop完全分布式集群的Shell操作
八、 Hadoop完全分布式集群的Java API操作
九、 阶段总结
大数据开发技术课程报告内容及要求
报告内容及要求 本报告作为“大数据开发技术”课程的阶段性考试内容,需要独立完成,可以参考资料。 报告内容 在Linux系统上,利用课上所学知识,根据自身机器配置,创建一个伪分布式Hadoop集群或完全分布式Hadoop集群,并对集群进行操作。需要在项目实现过程中,体现出通过本课程所学知识。 报告要求 集群形式可以根据机器配置在伪分布式和完全分布式间进行选择; Hadoop集群及所需组件的安装和配置需要截图; 关于Java的目录:需要自定义名称,添加学号后缀,比如学号为18B12345,那么JAVA_HOME的路径应该是…/java-18B12345,需要截图在报告中进行体现; 关于集群的测试:在Hadoop集群安装完成后,需要分别用官方提供的例子和Web UI进行测试,需要截图在报告中进行体现; 关于集群的操作:需要分别使用Shell形式和Java API对集群进行操作并截图在报告中进行体现,其中:在使用Java API时,Java项目的命名需要具有学号后缀,比如;学号为18B12345,那么如果创建的Java项目为hdfs-api,则实际创建的Java项目为hadfs-api-18B12345;如果创建的Java代码文件为main.java,则实际创建的.java文件为main_18B12345.java。 一、 项目简介和实验环境本项目主要是建立Hadoop完全分布式集群,并进行集群测试和操作。 主要内容:配置hadoop完全分布式集群的前期准备、安装过程、配置文件、启动过程、Shell操作、Java API操作。 (本文中的一些文件可能带有学号后缀,这是课程报告的要求,实际上不必写后缀) Linux发行版:ubuntu-18.04.4-desktop-amd64 JDK版本:jdk1.8.0_144 Hadoop版本:hadoop-2.7.2 二、 虚拟机的各项准备工作创建三台虚拟机,并完成各项准备工作。 以下的所有准备工作在三台虚拟机上都要做。由于在准备阶段,三台主机的操作几乎完全相同,所以在此以第一台主机hadoop1为例。 注意,本文的所有命令均是在root账号下运行。 (1) 修改主机名,依次为hadoop1,hadoop2,hadoop3。 (2) 关闭防火墙 输入命令ufw disable,关闭防火墙,重启后即可生效。 (3) 设置静态IP, hadoop1主机的设置如下图所示: 三台虚拟机都完成如上操作后,在hadoop1主机上测试是否能以root账号免密登录到hadoop2。 输入命令ssh root@hadoop2,无需输入密码则说明ssh免密登录配置成功,如下图所示: (5) 编写集群分发脚本xsync 输入命令vim /usr/local/bin/xsync,编写内容如下: #!/bin/bash if [[ -x $(command -v rsync) ]]; then echo yes > /dev/null else echo no rsync found! exit 1 fi #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args! exit; fi #2 获取文件名称 p1=$1 fname=$(basename $p1) echo fname=$fname #3 获取文件绝对路径 pdir=$(cd -P $(dirname $p1); pwd) echo pdir=$pdir #4 获取当前用户名称 user=$(whoami) #5 循环 for((host=2; host |
 输入命令ifconfig,查看一下IP,显示设置成功:
输入命令ifconfig,查看一下IP,显示设置成功: 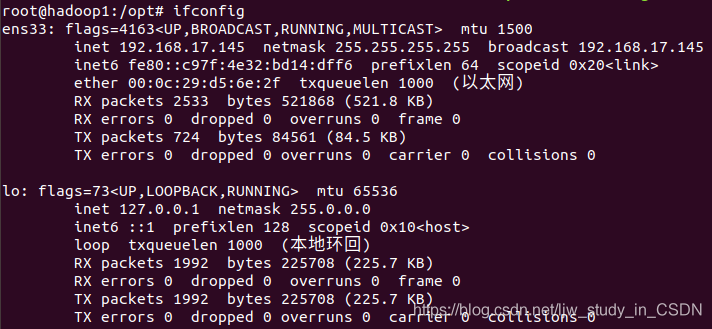 (4) 配置ssh免密登录,方便之后用xsync脚本进行集群分发。 输入命令vim /etc/hosts,将主机名与各自IP相对应,如下图所示:
(4) 配置ssh免密登录,方便之后用xsync脚本进行集群分发。 输入命令vim /etc/hosts,将主机名与各自IP相对应,如下图所示: 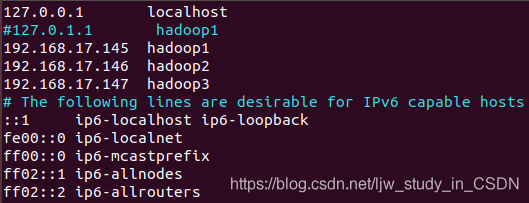 输入命令vim /etc/ssh/sshd_config,找到PermitRootLogin 配置项将原先的PermitRootLogin的prohibit-password修改为yes:
输入命令vim /etc/ssh/sshd_config,找到PermitRootLogin 配置项将原先的PermitRootLogin的prohibit-password修改为yes: 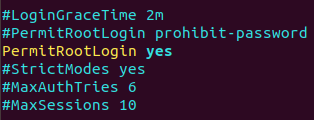 输入命令service ssh restart,重启ssh。 cd ~ (进入root目录) ssh-keygen -t rsa,再按3次回车 ~/.ssh会生成两个文件:id_rsa(私钥)、id_rsa.pub(公钥) 然后将其公钥加到3个虚拟机目录下(会生成一个authorized_keys的公钥,如果已经存在,则在该文件后面将会继续追加公钥内容),输入以下命令:
输入命令service ssh restart,重启ssh。 cd ~ (进入root目录) ssh-keygen -t rsa,再按3次回车 ~/.ssh会生成两个文件:id_rsa(私钥)、id_rsa.pub(公钥) 然后将其公钥加到3个虚拟机目录下(会生成一个authorized_keys的公钥,如果已经存在,则在该文件后面将会继续追加公钥内容),输入以下命令: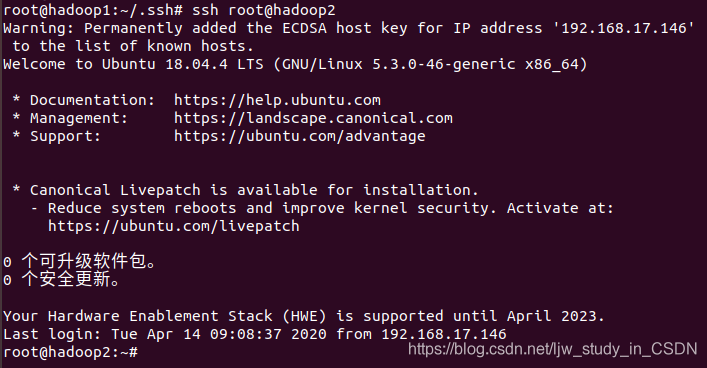 输入命令exit退出hadoop2的root账号,继续操作。
输入命令exit退出hadoop2的root账号,继续操作。【本文地址】