| 自然语言处理NLP(6) | 您所在的位置:网站首页 › 自然语言处理的过程包括哪五个层次 › 自然语言处理NLP(6) |
自然语言处理NLP(6)
|
在上一部分中,我们介绍了NLP领域中的一个基本问题:序列标注问题,并对解决该问题的三种方法:HMM、CRF、RNN+CRF进行了介绍。 在这一部分中,我们将在语言结构层面对词法分析进行介绍。 在了解了NLP架构之后(在博客:自然语言处理NLP(3)——神经网络语言模型、词向量中有过介绍,忘记了的朋友们可以翻回去看看),一定还记得这样一张图: 还是那句话,规则法、概率统计法、深度学习法都只是处理NLP问题的方法,归根结底最重要的还是NLP问题。 【一】词法分析词是最小的能够独立运用的语言单位,因此,词法分析是其他一切自然语言处理问题(例如:句法分析、语义分析、文本分类、信息检索、机器翻译、机器问答等)的基础,会对后续问题产生深刻的影响。 值得注意的是,这里所说的“字”并不仅限于汉字,也可以指标点符号、外文字母、注音符号和阿拉伯数字等任何可能出现在文本中的文字符号,所有这些字符都是构成词的基本单元。 从形式上看,词是稳定的字的组合。 很明显,不同的语言词法分析具体做法是不同的。 以英语和汉语为例作为对比: 两个任务分别面临着一些问题: 1.自动分词:歧义问题、未登录词问题、分词标准问题 2.词性标注:词性兼类歧义问题 (这些问题的具体含义我们将在后文进行介绍) 处理这些问题的方法依然有三种:规则法、概率统计法、深度学习法。 在这里,值得注意的是,由于不同的方法有其不同的优势和短板,因此,一个成熟的分词系统,不可能单独依靠某一种算法来实现,而需要综合不同的算法来处理不同的问题。 【二】自动分词面临的问题上面我们提到,自动分词面临着三个问题:歧义问题、未登录词问题、分词标准问题,下面我们将对它们一一进行解释。 歧义这里的歧义指的是切分歧义:对同一个待切分字符串存在多个分词结果。分为交集型歧义、组合型歧义和混合歧义。 交集型歧义:字串abc既可以切分成a/bc,也可以切分成ab/c。其中,a、bc、ab、c是词。 举个例子: “白天鹅”——“白天/鹅”、“白/天鹅”; “研究生命”——“研究/生命”、“研究生/命” 至于具体要取哪一中分词方法,需要根据上下文来推断。 也许对于我们来说,这些歧义很好分辨,但是对计算机而言,这是一个很重要的问题。 针对交集型歧义,提出链长这一概念:交集型切分歧义所拥有的交集串的个数称为链长。 举个例子(朋友们可以自己划分一下,还蛮有趣的): “中国产品质量”:{国、产、品、质},链长为4; “部分居民生活水平”:{分、居、民、生、活、水},链长为6. 组合型歧义:若ab为词,而a和b在句子中又可分别单独成词。 举个例子: “门把手弄坏了”——“门/把手/弄/坏/了”、“门/把/手/弄/坏/了” “把手”本身是一个词,分开之后由可以分别成词。 混合歧义:以上两种情况通过嵌套、交叉组合等而产生的歧义。 举个例子: “这篇文章写得太平淡了”,其中“太平”是组合型歧义,“太平淡”是交集型歧义。 通过上面的介绍可以看出,歧义问题在汉语中是十分常见的。 未登录词未登录词是指:词典中没有收录过的人名、地名、机构名、专业术语、译名、新术语等。该问题在文本中的出现频度远远高于歧义问题。 未登录词类型: 1.实体名称:汉语人名(张三、李四)、汉语地名(黄山、韩村)、机构名(外贸部、国际卫生组织); 2.数字、日期、货币等; 3.商标字号(可口可乐、同仁堂); 4.专业术语(万维网、贝叶斯算法); 5.缩略语(五讲四美、计生办); 6.新词语(美刀、卡拉OK) 未登录词问题是分词错误的主要来源。 分词标准对于 “汉语中什么是词” 这个问题,不仅普通人有词语认识上的偏差,即使是语言专家,在这个问题上依然有不小的差异。 “缺乏统一的分词规范和标准” 这种问题也反映在分词语料库上,不同语料库的数据无法直接拿过来混合训练。 【三】自动分词技术方法在了解自动分词所面临的问题之后,我们再来介绍进行自动分词的技术方法。基本方法还是三种:规则法、概率统计法、深度学习法。 A. 基于字典、词库匹配的分词方法(机械分词法)该类算法是按照一定的策略将待匹配的字符串和一个已建立好的“充分大的”词典中的词进行匹配,若找到某个词条,则说明匹配成功,识别了该词。 基于词典的分词算法在传统分词算法中是应用最广泛、分词速度最快的一类算法。 其优点是实现简单、算法运行速度快; 缺点是严重依赖词典,无法很好的处理分词歧义和未登录词。 这类方法主要有: 1.正向最大匹配法(从左到右) 2.逆向最大匹配法(从右到左) 3.最少切分法(使每一句中切出的词数最少) 4.双向最大匹配法(进行从左到右、从右到左两次扫描) (1)最大匹配法基本思想:先建立一个最长词条字数为 L L L 的词典,然后按正向(逆向)取句子前 L L L 个字查词典,如查不到,则去掉最后一个字继续查,一直到找着一个词为止。 最大匹配算法以及其改进方案是基于词典和规则的。其优点是实现简单,算法运行速度快,缺点是严重依赖词典,无法很好的处理分词歧义和未登录词。 举个例子:“他是研究生物化学的”(假设词典中最长词条字数为7) 正向结果:“他/是/研究生/物化/学/的” 逆向结果:“他/是/研究/生物/化学/的” (2)最少分词法(最短路径法)基本思想:假设待切分字串为: S = c 1 c 2 . . . c n S=c_1c_2...c_n S=c1c2...cn,其中 c i c_i ci 为单个字,串长为 n n n( n ≥ 1 n≥1 n≥1)。建立一个结点数为 n + 1 n+1 n+1 的切分有向无环图 G G G,若 w = c i c i + 1 . . . c j w=c_ic_{i+1}...c_j w=cici+1...cj( 0 ; i ; j ≤ n 0;i;j≤n 0 |
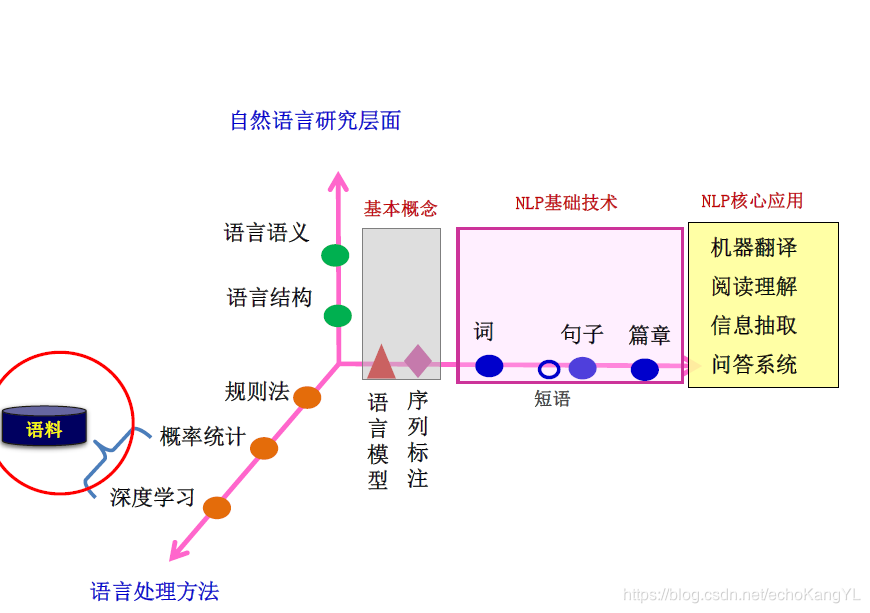 现在,我们已经了解了自然语言研究层面的基本概念:语言模型、序列标注,下一步就是对“词”的分析和处理。
现在,我们已经了解了自然语言研究层面的基本概念:语言模型、序列标注,下一步就是对“词”的分析和处理。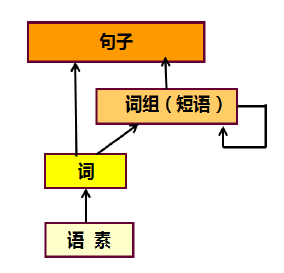 而词法分析的任务就是:将输入的句子字串转换成词序列并标记出各词的词性。
而词法分析的任务就是:将输入的句子字串转换成词序列并标记出各词的词性。 对于中文词法分析而言,具体任务如下图所示: 以句子:“警察正在详细调查事故原因” 为例。
对于中文词法分析而言,具体任务如下图所示: 以句子:“警察正在详细调查事故原因” 为例。  中文分词词法分析包括两个主要任务: 1.自动分词:将输入的汉字串切成词串 2.词性标注:确定每个词的词性并加以标注
中文分词词法分析包括两个主要任务: 1.自动分词:将输入的汉字串切成词串 2.词性标注:确定每个词的词性并加以标注【本文地址】