| 4.5.1 VIP视频爬取 | 您所在的位置:网站首页 › 腾讯视频网页源代码提取视频 › 4.5.1 VIP视频爬取 |
4.5.1 VIP视频爬取
|
4.5.1 VIP视频爬取
冬夜微醺,挑灯回叹,巍哥无心睡眠,突然想看片。于是巍哥上网搜索python,学习了起来。 一、基本概念 爬虫是什么爬虫是指请求网站并获取数据的自动化程序。谷歌的搜索引擎爬虫,隔几天对全网的网页爬取一遍,供大家查阅,这应是善意爬虫。但12306抢票软件爬虫,为了私欲无节制地访问网站,这就是恶意爬虫。技术很单纯,哲学很复杂。 爬虫做什么我们访问网站:浏览器提交请求->下载网页代码->解析成页面 爬虫访问网站:模拟浏览器发送请求->获取网页代码提取有用数据->存于数据库或文件中 访问网站的HTTP连接消息报文有Request请求和Response响应两种。用户发送Request后浏览器接收到网站Response后,会解析其内容来显示给用户。而爬虫程序则是模拟浏览器发送请求接收网站Response后,提取其中有用数据。 反爬是什么猫和老鼠已可以和谐共处了,矛与盾虽惺惺相惜却很难真正的亲近。爬-反爬-反反爬-反反反爬……对反爬手段建立初步概念,小白在学习实践中可以多些思考的方向避免入坑。 判断请求头来进行反爬 这是网站早期的反爬方式:User-Agent/referrer/cookie 措施:请求头里面添加对应的参数(复制浏览器里面的数据) 根据用户行为来进行反爬 请求频率过高,服务器设置规定时间之内的请求阈值 措施:降低请求频率或者使用代理(IP代理) 网页中设置一些陷阱(正常用户访问不到但是爬虫可以访问到) 措施:分析网页,避开这些特殊陷阱 请求间隔太短,返回相同的数据 措施:增加请求间隔 js加密 常见反爬方式,文中获取视频下载地址时网站便将时间信息做了js加密附值给参数。 参数加密 服务器响应给浏览器的js文件,动态生成一些加密参数,浏览器会根据js的计算得到这些参数。如果请求中没有这些参数,那么服务器就认为请求无效。措施:研究JS,找到生成参数的算法模拟实现。或使用execjs把js代码提取到py文件中执行。 Cookie加密 浏览器运行网站JS生成一个(或多个)cookie再带着这个cookie做二次请求。服务器那边收到这个cookie就认为你的访问是通过浏览器过来的合法访问。 措施:研究JS,找到生成Cookie的算法模拟实现(把Chrome浏览器保存的该网站的cookie删除后F12观察) ajax请求参数加密 抓某个网页里面的数据,发现网页源代码里面没有我们要的数据,那些数据往往是ajax请求得到的。 措施: 通过debug JS来找到对应的JS加密算法。F12 “XHR/fetch Breakpoints”、 Selenium+PhantomJS JS反调试(反debug) 打开F12时,会暂停在一个“debugger”代码行,无论怎样都跳不出去。这个“debugger”让我们无法调试JS。但是关掉F12窗口,网页就正常加载了。 措施:在这个函数调用的地方打个“Breakpoint”。刷新页面,在Console里面重新定义它为空,继续运行就可以跳过该陷阱。 JS发送鼠标点击事件 从浏览器可以打开正常的页面,而在requests里面却被要求输入验证码或重定向其它网页。F12观察,每点击页面的的链接,它都会做一个“cl.gif”的请求。它请求时发送的参数非常多,如包含了被点击的链接等等。因为requests没有鼠标事件响应就没有访问cl.gif的过程就直接访问链接,服务器就拒绝服务。 措施:访问链接前先访问一下cl.gif,带上所需参数。 字体加密 网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据是乱码 登录验证码 验证码登陆才能访问其网站,从最开始使用简单验证码,识别数字,到更复杂的验证码如:内容验证码、滑动验证码、图片拼接验证码等等。 措施:一种方法是通过第三方平台接口,完成验证码的验证。 常用加密算法、编码 MD5、ASE、RSA、base64 二、视频爬取 各大视频网站,VIP视频一般可以试看6分钟。所以网络上就出现了大量的视频解析网站,在这个灰色地带,应该是白嫖吸引流量通过广告谋利。其原理就是调用第三方「视频解析接口」实现的,源头估计是一些有VIP账号的在后台解析视频然后分享。随着版权意识、版权管理的加强,以及技术的更新迭代,这类「视频解析接口」也大量的失效了。 视频观看打开如爱奇艺,搜索《肖申克的救赎》,网址:https://www.iqiyi.com/v_19rra0h3wg.html 借助第三方视频解析接口,观看只需要三行代码即可实现: import webbrowser url='https://okjx.cc/?url=https://www.iqiyi.com/v_19rra0h3wg.html' webbrowser.open(url)文中使用的解析接口: # 视频接口时效不定,找了几个接口。线路二可以查看剧集,但有广告 self.lines = { "Line-1": "https://okjx.cc/?url={}", "Line-2": "https://z1.m1907.cn/?jx={}", "Line-3": "https://jx.618g.com/?url={}", "Line-4": "http://www.sfsft.com/admin.php?url={}", } 视频下载 付费内容,网站肯定不会想让轻易得到。通过解析接口可以观看,按道理也就应该能拿到视频实际地址。视频下载,一般而言,无非两种情况: 一种,链接明确是以 mp4、mkv、rmvb 这类视频格式后缀为结尾的链接,这种下载很简单,跟图片下载方法一样,就是视频文件要比图片大而已。 另一种,链接是以 m3u8 这类分段视频后缀结尾的链接,视频都是分段存储的。观看视频,其实是在加载一个个 ts 视频片段,一个片段是几秒钟的视频。下载视频就是将 ts 视频片段组合成最终视频。m3u8 这种格式的视频,就是由一个个 ts 视频片段组成的。所以下载的关键是要获取m3u8文件的地址。 拿到了关键的m3u8文件,多线程加快下载速度,然后用FFmpeg拼接ts文件为一个mp4文件。FFmpeg,它的中文名叫多媒体视频处理工具。FFmpeg 有非常强大的功能包括视频采集、视频格式转换、视频抓图、给视频加水印等功能。这种 ts 视频片段合成,格式转换问题,交给 FFmpeg 就好了。 Windows下的ffmpeg下载安装 官方下载地址:https://ffmpeg.org/download.html 安装好记得将安装路径添加到系统环境变量中 在Python中使用ffmpy pip install ffmpy3 导入模块后, 修改ffmpy3.py文件的__init__中的executable为ffmpeg可执行文件的路径 : def __init__(self, executable='D:\\anaconda3\\ffmpeg', global_options=None, inputs=None, outputs=None): (例中,把ffmpeg.exe,ffplay.exe,ffprobe.exe三个执行文件拷到了Python安装目录) 确认m3u8文件地址 打开浏览器Chrome方便使用开发者工具F12,使用线路1(快速且无广告),输入网址接口观看视频地址: https://okjx.cc/?url=https://www.iqiyi.com/v_19rra0h3wg.html ,视频播放的同时,F12观察: 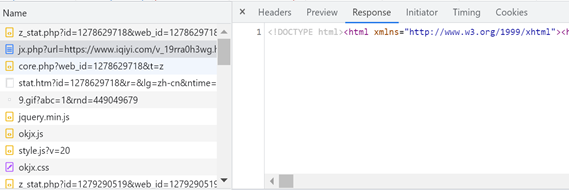
在出现大量ts文件之前,找了一阵子也没找到包含m3u8文件的请求与应答。 于是换了线路2进行尝试:https://z1.m1907.cn/?jx=https://www.iqiyi.com/v_19rra0h3wg.html 开心地发现很容易就看到第4条请求中就包含着m3u8的应答: 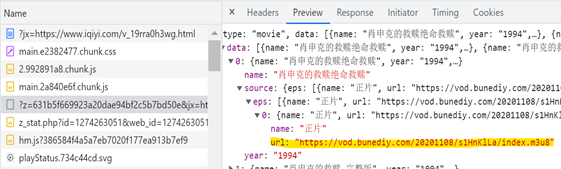
请求头内容为: 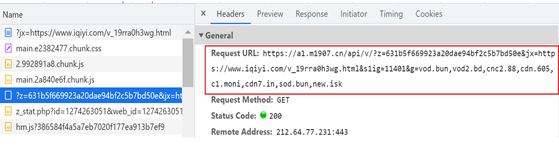
请求的参数为:可见有z, jx, sqig, g , 4个参数 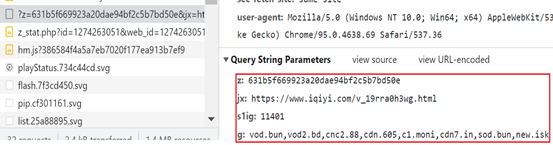
应答内容为: 
至此,顺利地达成所愿: https://a1.m1907.cn/api/v/?z=631b5f669923a20dae94bf2c5b7bd50e&jx=https://www.iqiyi.com/v_19rra0h3wg.html&s1ig=11401&g=vod.bun,vod2.bd,cnc2.88,cdn.605,c1.moni,cdn7.in,sod.bun,new.isk 可知jx=https://www.iqiyi.com/v_19rra0h3wg.html 中将地址更改为想看视频的链接,就可以得到视频的m3u8文件供下载。 可惜高兴了几个小时,过了0:00,发现这样请求失效了。重新播放获取地址对比发现: https://a1.m1907.cn/api/v/?z=5d855143e6fd5d1a252ac6c34b2b7e0f&jx=https://www.iqiyi.com/v_19rra0h3wg.html&s1ig=11401&g=vod.bun,vod2.bd,cnc2.88,cdn.605,c1.moni,cdn7.in,sod.bun,new.isk 问题便出在参数z=5d855143e6fd5d1a252ac6c34b2b7e0f上,它变了。可见这个参数经过了加密且和时间有关。那么请求中的z是怎么得来的呢。如前图所示,在该请求之前,网站还有2条请求像是js文件。尝试搜索z=: 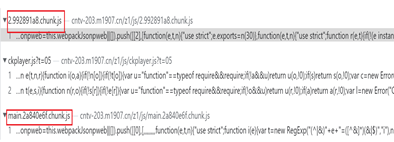
可见请求之前的两个js文件都有z的出现。那么,继续到js文件中找到z的实现: case 33: c = new Date, l = c.getTime(), u = 6e4 * c.getTimezoneOffset(), d = l + u + 36e5 * 8, m = new Date(d), p = (p = m).getDate() + 9 + 9 ^ 10, p = (p = St()(String(p))).substring(0, 10), p = St()(p), b = m.getDay() + 11397, v = "//a1.m1907.cn/api/v/?z=".concat(p, "&jx=").concat(o), v += "&s1ig=".concat(b), (g = fe.getAll()) && (v += "&g=".concat(g.join(","))), o || (v = "//a1.m1907.cn/api/v/"),找到了js代码中参数z的实现,但打断点跟踪那个St( )怎么定义却迷失了方向,到后来没信心将那些密密麻麻的实现弄过来是否值得花时间。😦 在要放弃时发现:5d855143e6fd5d1a252ac6c34b2b7e0f,这个32数字很像MD5算法的输出。于是不甘心地用MD5去试了一下,居然成功了。(希望等以后能力提升了再返回去把这个问题搞清楚) 😃 模拟用python实现: ''' 模拟网站JS中加密: request中的query string parameters: "z": "5d855143e6fd5d1a252ac6c34b2b7e0f", "jx": "{}" "s1ig": "11399", js文件的定义: c = new Date, l = c.getTime(), u = 6e4 * c.getTimezoneOffset(), d = l + u + 36e5 * 8, m = new Date(d), p = (p = m).getDate() + 9 + 9 ^ 10, p = (p = St()(String(p))).substring(0, 10), p = St()(p), b = m.getDay() + 11397, v = "//a1.m1907.cn/api/v/?z=".concat(p, "&jx=").concat(o), v += "&s1ig=".concat(b), ''' def MD5p() : lt = datetime.datetime.now() ut = datetime.datetime.utcnow() o = ((ut.day-lt.day)*24+ut.hour-lt.hour)*60 #o = (ut.hour-lt.hour)*60 l = int(time.time()*1000) u = int(6e4 * o) d = int(l + u + 36e5 * 8) m = time.strptime(time.ctime(d/1000)).tm_mday p = str(m+ 9 + 9^10) b = lt.weekday()+1 + 11397 p=md5(p.encode()).hexdigest() p=md5(p[0:10].encode()).hexdigest() return p, b关键参数z,s1ig便搞定了。剩下的就容易多了。 :) 拿到了关键的m3u8文件,多线程下载,用FFmpeg拼接ts文件为一个mp4文件。 至此,巍哥点燃一支烟,长吁一口气。 【代码实现】 附界面显示:
|
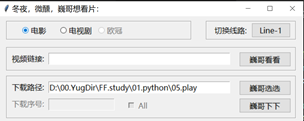
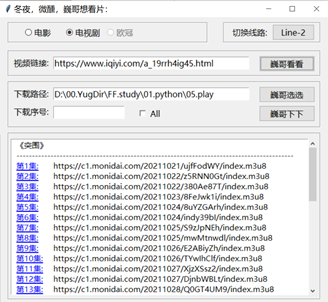
【本文地址】