| 【保姆级】基于腾讯云云服务器CVM部署ChatGLM3 | 您所在的位置:网站首页 › 腾讯云云电脑是怎么回事 › 【保姆级】基于腾讯云云服务器CVM部署ChatGLM3 |
【保姆级】基于腾讯云云服务器CVM部署ChatGLM3
|
概述 本文主要介绍 ChatGLM3-6B 的保姆级部署教程,在使用和我相同配置的腾讯云云服务器(是国内的服务器哦!这个难度,懂得都懂),保证一次成功。  ChatGLM3介绍 ChatGLM3介绍ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性: 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。 ChatGLM3-6B系列分为如下三个: 模型 序列长度 ChatGLM3-6B 8k ChatGLM3-6B-Base 8k ChatGLM3-6B-32K 32k 购买腾讯云云服务器CVM我购买的配置详见下图:  在购买腾讯云云服务器时,需要选中后台自动安装GPU驱动,具体版本请见下图。 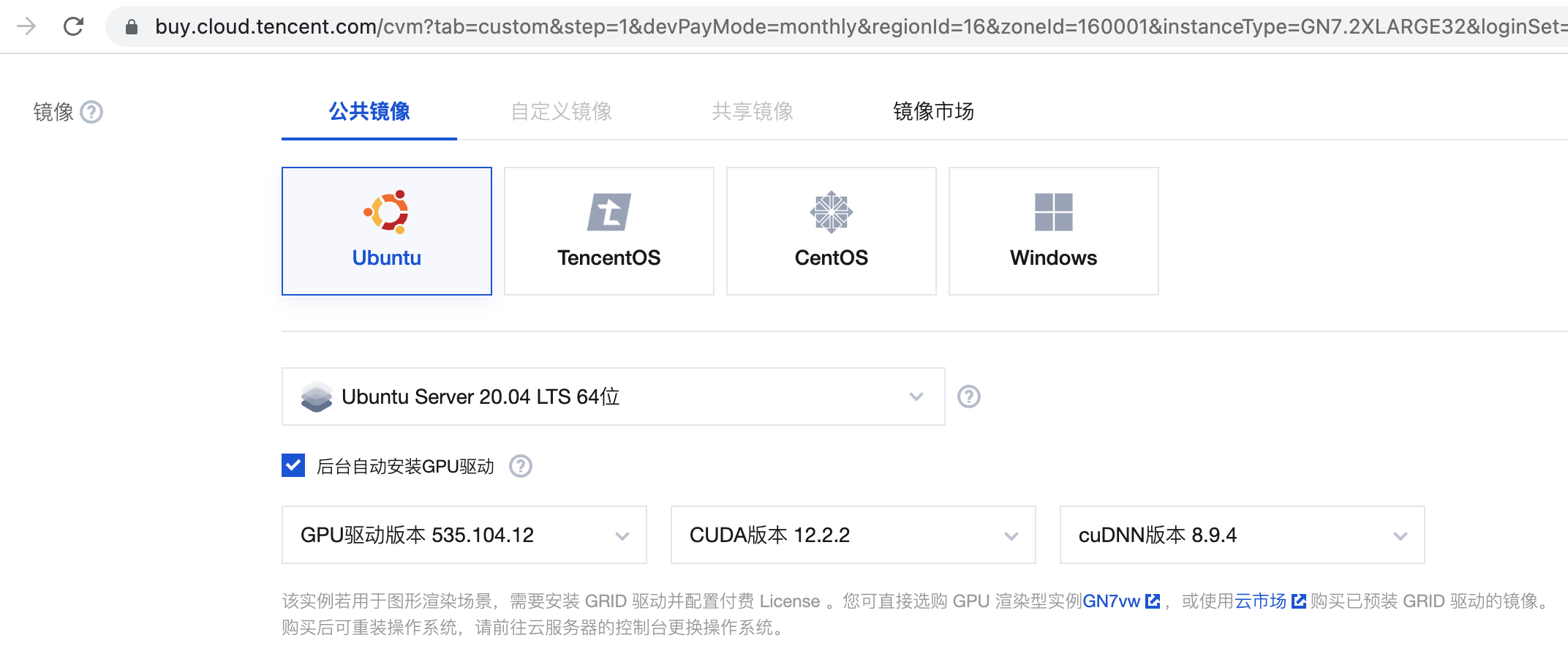 由于我购买的是国内成都区域,由于国内github的DNS的污染问题,如果发现网速很慢,建议 sudo vim /etc/hosts 做一下域名绑定。 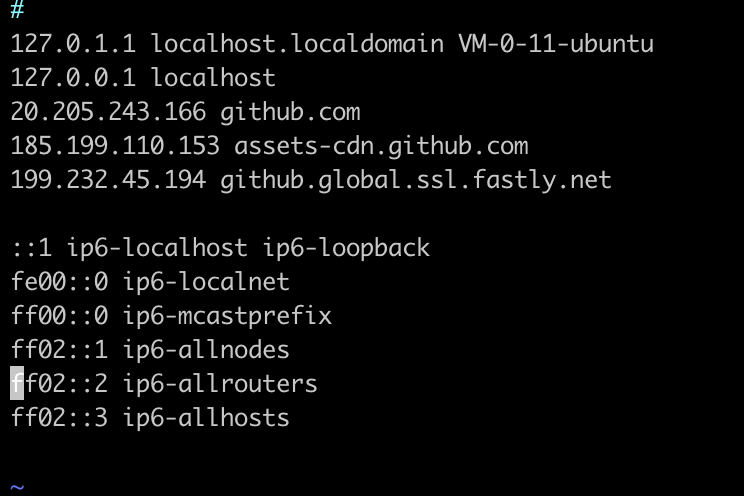 部署ChatGLM3-6B 部署ChatGLM3-6B这里部署的版本是ChatGLM3-6B这个版本。 构建账户环境代码语言:txt复制adduser sd sudo usermod -aG sudo sd 安装conda 安装conda命令行使用su - sd登陆到sd账号下,安装conda。由于是国内成都区域,速度较慢,因此使用了nohup。 代码语言:txt复制nohup wget "https://repo.anaconda.com/archive/Anaconda3-2023.03-Linux-x86_64.sh" & sh Anaconda3-2023.03-Linux-x86_64.sh安装完成后执行 “bash”命令,重新载入bash终端,确保conda命令可用。最好exit退出再登陆。 代码语言:txt复制conda create -n sd python=3.10.6创建完成后切换至sd环境 代码语言:txt复制conda activate sd安装chatglm3-6b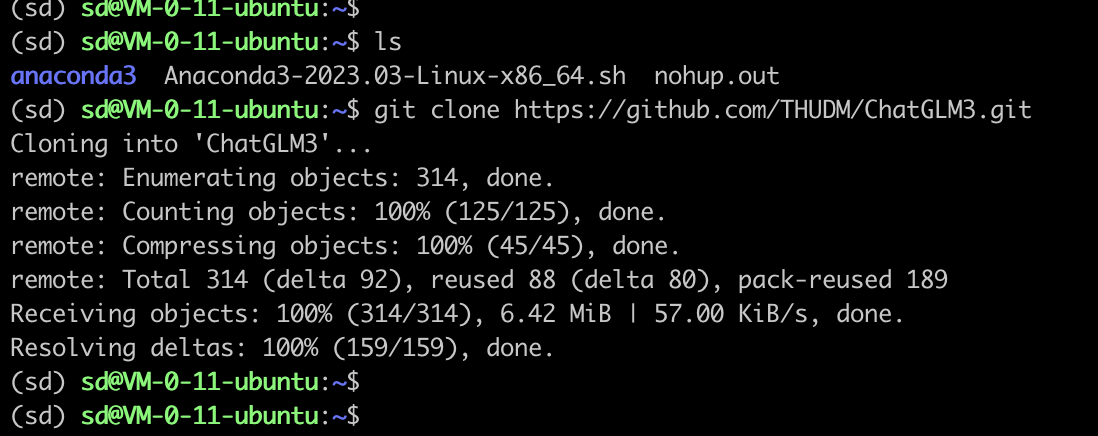 代码语言:txt复制git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
pip install -r requirements.txt 代码语言:txt复制git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
pip install -r requirements.txt如果pip install -r requirements.txt执行得特别慢,可以更换为清华源,如下所示: 代码语言:txt复制pip install -r requirements.txt --index-url https://pypi.tuna.tsinghua.edu.cn/simple由于huggingface在腾讯云云服务器上实在是太慢了,因此改为使用modelscope。vim进入此目录下web_demo.py文件,如下修改: 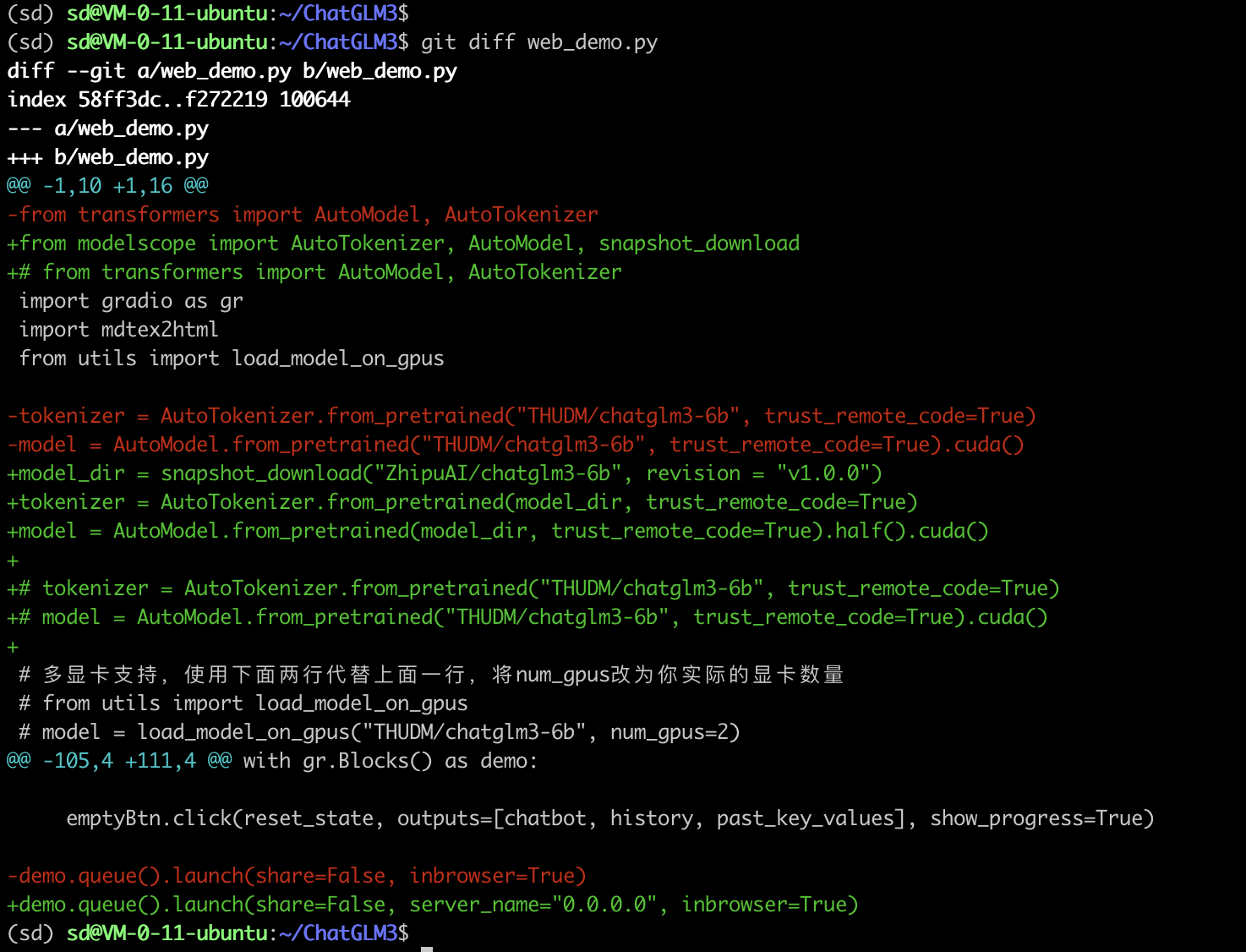 代码语言:shell复制(sd) sd@VM-0-11-ubuntu:~/ChatGLM3$ git diff web_demo.py
diff --git a/web_demo.py b/web_demo.py
index 58ff3dc..f272219 100644
--- a/web_demo.py
+++ b/web_demo.py
@@ -1,10 +1,16 @@
-from transformers import AutoModel, AutoTokenizer
+from modelscope import AutoTokenizer, AutoModel, snapshot_download
+# from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
from utils import load_model_on_gpus
-tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
-model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
+model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
+tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
+model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
+
+# tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
+# model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
@@ -105,4 +111,4 @@ with gr.Blocks() as demo:
emptyBtn.click(reset_state, outputs=[chatbot, history, past_key_values], show_progress=True)
-demo.queue().launch(share=False, inbrowser=True)
+demo.queue().launch(share=False, server_name="0.0.0.0", inbrowser=True) 代码语言:shell复制(sd) sd@VM-0-11-ubuntu:~/ChatGLM3$ git diff web_demo.py
diff --git a/web_demo.py b/web_demo.py
index 58ff3dc..f272219 100644
--- a/web_demo.py
+++ b/web_demo.py
@@ -1,10 +1,16 @@
-from transformers import AutoModel, AutoTokenizer
+from modelscope import AutoTokenizer, AutoModel, snapshot_download
+# from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
from utils import load_model_on_gpus
-tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
-model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
+model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
+tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
+model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
+
+# tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
+# model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
@@ -105,4 +111,4 @@ with gr.Blocks() as demo:
emptyBtn.click(reset_state, outputs=[chatbot, history, past_key_values], show_progress=True)
-demo.queue().launch(share=False, inbrowser=True)
+demo.queue().launch(share=False, server_name="0.0.0.0", inbrowser=True)执行脚本: 代码语言:txt复制nohup python web_demo.py &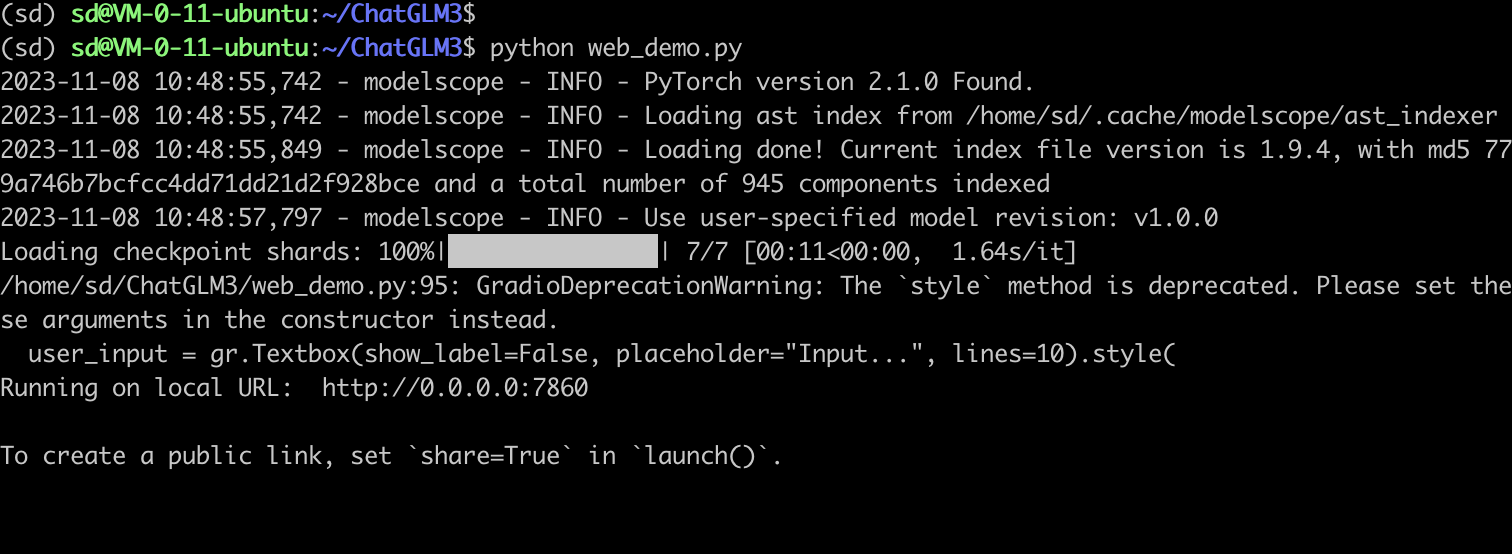 注意:腾讯云安全组需要放开TCP:7860端口。 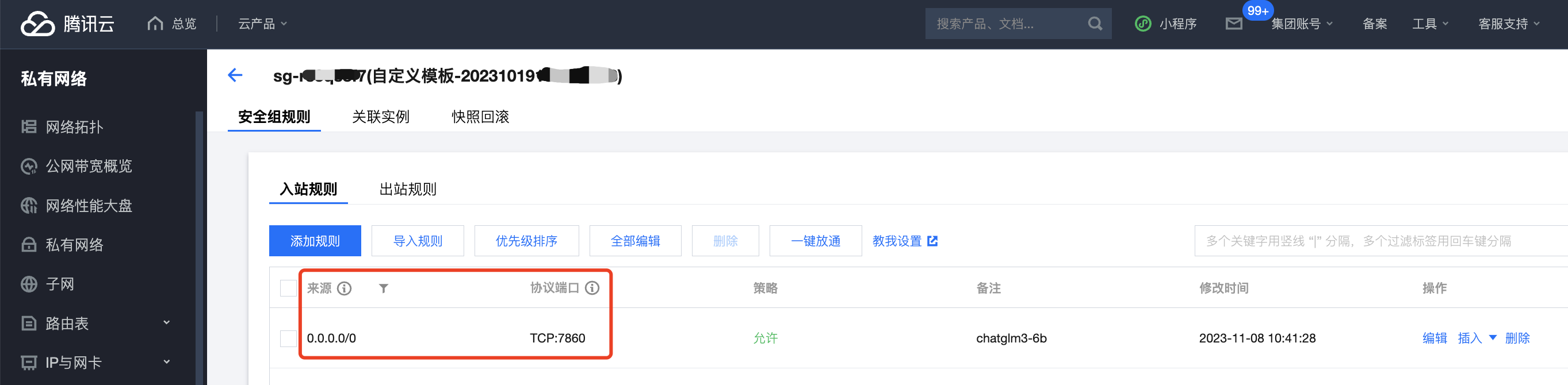 总结 总结 整个过程,相对于我的想象,要简单很多,在界面执行上,相对比较迅速,值得试用。不过,ChatGLM3-6B对显存的占用上有12GB。下面是nvidia-smi的输出: 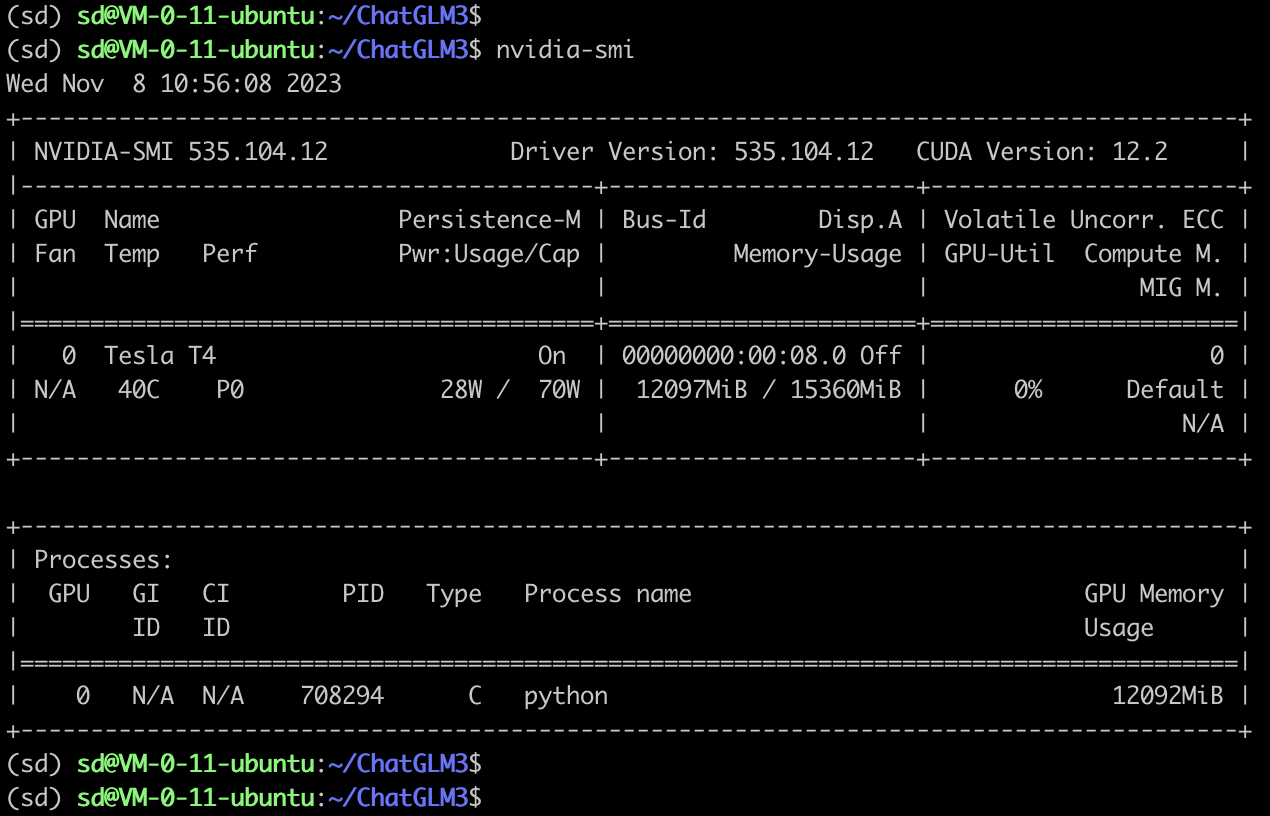 因此,如果对话过长,会有OutOfMemory的问题。小伙伴们有解决方案,欢迎评论区留言哦! |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |