| 利用机器学习分析脑电数据(原理分析+示例代码+快速上手) | 您所在的位置:网站首页 › 脑电波的类型 › 利用机器学习分析脑电数据(原理分析+示例代码+快速上手) |
利用机器学习分析脑电数据(原理分析+示例代码+快速上手)
|
由于本人对于脑机接口以及脑电技术的极度爱好(其实目的是:是把U盘插到大脑里,然后就不用学习了哈哈哈哈),近几月看了较多这方面的内容,变打算写下博客总结分析一下。 目录 一、 机器学习分析简介 二、机器学习分析的脑电特征 三、机器学习训练分析 四、机器学习分析的特征选择和降维 五、机器学习分析的选择分类器 六、机器学习分析的结果评估 七、机器学习实例分析 机器学习和模式识别已被广泛应用于脑电信号分析领域,为从高纬度脑电信号提取和描述与任务相关的大脑状态提供了新的方法。鉴于近年来机器学习技术引发的持续关注及广泛的应用,我收集了近年来常见的利用机器学习技术处理脑电信号的案例,并分析总结出了本文内容。首先,我会带领大家分析并简单介绍机器学习的基本概念,接着引出一个关于区分睁眼闭眼状态下静息脑电的科学问题,并逐步介绍如何提取特征、训练特征、选择特征、降维分析、选择分类器、评估选择,最后进行模式表达。最后我们探讨了深度学习在未来研究中的应用。最后利用MATLAB进行了详细的脑电数据处理的介绍与应用。
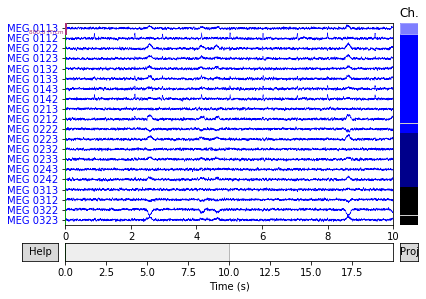
基于脑电信号毫秒级别的时间分辨率,脑电已被广泛地应用于研究人脑中与感觉和认知相关的神经活动(Hu et al.,2011;Tu et al.,2014,2016;Zhang et al.,2012)。通过结合相关实验,对被试施加外界刺激或者要求其进行指定任务,脑与行为间的关联可以通过脑电反映出来。然而,脑电能在何种程度上实现“大脑解码”仍然是个疑问。例如,运用脑电来检测个体的行为状态(睁眼或是闭眼)准确率能够达到多少?我们能否运用脑电实时监测个体的认知程度?除开发脑电采集系统和优化实验设计之外,创新的数据分析方法是解决上述问题的关键。
近年来,使用机器学习技术来分析脑电信号引起了广泛的关注( Blankertz et al., 2011;Makeig et al.,2012;Müller et al.,2008 )。越来越多的研究证据表明,机器学习可以从高维度且有噪声的脑电信号中提取有意义的信息。鉴于相关技术的关注度和广泛应用,本章我们将介绍如何使用机器学习来分析脑电信号,包括机器学习的方法和相关应用,并探讨深度学习算法在未来研究中的应用前景。
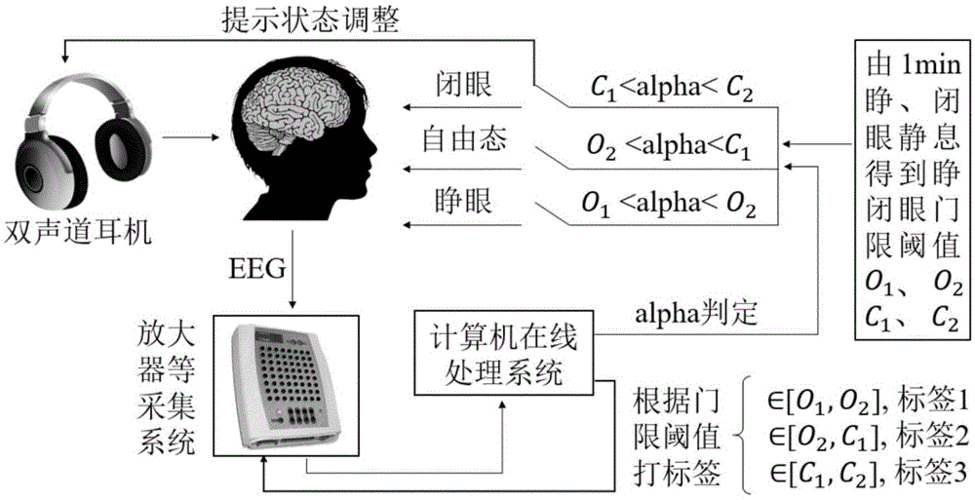
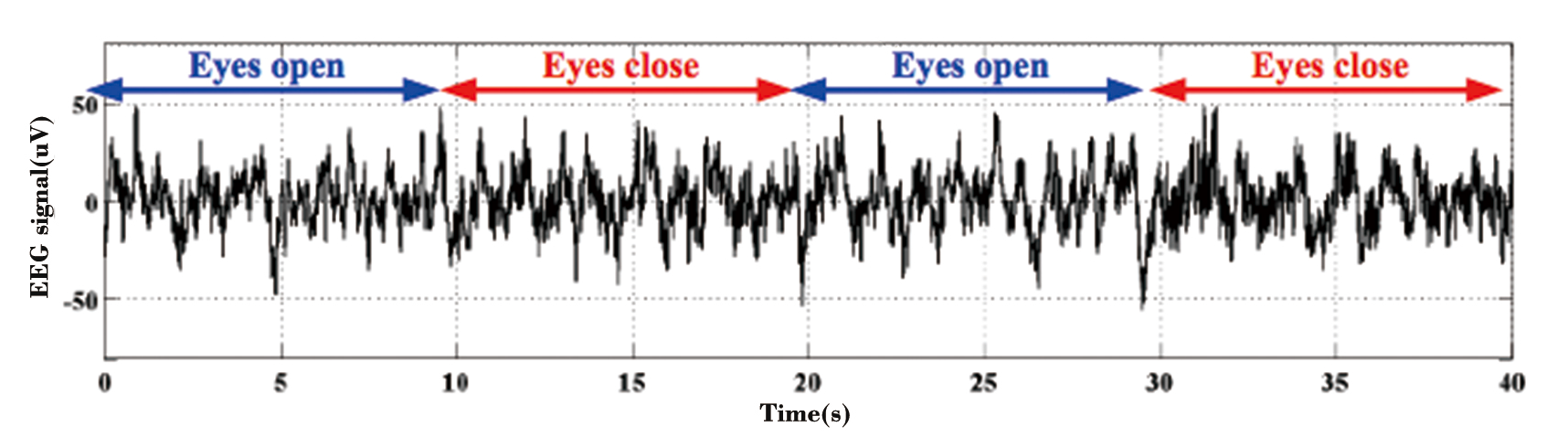
详细的机器学习请参考这篇博客:机器学习系列(一)——机器学习简介_zxhohai的博客-CSDN博客_机器学习 研究者设计神经成像实验区分大脑的不同状态,而从实验中采集到的脑电信号往往包含大脑中的认知或感觉反应。传统的分析方法大多运用回归分析来建立基于特定假设的脑电信号特征(例如,ERP及其与行为指标之间的关系),或是通过单独分析每个样本,来确定时间域或频率域中的哪些特征参与了大脑中认知状态或感觉反应的处理。我们称这些传统方法为“单变量分析”。从理论上讲,如果大脑的某个特定时间点上的活动在两种状态下存在差异,那么就有可能利用这种脑活动来解码个体的认知状态或感觉反应。例如,α频段振荡的能量与睁眼和闭眼状态密切相关。然而,大多数情况下,我们往往很难找到一个能够提供足够大的差别来区分两种状态的单独特征,从而导致无法做出准确的判断。 机器学习分类器可以被看作一个函数,其将不同状态下的大脑活动的各种特征值作为自变量,并预测未知状态属于何类(因变量)。下面介绍关于机器学习的几个基本概念。 类:一个对象所属的类别。在一个类中,一组模式共享公共属性并且通常来自同一个源。 模式 : 一个对象的特征集合,以及该对象的类信息。样本:对象的任何给定的模式都称为样本。 特征 : 一组带有区分和鉴别一个对象的信息的变量。 特征向量 : 一个样本中K个特征的集合,以某种方式排列咸K维向量。特征空间:特征向量所在的K维空间。 在一个脑电实验中,特征可以从时间域、频率域或者空间域中被提取。类可以是认知状态或感觉反应。我们可以将N个样本的K个特征(例如,一次试验或一个被试为一个样本)指定为类标签。
为了在脑电研究中使用机器学习分析,我们需要确定哪些脑电特征可以用来区分实验条件。对于自发性脑电数据,我们通常在频率域通过频率和幅值来研究信号。例如,闭眼状态的静息状态脑电数据α频段震荡的能量显著高于闭眼状态。
有一些特征既可以用来分析自发性脑电,也可以用来分析ERP。
总之,选择合适的脑电信号特征对于机器学习分析至关重要。研究人员可以根据假设或者数据驱动搜索做出决定。 三、机器学习训练分析机器学习分类器的目标是基于通过训练获得的一些先验知识来估计给定特征向量对应的正确类别。训练是分类器学习特征向量与其对应的类标签之间映射关系的过程。特征向量和对应类标签之间的这种关系在特征空间中形成了一个决策边界,它使得不同类的模式彼此分开。 在训练分类器之前,我们需要将样本(特征向量和类标签)整理成为训练数据集(用于训练分类器的数据;已知数据类标签)和测试数据集(用于评估分类器性能的数据;通常与训练数据同时采集或从训练数据中划分;未知数据类标签)。在某些情况下,还会有一个独立数据集(采用被训练好的分类器对未知数据进行分类;未知数据类标签)。在训练分类器过程中,我们需要在使用更多的有噪声的样本(例如,单次提取的脑电信号)或更少的干净的信号(例如,平均信号)之间权衡。一方面,拥有更多的样本有助于分类器在训练中进行更好的参数估计,并提高测试的能力,以保证测试的准确性;另一方面,噪声会影响参数估计,在某些情况下会使得分类器的参数过度拟合噪声,影响分类器的性能。 使用交叉验证的方法可以利用所有数据进行训练和测试。
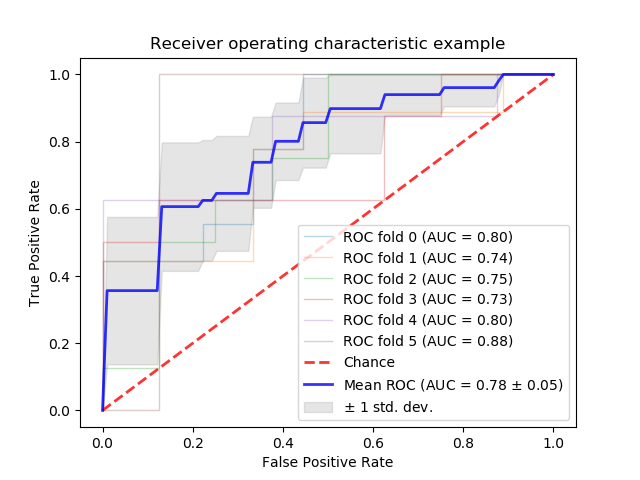
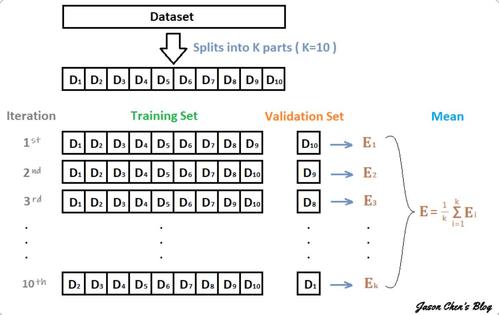
对于N个样本,我们可以把它们分为N-1个训练样本和一个测试样本,并重复相同的过程N次,使得每个样本都被用作测试样本一次。这种方法被称为“留一法”交叉验证(Tu et al.,2016)。尽管在严格意义上每次迭代中训练的分类器有所不同,但由于它们共享很多训练数据,所以可以预期它们是非常相似的。除了“留一法”之外,其他种类的交叉验证,例如“K折叠”[其中K是数据集被分割成的不同折叠的数量(例如,5折或者10折)]也已被广泛应用于脑电研空中。与“留一法”相比,“K折叠”交叉验证在计算上更有效,并且训练的分类器可能不会过度拟合。如下是十折交叉验证的示意图:
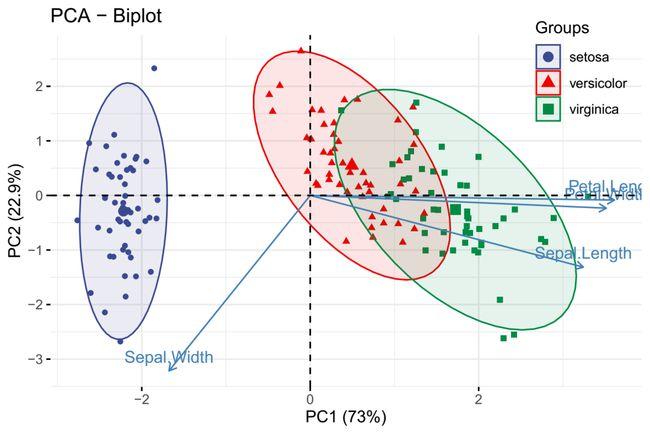
MATLAB函数”crossvalind“可以帮助我们生成N个样本的”K折叠“交叉验证的索引该索引包括相等的从1到K的整数,用来将原来的N个样本分成K个子数据集。更详细的介绍如下: load fisheriris indices = crossvalind('Kfold',species,10); cp = classperf(species); for i = 1:10 test = (indices == i); train = ~test; class = classify(meas(test,:),meas(train,:),species(train,:)); classperf(cp,class,test); end cp.ErrorRatematlab--交叉验证函数crossvalind_囊萤映雪的萤的博客-CSDN博客_crossvalind 为了通过训练建立更好的分类器,研究者需要考虑训练的效果,即分类器正确识别训练数据类别的能力以及泛化的效果,即分类器识别测试数据类别的能力。一个好的机器学习分类器应具有一个能够提供最好的泛化能力而不是完美的训练效果的决策边界。在某些情况下,分类器因为学习了数据中的噪声使得训练数据完美地被分类。我们将这些分类器学习了噪声或是随机误差而不是真实的数据与类标签之间关系的现象称为过度拟合。 四、机器学习分析的特征选择和降维脑电数据通常会跨越多个域具有极高数据维度,但样本量非常有限,机器学习在脑电研究中的效果往往会受到“维度诅咒”的影响(Mwangi et al.,2014)。例如,一个64通道的时频图(时域中有1000个样本,频率域中有100个样本)具有6400 000个特征(假设每一个时间-频率点为一个特征)。特征选择或降维对于从高维度脑电数据中识别一小部分判别特征,以获得更高的分类准确性和更好的分类器可解释性是至关重要的(Tu et al.,2015)。 特征选择或降维既可以使用类标签(称为“有监督学习方法”),也可以不使用类标签(称为“无监督学习方法”)。主成分分析是一种传统的降维方法,其沿着一个方向投影高维度数据。在这个方向上,数据的方差由少量潜变量在一个线性子空间内实现最大化(Jolliffe,2011)。从数学上看,主成分分析运用正交变换将一组相关变量的观测数据转换为一组称为主成分的线性不相关变量。通过省略数据中低方差的主成分,我们仅丢失少量信息。假设我们只保留L(L小于变量数)的主成分,这样新数据就只有L列,但是包含大部分数据信息。通常情况下,在脑电分析中主成分分析可以用于减少时间、频率、通道、试次和被试的维度,因为脑电数据的这些域中往往包含冗余信息(Hu et al.,2015 )。
在MATLAB中,我们可以用函数“pca”来实现主成分分析。代码如下。 clear all; close all; [coef, score, latent] - pca(X)对于一个n行、k列的矩阵X(X的每一行代表样本,每一列代表特征),这个函数的返回主成分系数为“coef ”、主成分评分为“score”(即X在主成分空间的表达),以及主成分方差为“latent”(X的协方差矩阵的特征值)。在“coef”中,每一列代表了一个主成分的系数,这些列按照主成分的方差降序排列。在“score” 中每一行代表了一 一个样本,而每一-列代表了一个主成分。 然而,无监督学习方法不利用类标签来减少维度,不能够保证类在低维度空间中被很好地区分。相比之下,有监督学习方法利用类标签来确保高维数据可以被映射到低位空间,且不同的类可以在这个空间中被很好地区分( Mwangietal, 2014)。 在这里,我们简要介绍三类有监督的特征选择方法。 最直接的方法是使用单变量统计技术的过滤类方法,包括t检验、方差分析和皮尔逊相关性。这些方法根据在区分类别之间差异中特征的关联性来对特征进行排序,通常对于高维度脑电数据表现不佳。包装类方法使用分类或回归目标函数根据模型中的分类权重对特征进行排序。递归特征消除是最流行的包装类特征选择方法( Gysels et al., 2005 )。它从训练集中的所有特征开始,迭代地消除特征,直到找到最佳数量的特征。嵌人类方法通过对机器学习模型实施某些“惩罚”来选择特征。例如,最小绝对值收敛和选择算子(或称为套索算法LASSO),通过在回归系数上加上增强稀疏性的L1正则化来最小化均方误差,把较小的回归系数缩小到零来实现特征选择( Tibshirani,1996 )。在处理强相关的特征的情况下(例如,相邻的脑电时间点), LASSO算法从--组强相关变量中任意选择-个变量,即降低了机器学习模型的可解释性。因此,弹性网( elastic net)算法被开发并运用在脑成像研究中。弹性网算法通过结合L1 正则化(强制稀疏性)和L2正则化(分组约束)来提高LASSO算法的效果( Zou & Hastie, 2005 )。 五、机器学习分析的选择分类器在准备完样本和选择信息量最大的特征之后,接下来是选择分类器(Lotte et al.,2007 )。学习特征和类标签之间的函数f的分类器分为判别模型和生成模型两种。判别模型的目标是通过设置参数来直接学习具有给定参数形式的预测函数。一个函数最简单的形式即是分类依赖于以下特征的线性组合: Xw=x1w1+x2w2+...+xkwk当Xw>0时,分类器判别为A类别;当Xw |


【本文地址】