| 【数据挖掘】第6章 关联分析: 基本概念和算法 | 您所在的位置:网站首页 › 聚类分析的目的是找出数据库中隐藏的关联网 › 【数据挖掘】第6章 关联分析: 基本概念和算法 |
【数据挖掘】第6章 关联分析: 基本概念和算法
|
6 关联分析: 基本概念和算法 目录 一、问题定义二、频繁项集的产生1)先验原理2)Apriori算法的频繁项集产生3)候选的产生与剪枝4)支持度计数5)计算复杂度 三、规则的产生 一、问题定义 关联分析 关联分析用于发现隐藏在大型数据集中的令人感兴趣的联系,所发现的模式通常用关联规则或频繁项集的形式表示。 关联分析可以应用于生物信息学、医疗诊断、网页挖掘、科学数据分析等 支持度计数( σ \sigma σ):包含特定项集的事务个数。 例如: σ \sigma σ ( M i l k , B r e a d , D i a p e r ) = 2 ({Milk, Bread,Diaper}) = 2 (Milk,Bread,Diaper)=2 支持度:包含项集的事务数与总事务数的比值。 例如: s ( M i l k , B r e a d , D i a p e r ) = 2 / 5 s({Milk, Bread, Diaper}) = 2/5 s(Milk,Bread,Diaper)=2/5 频繁项集:满足最小支持度阈值( minsup)的所有项集 关联规则 关联规则是形如 X → Y X → Y X→Y的蕴含表达式, 其中 X 和 Y 是不相交的项集 例子: M i l k , D i a p e r → B e e r {Milk, Diaper} → {Beer} Milk,Diaper→Beer 关联规则强度: 支持度:确定项集的频繁程度
s
(
X
→
Y
)
=
σ
(
X
⋃
Y
)
N
s(X→Y)=\frac{\sigma(X\bigcup Y)}{N}
s(X→Y)=Nσ(X⋃Y) 置信度:确定Y在包含X的事务中出现的频繁程度
c
(
X
→
Y
)
=
σ
(
X
⋃
Y
)
σ
(
X
)
c(X→Y)=\frac{\sigma(X\bigcup Y)}{\sigma(X)}
c(X→Y)=σ(X)σ(X⋃Y) 关联规则发现 关联规则发现: 给定事务的集合 T, 关联规则发现是指找出支持度大于等于 minsup并且置信度大于等于minconf的所有规则, minsup和minconf是对应的支持度和置信度阈值 关联规则发现的一种原始方法是:Brute-force approach: 计算每个可能规则的支持度和置信度这种方法计算代价过高,因为可以从数据集提取的规则的数量达指数级从包含d个项的数据集提取的可能规则的总数 R = 3 d − 2 d + 1 + 1 R=3^d-2^{d+1}+1 R=3d−2d+1+1,如果d等于6,则R=602挖掘关联规则的策略 大多数关联规则挖掘算法通常采用的一种策略是,将关联规则挖掘任务分解为如下两个主要的子任务: ①频繁项集产生(Frequent Itemset Generation) 其目标是发现满足最小支持度阈值的所有项集,这些项集称作频繁项集。 ②规则的产生(Rule Generation) 其目标是从上一步发现的频繁项集中提取所有高置信度的规则,这些规则称作强规则(strong rule)。 二、频繁项集的产生
降低产生频繁项集计算复杂度的方法: 减少候选项集的数量 (M) - 先验(apriori)原理减少比较的次数 (NM) 替代将每个候选项集与每个事务相匹配,可以使用更高级的数据结构,或存储候选项集或压缩数据集,来减少比较次数 1)先验原理
构造apriori-gen函数 候选项集的产生与剪枝(构造apriori-gen函数)包含2个步骤: 候选项集的产生:由频繁(k-1)-项集产生新的候选k-项集候选项集的剪枝:采用基于支持度的剪枝,删除一些候选k-项集
支持度计数过程确定在apriori-gen函数的候选项剪枝步骤保留下来的每个候选项集出现的频繁程度。 计算支持度的主要方法: 一种方法是将每个事务与所有的候选项集进行比较,并且更新包含在事务中的候选项集的支持度计数。这种方法是计算昂贵的,尤其当事务和候选项集的数目都很大时。另一种方法是枚举每个事务所包含的项集,并且利用它们更新对应的候选项集的支持度。
▪ 支持度阈值 降低支持度阈值通常将导致更多的项集是频繁的。计算复杂度增加 随着支持度阈值的降低,频繁项集的最大长度将增加,导致算法需要扫描数据集的次数也将增多 ▪ 项数 随着项数的增加,需要更多的空间来存储项的支持度计数。如果频繁项集的数目也随着数据项数增加而增长,则由于算法产生的候选项集更多,计算量和I/O开销将增加 ▪ 事务数 由于Apriori算法反复扫描数据集,因此它的运行时间随着事务数增加而增加 ▪ 事务的平均宽度 频繁项集的最大长度随事务平均宽度增加而增加 随着事务宽度的增加,事务中将包含更多的项集,这将增加支持度计数时Hash树的遍历次数 三、规则的产生忽略那些前件或后件为空的规则,每个频繁k-项集能够产生多达
2
k
−
2
2^k-2
2k−2个关联规则 关联规则的提取:将一个项集 Y划分成两个非空的子集 X 和Y-X,使得X → Y –X满足置信度阈值。 怎样有效的从频繁项集中产生关联规则? ▪ 一般,计算关联规则的置信度并不需要再次扫描事务数据集。规则{A,B,C} → {D}的置信度为σ(ABCD)/ σ(ABC)。 因为这两个项集的支持度计数已经在频繁项集产生时得到,因此不必再扫描整个数据集 ▪ 如果规则
X
→
Y
−
X
X → Y-X
X→Y−X不满足置信度阈值,则形如
X
’
→
Y
−
X
’
X’→ Y-X’
X’→Y−X’的规则一定也不满足置信度阈值,其中X’是X的子集。 bingo~ ✨ 无论天空如何阴霾,太阳一直都在,不在这里,就在那里。 |
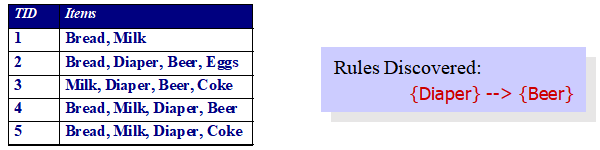 频繁项集 项集:包含0个或多个项的集合 例子: {Milk, Bread, Diaper}
频繁项集 项集:包含0个或多个项的集合 例子: {Milk, Bread, Diaper}
 暴力法→Brute-force 方法: 把格结构中每个项集作为候选项集 将每个候选项集和每个事务进行比较,确定每个候选项集的支持度计数。
暴力法→Brute-force 方法: 把格结构中每个项集作为候选项集 将每个候选项集和每个事务进行比较,确定每个候选项集的支持度计数。 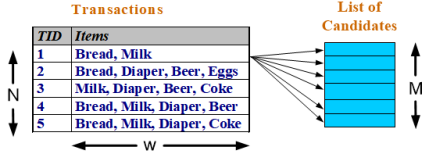 时间复杂度 ~ O(NMw),这种方法的开销可能非常大。
时间复杂度 ~ O(NMw),这种方法的开销可能非常大。 先验原理:如果一个项集是频繁的,则它的所有子集一定也是频繁的 相反,如果一个项集是非频繁的,则它的所有超集也一定是非频繁的:
先验原理:如果一个项集是频繁的,则它的所有子集一定也是频繁的 相反,如果一个项集是非频繁的,则它的所有超集也一定是非频繁的:







 存放在被访问的叶结点中的候选项集与事务进行比较,如果候选项集是该事务的子集,则增加它的支持度计数。 在该例子中 ,访问了9个叶子结点中的5个。 15个项集中的9个与事务进行比较
存放在被访问的叶结点中的候选项集与事务进行比较,如果候选项集是该事务的子集,则增加它的支持度计数。 在该例子中 ,访问了9个叶子结点中的5个。 15个项集中的9个与事务进行比较 这样的规则必然已经满足支持度阈值,因为它们是由频繁项集产生的。
这样的规则必然已经满足支持度阈值,因为它们是由频繁项集产生的。
【本文地址】