| SparkCore(一):Spark简介和运行环境的搭建 | 您所在的位置:网站首页 › 耐克旗舰店女款鞋 › SparkCore(一):Spark简介和运行环境的搭建 |
SparkCore(一):Spark简介和运行环境的搭建
|
文章目录
一、Spark简介1.1 Hadoop的发展1.2 Spark介绍1.3 Spark or Hadoop1.4 Spark 核心模块1.5 Spark快速上手
二、Spark运行环境2.1 Local模式2.2 Standalone模式2.3 Yarn模式【重点】2.4 K8S & Mesos模式2.5 常用三种运行环境对比
三、Spark运行架构3.1 运行架构3.2 核心组件3.3 核心概念3.4 提交流程
一、Spark简介
1.1 Hadoop的发展
Hadoop 1.x 从架构的角度Hadoop 1.X存在很多的问题 Namenode是单点操作,所以容易出现单点故障,制约了HDFS的发展;Namenode的内存限制也影响了HDFS的发展;MapReduce是一种基于数据集的工作模式,面向数据,这种工作模式一般是从存储上加载数据集,然后操作数据集,最后将结果写入物理存储设备。数据更多面临的是一次性计算,所以初衷是单一数据计算,不支持迭代计算;资源调度和任务调度耦合在一起,无法扩展,所以Hadoop1.X版本只支持MR计算框架。Hadoop 2.x 2.x版本支持Namenode高可用;2.x版本使用新的资源调度框架Yarn,只做资源调度,不进度;MR框架只做任务调度,可插拔,所以扩展性非常的强。 1.2 Spark介绍
Spark最初由美国加州伯克利大学的AMPLab于2009年使用Scala开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。 2013年6月,Spark成为了Apache基金会下的项目;同年Hadoop在2013年10月发布2.X (Yarn)版本。 1.3 Spark or HadoopHadoop的MR框架和Spark框架都是数据处理框架,那么我们在使用时如何选择呢? Hadoop MapReduce由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以Spark应运而生,Spark就是在传统的MapReduce计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型。机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。而Spark所基于的scala语言恰恰擅长函数的处理。Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比MapReduce丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。Spark和Hadoop的根本差异是多个作业之间的数据通信问题 : Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式。Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互Spark的缓存机制比HDFS的缓存机制高效。经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark确实会比MapReduce更有优势。但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致Job执行失败,此时MapReduce其实是一个更好的选择,所以Spark并不能完全替代MR。 1.4 Spark 核心模块
创建Maven项目并引入依赖: org.apache.spark spark-core_2.12 2.4.5 net.alchim31.maven scala-maven-plugin 3.2.2 testCompile org.apache.maven.plugins maven-assembly-plugin 3.0.0 jar-with-dependencies make-assembly package single代码如下: //1.准备Spark环境 val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount") //2.建立和Spark的连接 val sc = new SparkContext(sparkConf) //3.读取文件 val file: RDD[String] = sc.textFile("input") //4.根据行拆分 val words: RDD[String] = file.flatMap(line => line.split(" ")) //5.根据key分组 val wordCount: RDD[(String, Iterable[String])] = words.groupBy(word => word) //6.映射并排序 val result = wordCount.map(t => (t._1, t._2.size)).sortBy(t => t._2).collect() /** 6.7步可缩短为以下一步 */ //val result = words.map((_,1)).reduceByKey(_+_).sortBy(t => t._2).collect() //7.打印结果 result.foreach(t => print(t + " ")) //(World,1) (Test,2) (Scala,2) (Spark,4) (Hello,5) //8.关闭连接 sc.stop() 二、Spark运行环境Spark作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行,在国内工作中主流的环境为Yarn,不过逐渐容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下Spark的运行:
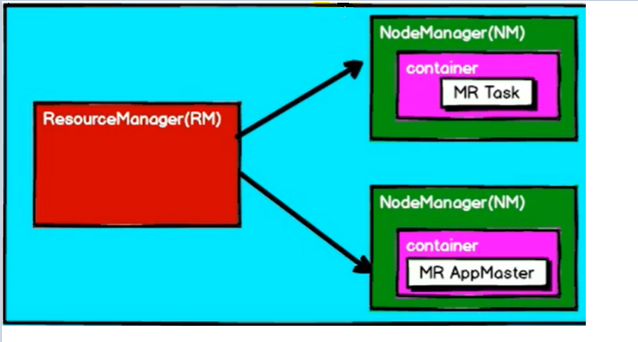
Local模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境,一般用于教学,调试,演示等。它可以通过以下集中方式设置Master。 local模式名称效果local运行在一个线程local[K]运行在K个线程local[*]CPU的最大核值来设置线程数搭建Local环境: ① 安装Spark [root@hadoop100 ~]# tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /opt/module/ [root@hadoop100 ~]# mv spark-2.4.5-bin-hadoop2.7 spark-2.4.5② 提交应用 [root@hadoop100 spark-2.4.5]# bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ ./examples/jars/spark-examples_2.11-2.4.5.jar \ 10参数说明: --class:表示要执行程序的主类--master local[2]:部署模式,默认为本地模式,数字表示分配的虚拟CPU核数量spark-examples_2.12-2.4.5.jar:运行的应用类所在的jar包10:表示程序的入口参数,用于设定当前应用的任务数量 2.2 Standalone模式Local本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用Spark自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark的Standalone模式体现了经典的master-slave模式。 搭建Standalone环境: ① 修改spark配置文件 [root@hadoop100 conf]# vim slaves hadoop100 hadoop101 hadoop102 [root@hadoop100 conf]# vim spark-env.sh SPARK_MASTER_HOST=hadoop100 SPARK_MASTER_PORT=7077② 分发spark包 [root@hadoop100 module]# xsync spark-2.1.1③启动spark集群 [root@hadoop100 spark-2.1.1]# sbin/start-all.sh④ 提交应用 [root@hadoop100 spark-2.1.1]# bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop100:7077 \ ./examples/jars/spark-examples_2.12-2.4.5.jar \ 10参数:--master spark://hadoop100:7077指定要连接的集群的master 2.3 Yarn模式【重点】Standalone模式由Spark自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是Spark主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以Yarn环境下使用Spark尤为重要。 ② 修改spark-env.sh,添加如下配置: [root@hadoop100 conf]$ vi spark-env.sh YARN_CONF_DIR=/opt/module/hadoo-2.7.2/etc/hadoop③ 分发配置文件 [root@hadoop100 conf]# xsync /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml④ 提交应用 [root@hadoop100 spark-2.1.1]# bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ ./examples/jars/spark-examples_2.12-2.4.5.jar \ 10注意:在提交任务之前需启动HDFS以及YARN集群 2.4 K8S & Mesos模式Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter得到广泛使用,管理着Twitter超过300000台服务器上的应用部署,但是在国内,依然使用着传统的Hadoop大数据框架,所以国内使用Mesos框架的并不多,但是原理其实都差不多,这里我们就不做过多讲解了。 Spark常用端口号: Spark查看当前Spark-shell运行任务情况端口号:4040(计算)Spark Master内部通信服务端口号:7077Standalone模式下,Spark Master Web端口号:8080(资源)Spark历史服务器端口号:18080Hadoop YARN任务运行情况查看端口号:8088 三、Spark运行架构 3.1 运行架构Spark框架的核心是一个计算引擎,整体来说,它采用了标准master-slave的结构。如下图所示,它展示了一个Spark执行时的基本结构。图形中的Driver表示master,负责管理整个集群中的作业任务调度。图形中的Executor则是slave,负责实际执行任务。 由上图可以看出,对于Spark框架有两个核心组件: Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责: 主要负责: 把用户程序转为作业(job)在Executor之间调度任务(task)跟踪Executor的执行情况通过UI展示查询运行情况实际上,我们无法准确地描述Driver的定义,因为在整个的编程过程中没有看到任何有关Driver的字眼。所以简单理解,所谓的Driver就是驱使整个应用运行起来的程序,也称之为Driver类。 ② Executor(执行器) Spark Executor是集群中工作节点(Worker)中的一个JVM进程,负责在Spark作业中运行具体任务(Task),任务彼此之间相互独立。Spark应用启动时,Executor节点被同时启动,并且始终伴随着整个Spark应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。 Executor有两个核心功能: 负责运行组成Spark应用的任务,并将结果返回给驱动器进程通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算ApplicationMaster Hadoop用户向YARN集群提交应用程序时,提交程序中应该包含ApplicationMaster,用于向资源调度器申请执行任务的资源容器Container,运行用户自己的程序任务job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。 说的简单点就是,ResourceManager(资源)和Driver(计算)之间的解耦合靠的就是ApplicationMaster。 3.3 核心概念① Executor与Core Spark Executor是集群中运行在工作节点(Worker)中的一个JVM进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点Executor的内存大小和使用的虚拟CPU核(Core)数量。 应用程序相关启动参数如下: 名称说明–num-executors配置Executor的数量–executor-memory配置每个Executor的内存大小–executor-cores配置每个Executor的虚拟CPU core数量② 并行度(Parallelism) 在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。 ③ 有向无环图(DAG) Spark计算引擎的特点主要是 Job内部的DAG支持(不跨越Job),以及实时计算。这里所谓的有向无环图,并不是真正意义的图形,而是由Spark程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。 3.4 提交流程所谓的提交流程,其实就是我们开发人员根据需求写的应用程序通过Spark客户端提交给Spark运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,我们这里不进行详细的比较,但是因为国内工作中,将Spark引用部署到Yarn环境中会更多一些,所以本课程中的提交流程是基于Yarn环境的。 ① Yarn Client模式 Client模式将用于监控和调度的Driver模块在客户端执行,而不是Yarn中,所以一般用于测试。 Driver在任务提交的本地机器上运行Driver启动后会和ResourceManager通讯申请启动ApplicationMasterResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,负责向ResourceManager申请Executor内存ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行② Yarn Cluster模式 Cluster模式将用于监控和调度的Driver模块启动在Yarn集群资源中执行。一般应用于实际生产环境。 在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是DriverDriver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行 |
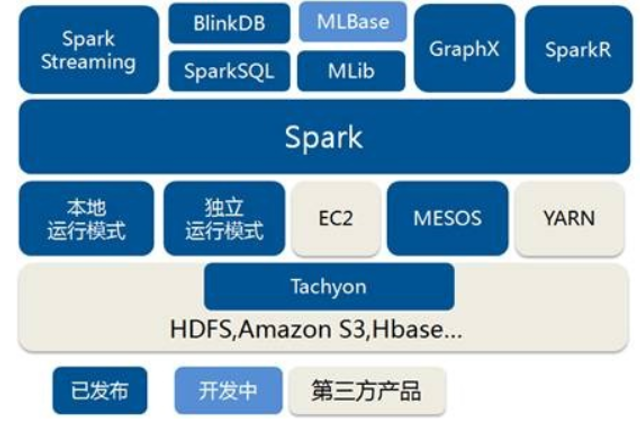
 Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
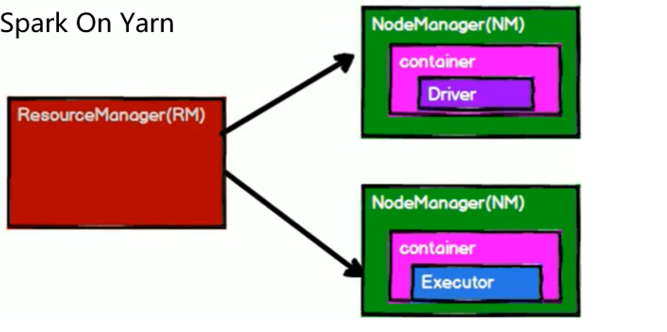 ① 修改hadoop配置文件yarn-site.xml,添加如下内容
① 修改hadoop配置文件yarn-site.xml,添加如下内容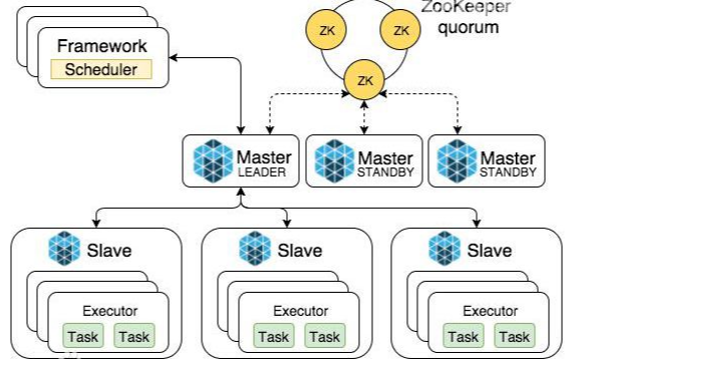 容器化部署是目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(K8S),而Spark也在最近的版本中支持了K8S部署模式。这里我们也不做过多的讲解,可以参考官网。
容器化部署是目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(K8S),而Spark也在最近的版本中支持了K8S部署模式。这里我们也不做过多的讲解,可以参考官网。 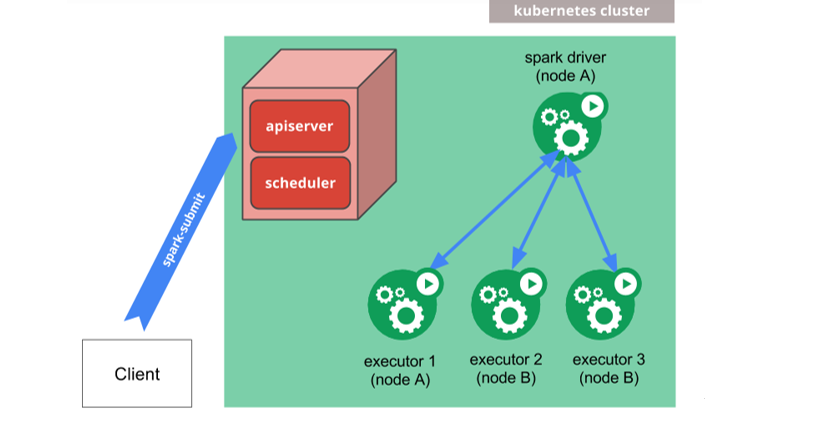
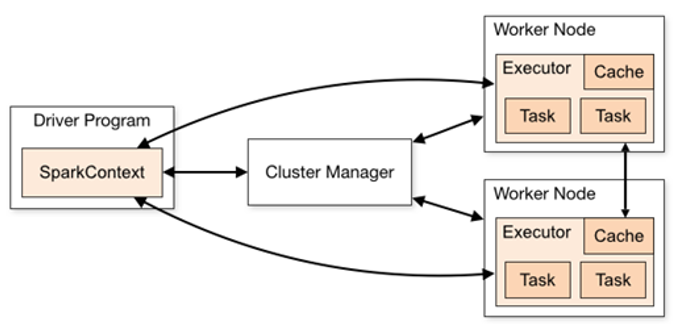
 ① Driver(驱动器)
① Driver(驱动器) DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。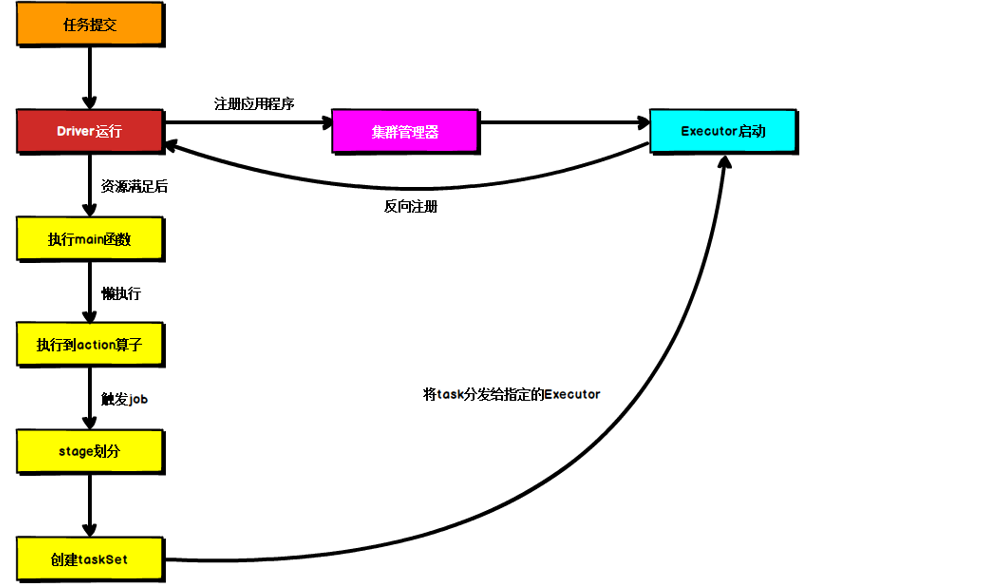 Spark应用程序提交到Yarn环境中执行的时候,一般会有两种部署执行的方式:Client和Cluster。两种模式主要区别在于:Driver程序的运行节点。
Spark应用程序提交到Yarn环境中执行的时候,一般会有两种部署执行的方式:Client和Cluster。两种模式主要区别在于:Driver程序的运行节点。【本文地址】