| 【论文阅读笔记】老照片修复 | 您所在的位置:网站首页 › 老照片如何翻新视频 › 【论文阅读笔记】老照片修复 |
【论文阅读笔记】老照片修复
|
目录 前言 一、问题与核心思想 二、核心工作 1.将X,R,Y映射到响应的潜在空间 2.训练映射网络 3.人脸增强网络 实践 前言笔记主要学习的是CVPR2020上发表的一篇Oral文章,主要思路是作者使用变分自动编码机(VAE)将图像变换到潜在空间(也称隐空间)中,在潜在空间中通过特征对齐和特征转换的方式来完成对老照片的图像修复。 这篇论文的方法不同于普通的潜在空间转换,他们通过利用真实照片和大量合成图像提出了一种新颖的三个图片域之间的图片翻译(triplet domain translation),也有人称为三联图像域翻译。该算法减少了老照片和合成图像之间的域间隙,并在潜在空间学习到高清图像的转换。 论文链接:https://arxiv.org/pdf/2009.07047.pdf 代码链接:GitHub - microsoft/Bringing-Old-Photos-Back-to-Life: Bringing Old Photo Back to Life (CVPR 2020 oral) 一、问题与核心思想在深度学习时代之前,有一些尝试,通过自动检测划痕、瑕疵等局部缺陷,用修复技术对受损区域进行填充来恢复照片。但这些方法都侧重于弥补缺失的内容,没有一种方法能够修复空间均匀的缺陷,如胶片颗粒、乌贼效应、颜色褪色等,所以修复后的照片与现代摄影图像相比仍然显得过时。 随着深度学习的出现,利用卷积神经网络强大的表示能力,即从大量合成图像中学习特定任务的映射,可以解决模糊、噪声、低分辨率等各种低级图像恢复问题。 但这样的框架并不能适用于老照片的修复,原因有三点: 老照片的退化过程复杂,并没有能完全渲染老照片伪影的退化模型。因此,从合成数据中学习到的模型对真实照片的泛化效果很差;老照片存在复合退化的问题,需要不同的修复策略:空间上同质的非结构化缺陷,如胶片颗粒和颜色褪色,应该利用附近的像素来修复,而结构化缺陷,如划痕、尘埃点等,应该用全局的图像上下文来修复,此前的大多数方法只考虑其中一方面。人们对面部周围的微小伪物很挑剔,但基于一般自然图像训练的网络无法捕捉面部的内在特征。因此,特别是考虑到人脸在老照片中所占比例较大,需要一个针对人脸修饰的网络。针对这些问题,本篇论文将对老照片的修复问题表示为一个三联域转换(triplet domain translation)的问题,三个图像域分别是: R:表示真实旧照片域;X:人工引入的经过退化处理的合成图片域(synthetic images suffer from artificial degradation);Y:和X对应的完好无损的真值域(可理解为X是由Y退化而来)。既然直接修复真实的老照片R十分困难,那么本论文中就另辟蹊径,采用一种弱监督方案。首先引入两个图像域X和Y,由于X与Y是退化-真实的图像对,所以训练X到Y的映射是可行的,如果能够让R也通过这样的映射得到高质量的Y图像域图像,那么是不是就完成了对R的修复呢? 而本文中为了是R能够适用X-Y的映射,使用的方法是——对齐X和R的潜在空间,通过缩小X与R之间的域间隙,从而使X≈R,从而使R也可以通过X-Y的映射关系进行修复。 为了解决老照片中复杂的混合退化问题,该团队设计了一个全局分支——其中包括一个部分非局部块(修复结构化缺陷);局部分支用以修复非结构化缺陷,在潜在空间中融合了两个分支,从而提高了从多个缺陷还原旧照片的能力。 此外,论文中提出了一种具有空间自适应条件的粗到细生成器,以重建旧照片的人脸区域,增强人脸面部的细节。
修复效果图 二、核心工作本论文的训练网络的分为两步 ——图像转换和人脸处理后步骤,其中论文将图像转换分为两部分,第一部分是将图像域映射到对应的潜在空间;第二部分是学习X-Y的映射关系,全局分支也包含字第二部分的工作中。 1.将X,R,Y映射到响应的潜在空间
三联域转换示意图 "因为合成图像和真实的旧照片都被破坏了,共享相似的外观,我们通过强制一些约束将它们的潜在空间对齐到共享域。所以我们有ZR≈ZX。这个对齐的潜在空间为所有损坏的图像编码特征,无论是合成的还是真实的。" 本论文使用了两个独立的VAE(变分自编码器)来得到对应的潜在空间,其中X和R共享VAE1,Y使用VAE2。此部分内容的重头戏是对齐X和R的潜在空间,这也是下文修复的前提。 本论文采用VAE,而不是香草自编码器,是因为VAE由于KL正则化(这将在消融研究中得到证明)而具有更密集的潜在表示,这有助于V AE1产生更紧密的R和X的潜在空间,从而导致更小的畴隙。
使用r作为输入训练的目标 三项分别是: KL散度,它惩罚了潜在分布与高斯先验的偏差;允许VAE重建输入,要求latent学到有助于重建输入的特征;最小二乘损失(LSGAN),用来解决变分自编码器的过渡平滑问题。使用x作为输入的目标与上文中的类似,只靠公式中的KL散度来缩小域间隙是不够的,所以这篇论文还使用了一个对抗网络来进一步缩小域间隙,具体方法为: 论文中先训练了一个鉴别器来区分X与R,又在VAE的总目标函数中引入一个相反的损失来欺骗这个鉴别器,从而确保X与R能够映射到同一个潜在空间。
VAE1的总目标函数 而VAE2只以Y作为输入,训练就要简单得多,至此论文将X、R、Y图像域都映射到了潜在空间中,并且完成了X与R潜在空间的对齐,接下来只要得到X与Y的映射关系,就能够让R搭上便车,成功修复。 2.训练映射网络
恢复网络结构 上图是这篇论文的网络结构,可以看出R是通过X-Y的映射而恢复到高质量图像域Y中的。 在潜在空间中进行修复有以下三点好处: X和R对齐到同一个潜在空间中,X-Y的映射也能很好的推广到对R的修复中;潜在空间是比较紧凑的低维向量空间,原则上比高维图像空间更容易训练;两个VAE(图中蓝色和紫色)是独立训练的,映射到Y的潜在空间后,通过生成器Gy能生成绝对“干净”的图像在这一阶段,只训练潜在映射网络T的参数,并固定两个VAEs。
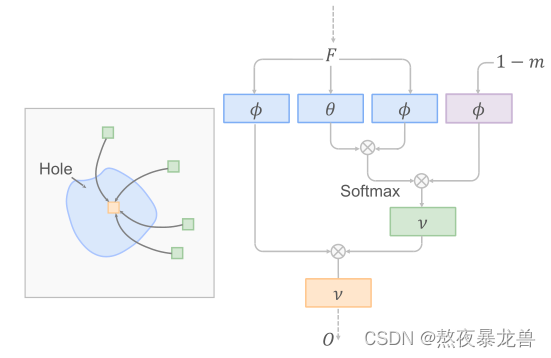
损失函数 第一项为潜在空间损失,惩罚对应的潜在空间编码;第二项为对抗性损失(LSGAN的形式),使得X-Y的转换更为真实;第三项为特征匹配损失,它比较的是真假样本对在判别器中间层和VGG中间层的差异(感知损失)如前所述,由于每一层的接收野有限,使用残差块的潜在空间恢复只能集中在局部特征上。 尽管如此,结构缺陷的修复需要合理的修复,这必须考虑长期依赖,以确保整体结构的一致性。由于老照片通常包含混合退化,作者认为必须设计一个同时支持这两种机制的恢复网络。 具体实现为Mapping T的部分,加入了一个全局分支,其中包括一个部分非局部块(partial nonlocal block)和两个残差块。 此部分的重点为用来修复划痕的部分非局部块(partial nonlocal block),它是由ECCV2018提出的nonlocal block改造而来:它的功能一句话简介就是借用完好区域(全局)的信息来修补损坏的区域(目标区域)。
部分非局部块结构示意图 设特征图的输入为F,尺寸为H*W*C, 为了区分完好区域和缺陷区域,作者引入了一个掩膜m作为指导,它是一个H*W的二值掩膜用来标记各个像素是否完好(0为完好,1为缺陷),这是针对结构性缺陷的部分,所以此处的缺陷只标记结构性缺陷。掩膜m通过一个划痕的数据集训练得出,可以自动标记缺陷的位置。 本文作者引入相似度的概念来表示完好部分对缺陷部分的贡献程度,具体实现为: 首先用
θ, ϕ 是嵌入高斯函数。这样得到的f是一个(HW)x(HW)的大型矩阵,它记录着任意两条像素的相似度。接着引入
在
μ, ν也是嵌入高斯函数。输出O和输入F的尺寸一样,是H*W*C。 最后进行区域融合,对损坏的区域用
式中两个ρ表示非线性激活函数。 至此修复网络的工作就做完了。 3.人脸增强网络上文中介绍的方法已经能够修复各种老照片,但作者认为照片中人脸所占比重很大,所以还需要加入进一步的人脸细节增强。由于退化先验完全未知,传统的像素平移方法不能很好地解决这种盲恢复问题。所以作者考虑从生成模型的角度来解决这个问题。 很明显,经典的像素级平移方法不能很好地解决这样一个盲目的修复问题,因为退化的先验是完全未知的。这里,我们从生成模型的角度来解决这个问题。本项目使用了一个粗到细的生成器[6],将低维代码z翻译成相应的高分辨率和干净的面孔,其中z是rf的一个下采样斑块(在我们的实现中为8×8)。在渐进式生成的同时,rf将被注入到每个尺度的生成器中,尽可能地捕捉退化脸的风格和结构信息。具体来说,让h∈RH×W×C是上一层的激活图,rif是当前规模i的条件。h将被调制如下:
其中hx,y,c表示h的每个元素,x∈H和y∈W跨越空间维度,c∈C是特征通道。µc和σc是通道c中激活的平均数和标准差,以避免离群值。 为了训练合适的人脸增强网络,我们惩罚生成的脸部之间的感知距离
中rf是rc的退化面,z是rf的潜伏代码的潜在代码。此外,另一个对抗性损失涉及到训练程序,以确保高频的综合细节:
脸部增强网络是与之前的修复网络共同训练的,以确保更好的泛化能力,即rf是三联域转换网络的输出。 作者发现这样的训练方案可以有效抑制了产生的伪影。 在推理时,我们首先搜索任意照片的人脸部分。然后用所提出的增强网络对这个区域进行细化。作为生成模型的结果,有时会出现重建的人脸和输入的退化的人脸之间存在颜色偏移。论文中通过直方图匹配来解决这个问题。最后,重建的人脸将与原始输入的照片用线性混合法结合,产生最终的结果。 实践“与最先进的方法的定性比较。结果表明,我们的方法可以恢复非结构化和结构化退化,恢复结果明显优于其他方法。”
与其他方法的对比 代码运行时会保存下每一个处理阶段,将自己的图片运行代码的效果:
左图为修复前,右图为修复后,放大来看确实修复效果不错。 代码中还能够单独跑划痕检测的部分,并将掩膜m可视化:
左图为我手动加入的划痕图片,右图为检测掩膜m的可视化 总的来说效果还是不错,其中的一些方法、代码可以应用于其他相关领域。 |


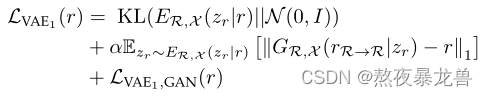
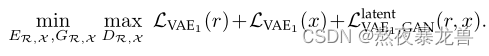


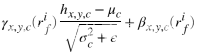
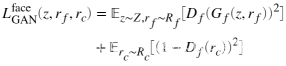





【本文地址】