| 【Stable Diffusion】 训练方法篇 | 您所在的位置:网站首页 › 美国人姓名格式三部分 › 【Stable Diffusion】 训练方法篇 |
【Stable Diffusion】 训练方法篇
|
一、四种模型训练方法简介 Stable Diffusion 有四种训练模型的方法:Textual Inversion、Hypernetwork、LoRA 和 Dreambooth 。它们的训练方法存在一定差异,我们可以通过下面对比来评估使用哪种训练方式最适合你的项目。 如果你知道模型中已经可以产生你想要的东西,例如,某种风格,或者已经 "在里面 "的特定名人,你可以使用这个模型,但是当你发现模型里面没有你要的人或者给严重错误标识了,那你就可以收集这种人物的样本图像,创建一个 Embedding训练,并使用对应关键字标识出来。 1、Textual InversionTextual Inversion(也称为 Embedding)是一种使用文本提示来训练模型的方法。它根据模型引用给定的图像并选择最匹配的图像。你做的迭代越多越好,能够在保持图像质量的同时,快速生成大量图像。这种方法对计算资源要求较低,适用于需要快速生成大量高质量图像的场景。 特点: 生成的模型文件小,大约几十KB通常适用于转换图像风格使用时不需要加载模型,只需要在提词中embeddings中的关键tag本地训练时对计算资源要求不高可以通过生成的PT文件覆盖在原有基础上继续训练模型关键字尽量是不常见的词语推荐训练人物训练时关键参数设定: learning_rate: 0.05:10, 0.02:20, 0.01:60, 0.005:200, 0.002:500, 0.001:3000, 0.0005number of vectors per token:按图片数量设置(图片数量小于10设置为2,10-30张设置范围2~3,40-60张设置范围5~6,60-100张设置范围8-12,大于100张设置范围12~16)max_train_steps: 3000(起步3000步)2、HypernetworkHypernetwork 是一种使用神经网络来生成模型参数的方法。它可以用来从模型内部找到更多相似的东西,使得生成为近似内容图像, 如果你想训练人脸或特定的风格,并且如果你想用Hypernetwork生成的 "一切 "看起来都像你的训练数据,那么Hypernetwork是一个不错的选择。你不能生成混合训练的图像,比如一组非常不同风格各异的猫。不过,你可以使用超网络进行绘画,将不同的训练数据纳入一个图像,改变图像的整个输出。 特点: 生成的模型文件比Embedding大,大约几十MB通常训练艺术风格推荐训练画风训练时关键参数设定: learning_rate: 0.000005:1000,0.0000025:10000,0.00000075:20000,0.0000005:30000,0.00000025:-1prompt template file: 对应风格类型文件可以编辑只留下一个 [fileword],[name] 在那里,删除多余的描述3、LoraLora【Low-Rank Adaptation of Large Language Models】的缩写,是一种使用少量图像来训练模型的方法。与 Dreambooth 不同,LoRA 训练速度更快:当 Dreambooth 需要大约二十分钟才能运行并产生几个 GB 的模型时,LoRA 只需八分钟就能完成训练,并产生约 5MB 的模型,推荐使用kohya_ss GUI 进行lora训练。 特点: 模型大小适中,8~140MB使用时只需要加载对应的lora模型,可以多个不同的(lora模型+权重)叠加使用可以进行lora模型其他模型的融合本地训练时需要显存适中,>=7GB推荐训练人物4、DreamboothDreambooth 是一种使用少量图像来训练模型的方法,是一种基于深度学习的图像风格转换技术。它可以将一张图片的风格应用到另一张图片上,以生成新的图像,Dreambooth 的一个优点是它可以生成高质量的艺术作品,而无需用户具备专业艺术技能。 特点: 模型文件很大,2-4GB适于训练人脸,宠物和物件使用时需要 加载模型可以进行模型融合,跟其他模型文件融合成新的模型本地训练时需要高显存,>=12GB推荐训练人物*画风训练时关键参数: 高学习率和过多的训练步骤将导致过度拟合(换句话说,无论提示如何,模型只能从训练数据生成图像)。低学习率和过少的步骤会导致学习不足,这是因为模型无法生成训练过的概念。物件:400步,2e-6人脸:1500步,1e-6或2e-6Training Steps Per Image (Epochs):(根据你图片的数量设定,大概值为你想训练的总步数/图片数量)Sanity Sample Prompt: 是否过度训练参数设定,我们可以加上一些特征从而去判断训练过程中是否出现过度拟合如填入 person of XX red hair (说明:XX替换为你的关键字,我们在这里加入了红头发的特征,如果出训练输出图像出现了非红头发此时我们就知道过度拟合了,训练过度了)二、VAE编解码器该如何应用1、VAE模型原理介绍VAE(Variational Auto-Encoder 变分自动编码器)模型有两部分,一个编码器和一个解码器。 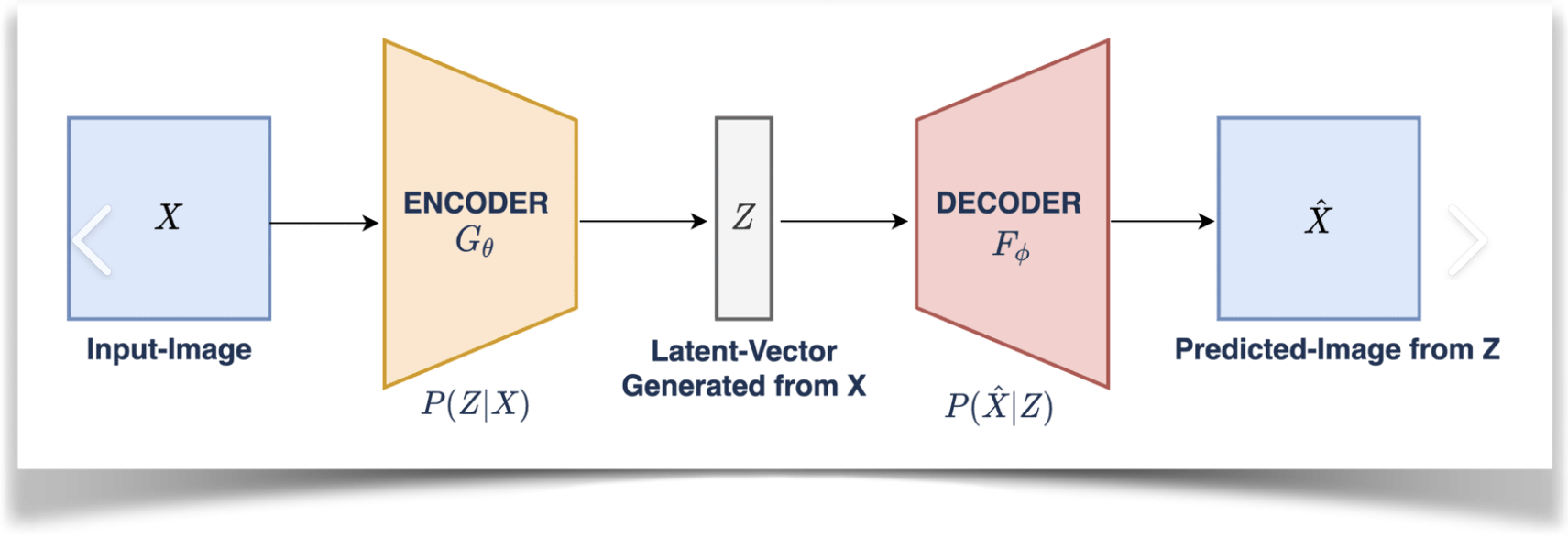 在潜在扩散模型(Latent Diffusion Models)组成中就有VAE模型的身影 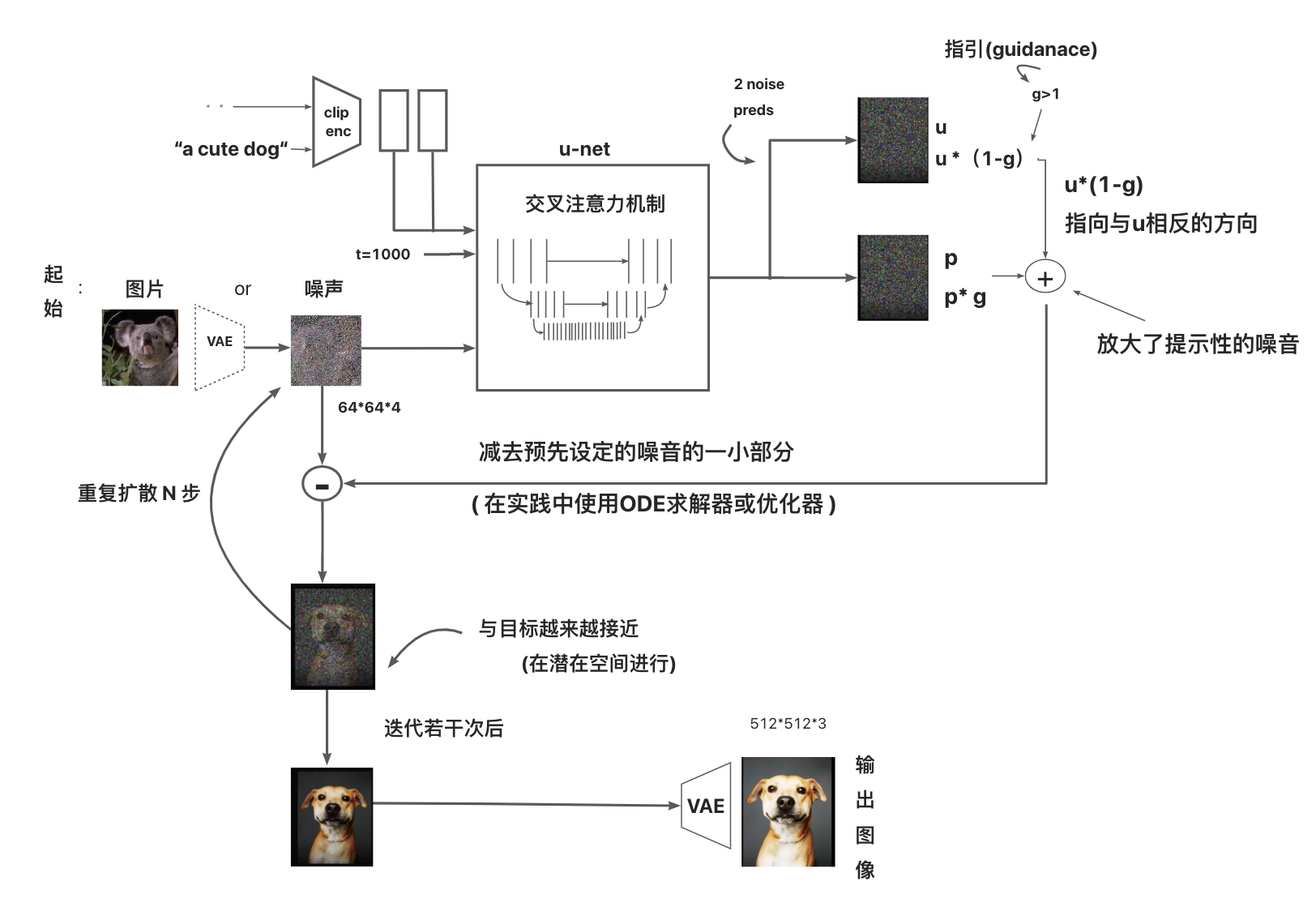 其中编码器(encoder)被用于把图片转换成低维度的潜在表征,转换完成后的潜在表征将作为U- Net 模型的输入 反之,解码器(decoder)将把潜在表征重新转回图片形式 在潜在扩散模型的训练过程中,编码器被用于取得图片训练集的潜在表征(latents),这些潜在表征被用于前向扩散过程(每一步都会往潜在表征中增加更多噪声) 在推理生成时,由反向扩散过程生成的 denoised latents 被VAE 的解码器部分转换回图像格式 所以说 ,在潜在扩散模型的推理生成过程中我们只需用到VAE的解码器部分 2、WebUI中的VAE那些比较流行预训练的模型一般都是内置了训练好的VAE模型的,不用我们再额外挂载也能做正常的推理生成(挂载后生成图像的效果会有一点点细微的区别),此时VAE pt文件的作用就像HDR,增加一点点图片色彩空间之类的一些自定义模型 可如果一些预训练模型文件不内置VAE(或训练他们自己的VAE,此时通常会在他们的模型发布说明中告诉你从哪得到他们的VAE)。我们就必须给它找一个VAE挂载上去,用来将推理时反向扩散最后生成的 denoised latents 转换回图像格式,否则webui里最后生成输出给我们的就是类似彩噪的潜在表征(latents),此时VAE pt文件的作用就像解压软件,为我们解压出肉眼友好可接受的图像  3、VAE模型文件获取 3、VAE模型文件获取社区在用的流行 VAE 文件: SD 官方VAE https://huggingface.co/stabilityai/sd-vae-ft-mse-originalNovelAI Leak的 animevae.ptWD 的 VAE https://huggingface.co/hakurei/waifu-diffusion-v1-4/tree/main/vae4、挂载使用VAE模型文件webUI中有两种挂载VAE模型文件的方法 改名为 .vae.pt 和 model 放一起将VAE文件 放到 VAE 文件夹然后在设置中选择 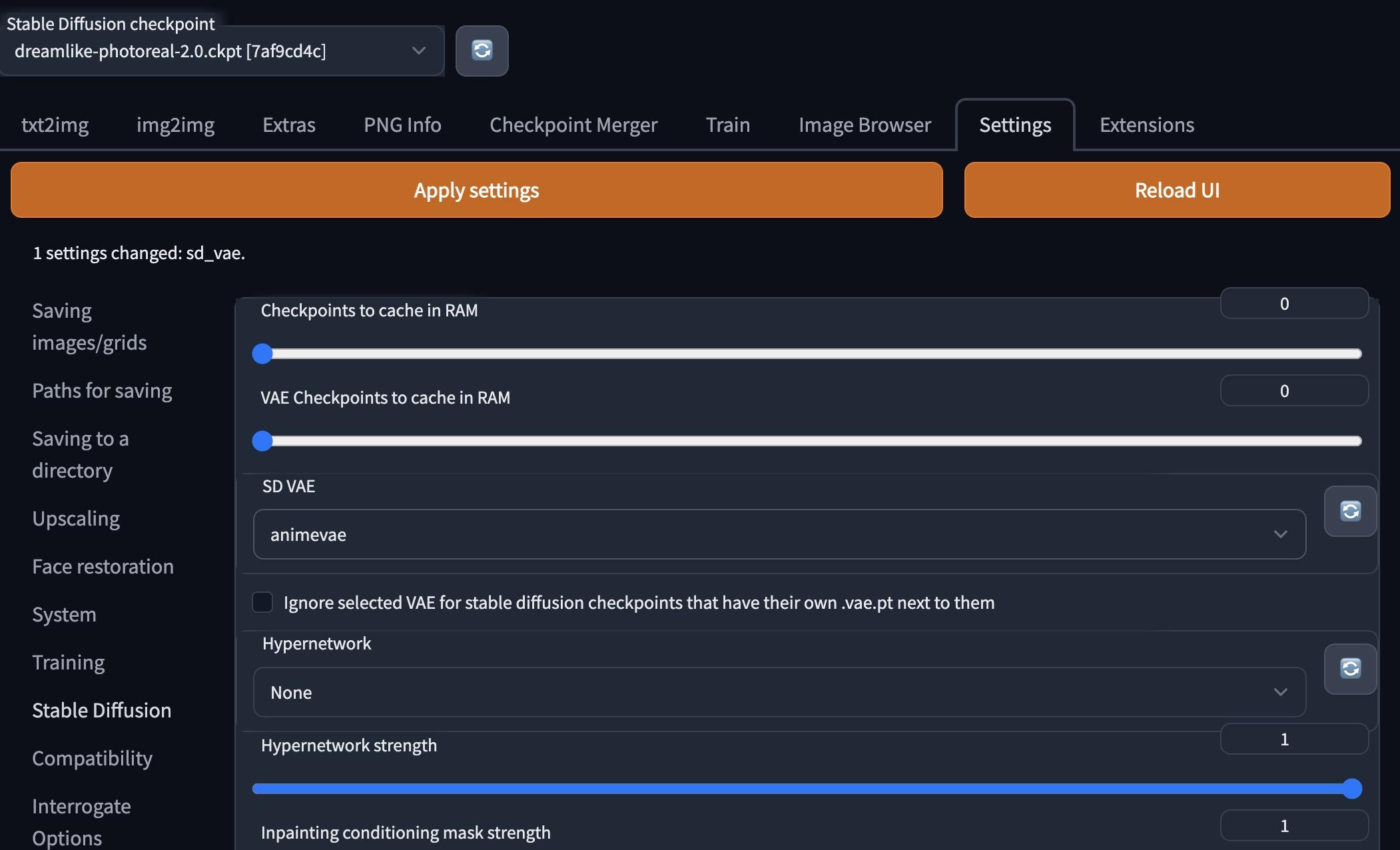 5、VAE文件在模型训练时一般要卸载 5、VAE文件在模型训练时一般要卸载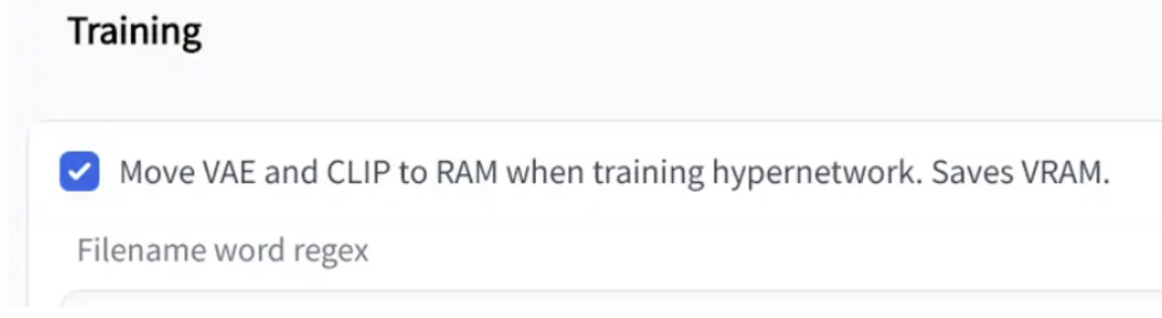 VAE在训练过程中自行学习,随着模型的训练,不同版本的模型实际表现可能会有所不同,如果有需求可以通过移除VAE文件的方式阻止VAE自行学习。 三、参考信息https://www.reddit.com/r/StableDiffusion/comments/xqi1t4/textual_inversion_versus_dreambooth/https://www.reddit.com/r/StableDiffusion/comments/z8w5z2/the_difference_between_dreambooth_models_and/https://www.reddit.com/r/StableDiffusion/comments/xjlv19/comparison_of_dreambooth_and_textual_inversion/https://wandb.ai/psuraj/dreambooth/reports/Dreambooth-training-analysis--VmlldzoyNzk0NDc3#textual-inversion-and-dreamboothhttps://ericri.medium.com/ai-arhttps://huggingface.co/blog/stable_diffusionhttps://zhuanlan.zhihu.com/p/610628741https://zhuanlan.zhihu.com/p/599129815 |
【本文地址】