| 说说百度搜索引擎的工作原理,搜索引擎页面抓取方式 | 您所在的位置:网站首页 › 网络蜘蛛的抓取 › 说说百度搜索引擎的工作原理,搜索引擎页面抓取方式 |
说说百度搜索引擎的工作原理,搜索引擎页面抓取方式
|
掌握百度抓取原理来做好搜索优化。在搜索引擎的后台,有一些用于搜集网页信息的程序。所收集的信息一般是能表明网站内容(包括网页本身、网页的URL地址、构成网页的代码以及进出网页的连接)的关键词或者短语。接着将这些信息的索引存放到数据库中。从输入关键词,到百度给出搜索结果的过程,往往仅需几毫秒即可完成。百度是如何在不可胜数的互联网资源中,以如此之快的速度将您的网站内容展现给用户?这背后蕴藏着什么样的工作流程和运算逻辑? 搜索引擎为用户展现的每一条搜索结果,都对应着互联网上的一个页面。每一条搜索结果从产生到被搜索引擎展现给用户,都需要经过四个过程:抓取、过滤、建立索引和输出结果。 1、抓取 Baiduspider,或称百度蜘蛛,会通过搜索引擎系统的计算,来决定对哪些网站施行抓取,以及抓取的内容和频率值。搜索引擎的计算过程会参考您的网站在历史中的表现,比如内容是否足够优质,是否存在对用户不友好的设置,是否存在过度的搜索引擎优化行为等等。 当您的网站产生新内容时,Baiduspider会通过互联网中某个指向该页面的链接进行访问和抓取,如果您没有设置任何外部链接指向网站中的新增内容,则Baiduspider是无法对其进行抓取的。对于已被抓取过的内容,搜索引擎会对抓取的页面进行记录,并依据这些页面对用户的重要程度安排不同频次的抓取更新工作。 需您要注意的是,有一些抓取软件,为了各种目的,会伪装成Baiduspider对您的网站进行抓取,这可能是不受控制的抓取行为,严重时会影响到网站的正常运作。点此识别Baiduspider的真伪。 2、过滤 互联网中并非所有的网页都对用户有意义,比如一些明显的欺骗用户的网页,死链接,空白内容页面等。这些网页对用户、站长和百度来说,都没有足够的价值,因此百度会自动对这些内容进行过滤,以避免为用户和您的网站带来不必要的麻烦。 3、建立索引 百度对抓取回来的内容会逐一进行标记和识别,并将这些标记进行储存为结构化的数据,比如网页的tagtitle、metadescripiton、网页外链及描述、抓取记录。同时,也会将网页中的关键词信息进行识别和储存,以便与用户搜索的内容进行匹配。 4、输出结果 用户输入的关键词,百度会对其进行一系列复杂的分析,并根据分析的结论在索引库中寻找与之最为匹配的一系列网页,按照用户输入的关键词所体现的需求强弱和网页的优劣进行打分,并按照最终的分数进行排列,展现给用户。 通过前面的介绍相信大家对搜索引擎的抓取原理及流程有了一个大致的了解。然而,在互联网这片浩瀚的信息汪洋中,搜索引擎又怎样保证快速、有效地抓取更多的相对重要的页面呢?这就需要我们接着来了解搜索引擎的抓取方式。 了解搜索引擎的抓取方式有利于我们建立对搜索引擎友好的网站结构,使搜索引擎蜘蛛能够在我们网站上停留的时间更久,抓取更多的网站页面(即收录数量),为网站关键词排名提供有力支撑。常见的搜索引擎抓取页面的方式有广度优先抓取、深度优先抓取、质量优先抓取、暗网抓取。 广度优先抓取 广度优先抓取是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后选择其中的一个链接?网页,继续抓取在此网页中链接的所有网页。这是最常用的蜘蛛抓取方式,该方法的优点是可以让网络蜘蛛并行处理,提高其抓取速度。 广度优先抓取是一种按层次横向抓取页面的方式,如图所示,它会从首页开始抓取页面,直至该层页面被抓取完才会进入下一层。所以,当我们在做网站优化的时候,不妨将一些相对重要的信息或栏目在首页优先展示出来(如热门产品、资讯内容等),让搜索引擎优先抓取到网站较为重要的信息。 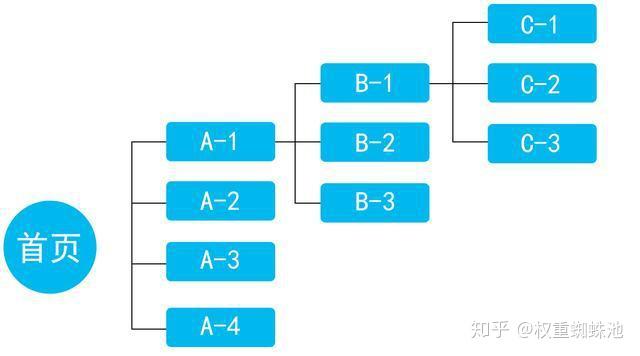 广度优先抓取 深度优先抓取 深度优先抓取是指网络蜘蛛会从起始页开始,一个连接一个链接跟踪下去,处理完这条线路。 质量优先抓取 质量优先抓取般是针对大型网站, 比如新浪、网易、阿里巴巴等类型的网站, 由于它们的信息量庞大,而且本身权重比较高,相对来说更容易为用户提供更有价值的信息。正因如此,搜索引擎会更愿意优先抓取大型网站中的网页,以保障其可以在最短的时间内为用户提供更有价值的信息。 搜索引擎整理高质量的网站一般分为两种方式:前期的人工整理大量种子网站,进而由种子资源出发去发现更多大型网站资源;对已经索引的网站进行系统分析,从而识别哪些内容丰富、规模较大、信息更新频繁的网站。 暗网抓取 所谓暗网(又称深网、不可见网或隐藏网),是指目前搜索引擎爬虫按照常规方式很难抓取到的互联网页面。搜索引擎爬虫必须依赖页面中的链接关系发现新的页面,但是很多网站的内容是以数据库方式存储的,典型的例子是一些垂直领域网站,如携程旅行网的机票数据,很难使用显式链接指向数据库内的所有机票记录,往往是服务网站提供组合查询界面,只有用户按照需求输入查询之后,才能够获得相关数据。所以,常规的爬虫无法索引这些数据内容,这是暗网的命名由来。 为了能够对暗网数据进行索引,需要研发与常规爬虫机制不同的系统,这类爬虫被称作暗网爬虫。暗网爬虫的目的是将暗网数据从数据库中挖掘出来,并将其加入搜索引擎的索引,这样用户在搜索时更可利用这些数据增加信息覆盖程度。 |
【本文地址】