| 【从零开始的ML | 您所在的位置:网站首页 › 缩小名义变量 › 【从零开始的ML |
【从零开始的ML
|
数据的标准化
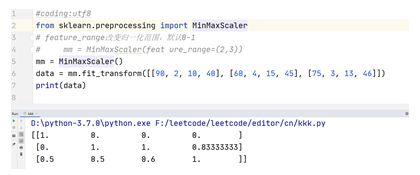
是将数据按比例缩放,使之落入一个小的特定区间,在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权 常见的标准化类型: 标准差标准化:经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为: 其中μ为所有样本数据的均值,σ为所有样本数据的标准差。 线性标准化(也叫离差标准化):对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下: 其中max(x)为样本数据的最大值,min(x)为样本数据的最小值。这种归一化方法比较适用在数值比较集中的情况。 这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,当有新数据加入时,可能导致max和min的变化,需要重新定义。实际使用中可以用经验常量来替代max和min。 标准化后的好处: 1. 提升模型的收敛速度,即梯度下降迭代速度。
如图所示,X1的值为0-2000,X2的值为1-5,如果对这两个特征进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字路线,右图的迭代速度很快(不管步长是走多还是走少,不会走偏) 2. 可以取消量纲的影响,使回归系数可以做比较假设因变量为y,自变量为x,标准回归系数为a。那么在解释时就要说,当x变化1个标准差是,y变化a个标准差。 标准化后的回归系数在不同自变量之间是可比的,没有标准化之前是不可比的。 举一个例子: 假设因变量是一个人的外貌给人的印象(y),自变量有身高(x1)、体重(x2) 假如未标准化的回归系数分别为a1、a2。在解释时就要说,在体重不变的前提下,当身高增加1厘米时,y增加a1个单位;在身高不变的前提下,体重(x2)增加1千克,y就增加a2个单位。假设a1>a2,那我们能说身高对一个人的外貌比体重更重要吗?这是不能的,因为身高的1厘米和体重的一厘米对于他们自身来说重要的程度是不一样的。 必须用标准化的回归系数才能比较,因为那时都是身高或体重增加一个标准差,外貌打分增加多少。这时,身高跟体重都增加了一个标准差,这对于他们自身的重要程度是一样的。 3. 提升模型的精度在涉及到一些距离计算的算法时效果显著例如KNN,比如算法需要计算欧氏距离上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。 在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。 可以理解为:雨露均沾,防止突出个别特征的作用(类似比赛中的多评委打分制度,一个评委打分可能会出现偏心的现象从而导致比赛不公正,而多评委打分可以使比赛更公平) 4. 深度学习中数据归一化可以防止模型梯度爆炸。 sklearn应用:① 线性标准化: ② 标准差标准化:
|
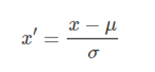
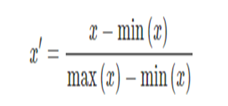


【本文地址】