| 编码和解码 | 您所在的位置:网站首页 › 编码、解码 › 编码和解码 |
编码和解码
|
概念
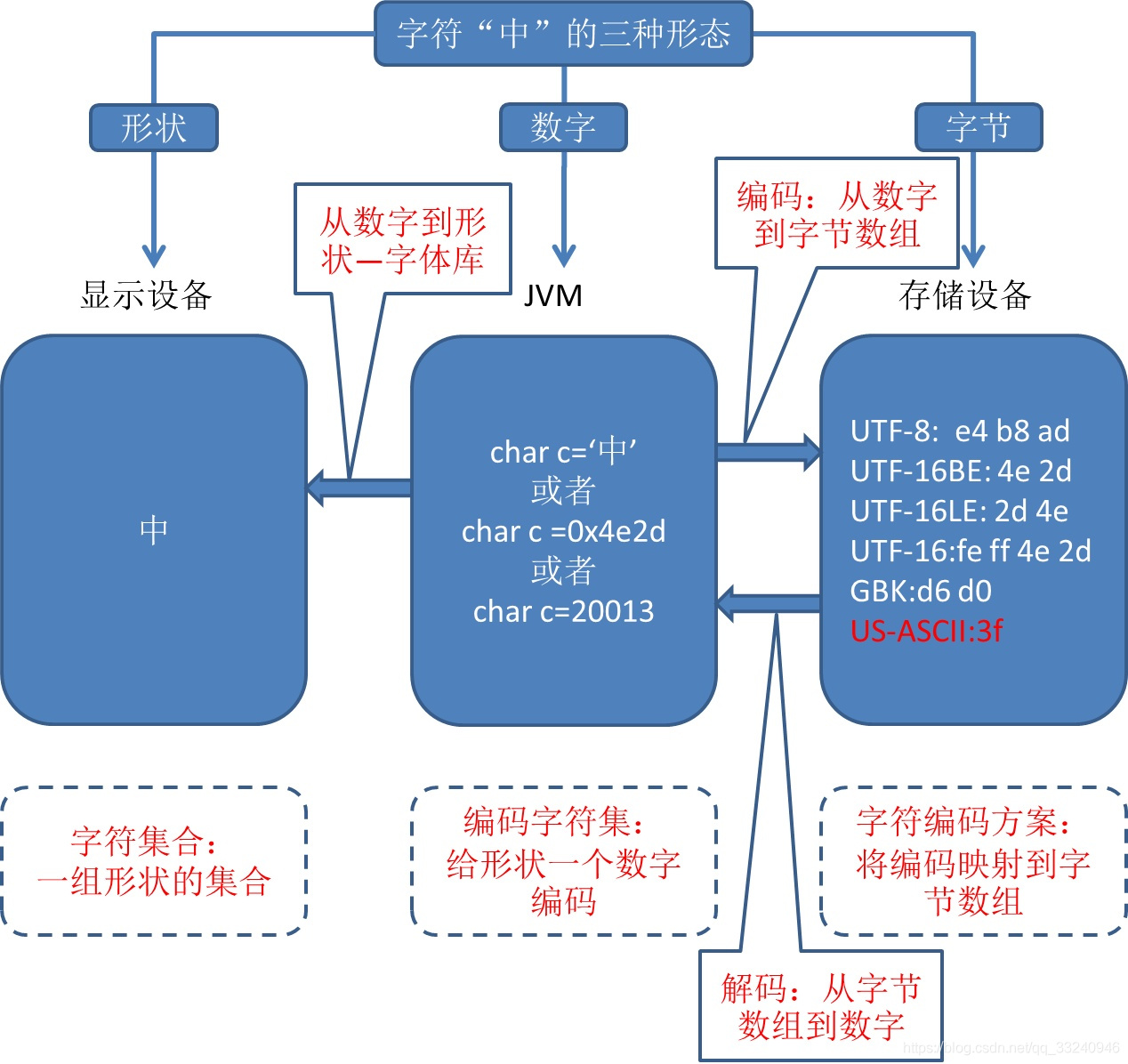
字符的三种形态 图片来自:https://zhuanlan.zhihu.com/p/25435644 编码:将字符转为字节序列(abcdefg-------------> 0101010…10010) 解码:将字节序列转为字符(1001010…10010110------> abcdefg) 各种编码 ASCII编码计算机,它只认识0和1,也就是高低电平。于是想让计算机识别我们人类的语言,也就是字符,则需要一个对应关系。由于计算机在美国诞生,于是美国给了一个对应关系表,称为ASCII编码 各个国家为了使用计算机,也需要本国的语言符号被计算机识别,于是各种编码层出不穷:中国有GBK,日本有EUC-JP,韩国有EUC-KR,甚至一个国家也不只有一种编码,比如中国繁体还有big5等等。总之就是,每个国家为了让计算机认识自己国家的文字,都出了许多对应的编码。 统一编码每个国家都制定了自己的编码,每个网站都可以在自己的国家运行良好。但互联网是让全世界连成了一体,当本国发出的信息走向国际时,多语言环境让每一种编码都措手不及。于是出现了unicode编码。 Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。 Unicode伴随着通用字符集的标准而发展,同时也以《The Unicode Standard》书本的形式对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。当前最新的版本为2019年3月5日公布的12.0.0[2],已经收录超过13万个字符(第十万个字符在2005年获采纳)。Unicode涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。 ——维基百科 说白了,unicode编码就是收录了全世界的所有字符,统一进行编码。也就是给每一个形状赋予一个数字,这是它的编码方式,但是怎么实现的呢? Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的(也就是说,字符对应的数字是确定的)。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同(也就是说,这个数字用几个字节来存有所不同)。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。比如UTF-8、UTF-16等。可以简单理解,unicode是一个字符集,utf8等是这个字符集的不同编码规则实现。 从mysql中读取数据的编解码历程这个是个简单的场景:中间的服务器中跑了一个javaweb项目,他把mysql中的数据拿出来,然后交给前端展示。 首先数据库中已经有了数据,比如我们存了一句话“i am tian 峰”。mysql中的数据说到底还是一种特殊文件,并且是以二进制补码的形式存在磁盘上。换句话说,就是一串有规律的0101。当我们向数据库发起查询请求之后,mysql首先得将需要查的这串0101读取出来,然后进行编码转换(有一个参数叫character_set_results指明了返回数据的编码),再发送给java后台,我们收到这串0101之后,将它转发给前端浏览器,浏览器采用指定的编码进行解码,得到对应的数字,然后对照字符集合,将字符图形展示出来。 说一个下这个简单项目的各个编码参数: 平台:windows(默认编码GBK)mysql:utf-8浏览器页面:utf-8当我们通过jdbc完成查询,得到ResultSet之后就可以进行数据的处理了。此时ResultSet中的数据不只有数据,还有此数据的编码类型。我们就可以进行数据的处理了。
|

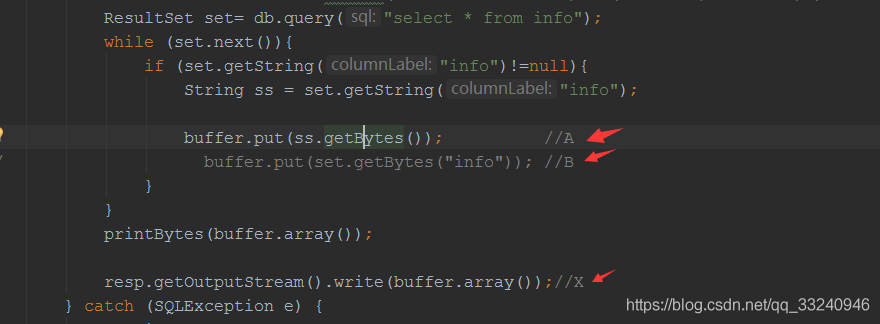 图中我标出了三个箭头,分别指向A、B、X三行。先说一下结果:如果我们注释掉A行,使用B和X,那么浏览器将正常显示中文字符;如果注释掉B行,使用A和X,那么浏览器将出现乱码。X行就是将buffer中的字节数组返回给http客户端(浏览器),A行是将字符串ss转换为自己数组放入buffer中,ss是从set中get到的。get的过程就是一个解码的过程,set中本来是mysql返回的经过utf-8编码得到的字节数组,ss就是通过解码得到的对应字符串。这里解码时使用的编码是resultSet指定的,也就是mysql服务端指定的,于是可以很顺畅的得到一个正常的字符串。但是A行又要将这个字符串进行编码,得到字节数据,这里采用的编码还是服务端指定的吗?可惜不是了,他会采用平台默认的编码,就是GBK。对与中文来说,GBK存储中文使用两个字节,而UTF-8使用三个。但是也没啥,不过就是采用新的编码,由UTF-8转到了GBK,但是不巧的是,上边说了,浏览器使用的是utf-8。当浏览器采用utf-8去解码gbk编码产生的字节数时,发现自己并不认识这个字节序列。于是出现了乱码,但此时,只要我们将浏览器页面编码改为gbk(html页面中可以设置字符编码),立刻就恢复了正常。
图中我标出了三个箭头,分别指向A、B、X三行。先说一下结果:如果我们注释掉A行,使用B和X,那么浏览器将正常显示中文字符;如果注释掉B行,使用A和X,那么浏览器将出现乱码。X行就是将buffer中的字节数组返回给http客户端(浏览器),A行是将字符串ss转换为自己数组放入buffer中,ss是从set中get到的。get的过程就是一个解码的过程,set中本来是mysql返回的经过utf-8编码得到的字节数组,ss就是通过解码得到的对应字符串。这里解码时使用的编码是resultSet指定的,也就是mysql服务端指定的,于是可以很顺畅的得到一个正常的字符串。但是A行又要将这个字符串进行编码,得到字节数据,这里采用的编码还是服务端指定的吗?可惜不是了,他会采用平台默认的编码,就是GBK。对与中文来说,GBK存储中文使用两个字节,而UTF-8使用三个。但是也没啥,不过就是采用新的编码,由UTF-8转到了GBK,但是不巧的是,上边说了,浏览器使用的是utf-8。当浏览器采用utf-8去解码gbk编码产生的字节数时,发现自己并不认识这个字节序列。于是出现了乱码,但此时,只要我们将浏览器页面编码改为gbk(html页面中可以设置字符编码),立刻就恢复了正常。【本文地址】