| 皮尔逊相关系数统计指南 | 您所在的位置:网站首页 › 统计学中t值和p值如何计算 › 皮尔逊相关系数统计指南 |
皮尔逊相关系数统计指南
|
通过我们的皮尔逊相关系数统计指南,您将了解解释 r 值的复杂性及其对数据相关分析的深远影响。 介绍统计分析的核心在于 皮尔逊相关系数 (r) — 用于量化两个连续变量之间线性关系的强度和方向的基本工具。 无论是在科学研究、数据科学还是经济预测中,皮尔逊相关系数都是一个关键的衡量标准,可以洞察两个变量一致变化的程度。 “r”不仅仅是一个数学抽象,它反映了数据集之间微妙的相互作用,指导分析师揭示复杂数据结构结构中的潜在模式。 本统计指南将剖析皮尔逊相关系数,阐明其计算、解释以及支持其使用的关键假设。 亮点 Pearson r 量化了从 +1 到 -1 范围内的变量之间的线性关系。 r 值越接近 +1 或 -1 表明数据集中的线性关联越强。 皮尔逊相关系数不受不同测量单位的影响。 线性和同方差的假设对于 Pearson r 的有效性至关重要。 Pearson's r 并不表示因果关系,仅表示线性相关的程度。 广告广告描述。 Lorem ipsum dolor sat amet,consectetur adipiscing elit。 了解更多 了解皮尔逊相关系数 (r)我们推荐使用 皮尔逊相关系数 (r) 是衡量两个变量之间线性关系程度的统计标准。该系数提供了从 -1 到 +1 范围内的数值摘要,其中每个端点代表完美的线性关系,无论是负的还是正的。 “r”值为 0 表示变量之间不存在线性相关性。它反映了一个变量可以通过线性方程预测另一个变量的程度。在实践中,“r”的值指导分析师确定关系的可预测性和强度,为进一步的统计建模和推理提供基础。 对于依赖数据分析来做出明智决策的领域(从医疗保健研究到财务预测),理解“r”至关重要。其计算涉及将变量之间共享的方差与其方差的乘积进行比较,从而概括了它们同步波动的本质。 视觉辅助举个例子,考虑一个检查学习时间和考试成绩之间关系的数据集。我们预计会看到正相关;随着学习时间的增加,考试成绩也会增加。这将被描述为散点图上向上点的集合。 相反,假设我们要查看休闲活动所花费的小时数和考试成绩。在这种情况下,我们可能会发现负相关,表现为下降趋势。 在没有相关性的场景中,例如鞋码和考试分数之间的关系,这些点不会显示出可辨别的模式或方向。 下面是这些场景的直观表示: 正相关:随着一个变量的增加,另一个变量也会增加。 负相关性:当一个变量增加时,另一个变量减少。 没有相关性:变量之间的关系没有明显的线性模式。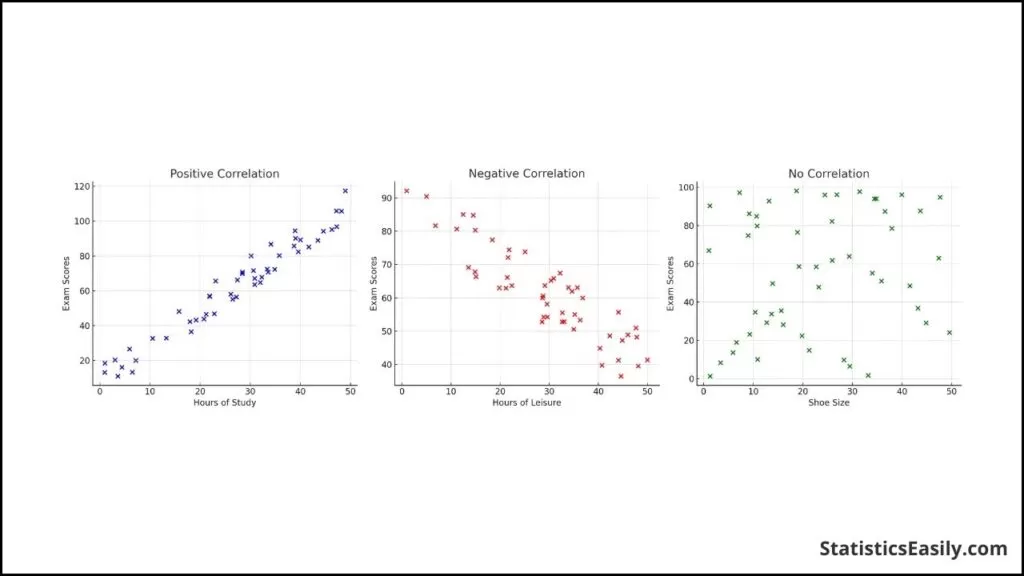
该图是初步分析中的强大工具,可以快速评估值得使用更复杂的统计技术进行研究的潜在关系。 值的范围及其含义皮尔逊相关系数 (r) 封装了两个变量之间线性关系的强度和方向,其值始终位于 -1 和 +1 之间。该范围的两端表示完美相关性:+1 表示完美的正线性相关性,其中变量精确地串联移动,而 -1 表示完美的负线性相关性,一个变量增加而另一个变量减少。 “r”值为 0 表示不存在线性相关性;变量不显示线性相关性。 这个范围对于理解变量之间的动态至关重要。例如,接近+1的“r”值表明一个变量的增加可能会伴随着另一个变量类似程度的增加。相反,接近 -1 的“r”值表示其中一个的增加通常与另一个的减少相关。该值越接近 0,线性关系越弱,表示一个变量的变化不能可靠地预测另一个变量的变化。 决定系数 (r²)理解“r”后,决定系数(表示为“r²”)就成为一个重要的度量。它表示“r”的平方值。它表示可从自变量预测的因变量方差的比例。本质上,“r²”为我们提供了一个变量解释另一个变量的百分比。 例如,如果“r”为 0.8,则将其平方得到“r²”,结果为 0.64。这意味着另一个变量的方差占一个变量方差的 64%。这是量化两个变量创建的线性模型的预测能力的有效方法。当“r²”较高时,模型基于线性关系的预测可能会更准确。 图形表示说明了这种关系,说明了“r”值如何与解释的方差相关。这可以直观地理解“r²”如何作为相关强度的决定因素。  关联强度:解释“r”值
关联强度:解释“r”值
两个变量之间的关联强度(如皮尔逊相关系数“r”所示)衡量数据点符合线性模式的程度。在解释“r”值时,通常使用几个阈值来定性描述关系的强度: 完美的:“r”值为 -1 或 +1 表示数据点恰好位于一条线上;换句话说,这两个变量是完美的线性关联。 强大:“r”值接近 -1 或 +1(但不完美)表明存在很强的线性关系,与直线的偏差很小。 中等:“r”值远离极端(大约 -0.5 到 0.5)表示更温和的线性关联。 弱或无:当“r”接近0时,表明线性关联较弱或非线性;这些变量似乎没有线性关系。随附的图形表示将“r”值映射到色谱,其中极值(红色表示负值,蓝色表示正值)表示较强的关联,中点(白色)表示没有关联。 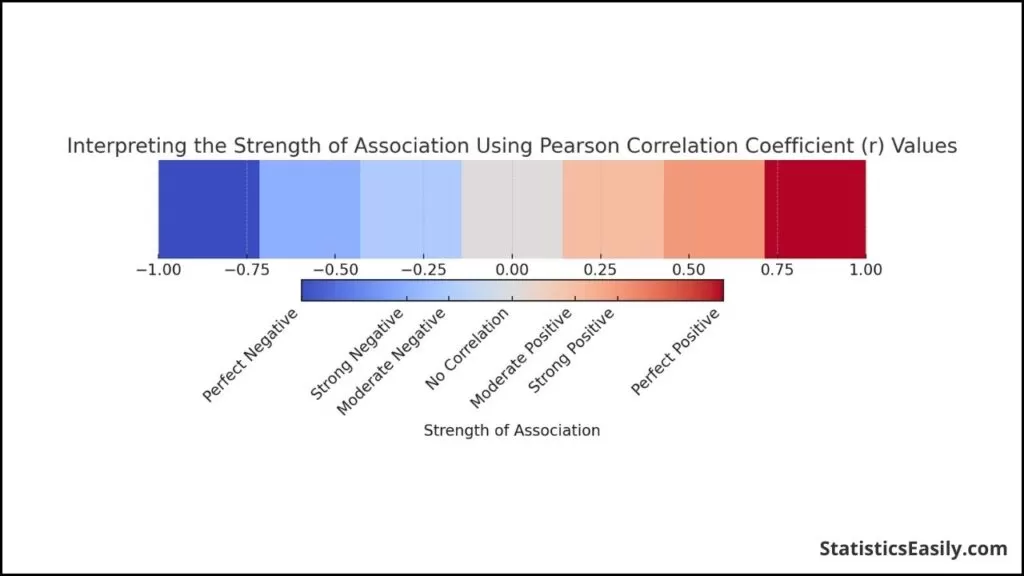 适用于 Pearson r 的变量类型
适用于 Pearson r 的变量类型
皮尔逊相关系数旨在衡量两个连续且在区间或比率范围内的变量之间的线性关系。连续变量可以在给定范围内取无限值,例如温度、身高、体重或测试分数。 区间变量 是数值,其中值之间的顺序和精确差异有意义,例如摄氏度或华氏度的温度。 比率变量:它们具有区间变量的所有属性和零的明确定义。示例包括以公斤为单位的体重或以年为单位的年龄。 不适合 Pearson r 的变量包括:| 名义变量:这些是没有数值或顺序的分类数据,例如性别、种族或是否存在某种状况。 序数变量:虽然它们涉及顺序,但值之间的间隔并不统一或已知。一个示例是李克特量表(例如,1 到5 的评级)。 必须确保数据不违反 Pearson 相关性的假设,例如线性假设、异常值的存在和同方差(沿最佳拟合线的方差相等)。 单位测量及其与“r”的无关性皮尔逊相关系数“r”是无量纲度量。这意味着它不依赖于所涉及变量的测量单位。相反,它量化两个变量之间线性关系的强度和方向。因此,无论您以米或厘米、千克或克为单位测量这些变量,都不会影响“r”的值。 例如,如果您有两个变量,变量 X 以米为单位测量,变量 Y 以千克为单位测量,并且您计算“r”,则您将获得与以厘米为单位测量变量 X 和以克为单位测量变量 Y 相同的值。这是因为“r”的公式通过变量的标准差对变量进行标准化,从而有效地从方程中删除了单位。 在我们的示例中,以米和千克为单位的变量的“r”计算得出的相关性约为 -0.0661。当我们将这些变量转换为厘米和克并重新计算“r”时,我们获得了大约 -0.0661 的相同相关值。这表明单位与皮尔逊相关系数无关,从而确保无论用于测量的尺度如何,关联测量都保持一致。 此属性在研究和分析中特别有用,允许直接比较可能使用不同测量单位的研究的结果。它还简化了相关性的解释,重点关注关系本身而不是具体的变化幅度。  自变量和因变量:“r”的公正性
自变量和因变量:“r”的公正性
“r”的一个显着特征是其将变量分类为因变量或独立变量的公正性。 计算“r”时,重点是线性关联的方向和强度,而不是哪些变量是原因或结果。这种公正性使得“r”成为适用于各种环境的稳健指标,无论所涉及变量的性质如何。 “r”在行动中的中立性为了说明这一点,让我们考虑一项研究,检验化肥用量(以千克为单位)与作物产量(以吨为单位)之间的关系。假设我们将肥料用量指定为自变量,将作物产量指定为因变量并计算“r”。在这种情况下,我们获得反映该线性关联强度的值。 有趣的是,如果我们颠倒变量的角色,将作物产量视为独立因素,将肥料用量视为依赖因素,“r”的值保持不变。这说明“r”不受变量的函数依赖性的影响;它只是量化它们之间的线性关系。 为了形象化这种公正性,请考虑下图: 
在图中,两个散点图表示与交换的变量具有相同的线性关系。在这两个图中,最佳拟合线是相同的,并且“r”的计算值是相同的。这作为一个视觉提醒,无论哪个自变量或因变量,“r”都提供了线性关系的一致度量。 皮尔逊相关性背后的假设皮尔逊相关系数 (r) 在特定条件下有效。在这里,我们讨论所需的七个关键假设: 连续规模:两个变量都必须以连续尺度进行测量。连续数据可以采用一定范围内的任何值,并且不限于类别或离散值。 配对观察:两个变量的数据应该配对。一个变量中的每个观测值对应于另一个变量中的一个观测值。 观察的独立性:每对观察值应独立于所有其他对。一对的价值不依赖于另一对的价值。 线性关系:两个变量之间必须存在线性关系。这意味着随着一个变量的增加或减少,另一个变量也会以直线可以表示的方式增加或减少。 双变量正态分布:理想情况下,两个变量都应服从正态分布,并且变量对应遵循二元正态分布。 同方性:回归线周围的数据点应一致地分布在自变量的每个水平上,这意味着每个变量内的方差是恒定的。 无异常值:数据不应包含任何显着的异常值,因为它们会对相关系数的值产生不成比例的影响。 通过满足这些假设,皮尔逊相关系数可以作为两个连续变量之间关联的可靠度量,反映线性关系的程度。视觉教具可以作为诊断工具来确保满足这些假设。 检测和管理异常值异常值可以通过多种方式扭曲两个变量之间的真实关系: r 的增加或减少:异常值可能会人为地夸大或缩小相关系数,从而给人一种比实际存在的线性关系更强或更弱的错误印象。 误导性解释:异常值可能导致非线性关系看起来呈线性或模糊重要关系,从而导致错误的结论。 检测异常值的方法检测异常值涉及图形和统计方法: 图形方法:散点图对于目视检查数据中的异常值非常有用。远离主数据簇的点可以被视为潜在的异常值。 统计方法:通常使用 Z 分数等技术,其中与平均值超过 3 个标准差的值通常被视为异常值,而四分位数范围 (IQR) 方法(其中四分位数 1.5 倍 IQR 之外的值被视为异常值)。
异常值之前:左图显示变量 X 和 Y 之间的相对线性关系,表明存在潜在的正相关关系,且没有异常值。 异常值之后:右图向数据集引入了异常值,明显扭曲了 X 和 Y 之间的感知关系,这可能会显着影响 Pearson 相关系数 r。 管理异常值一旦检测到异常值,就可以通过各种方法进行管理: 排除:从分析中删除异常值,如果异常值是错误的或不代表总体,则这是适当的。 转型:应用数学变换(例如对数或平方根变换)来减少由异常值引起的偏度。 归因:用更具代表性的值(例如数据的平均值或中位数)替换异常值,但这可能会导致结果出现偏差。 报告皮尔逊相关结果当您报告 Pearson 相关分析的结果时,应包括以下内容: 相关系数(r):这是分析的主要结果,表明两个变量之间线性关系的强度和方向。 自由度 (df):计算为分数对的数量减 2 (N−2)。它用于显着性检验。 P值:这表明观察到的相关性是否具有统计显着性。显着性的标准阈值是 p < 0.05,但这可能会根据领域和具体研究背景而有所不同。 置信区间:虽然并不总是包含在内,但置信区间 r 提供了真实相关系数可能落入的范围。 叙述性解释:除了数值结果之外,简要解释相关系数在您的研究中的含义也很有帮助。 范例报告以下是如何在研究论文或分析报告中报告皮尔逊相关结果的说明性示例: “采用皮尔逊相关分析来检验大学生的学习时间和考试成绩之间的关系。结果表明两个变量之间存在很强的正相关性,r(98) = 0.76,p < .001。这表明学习时间的增加与考试成绩的提高有关。这种关系的强度被认为是稳健的,如高相关系数和显着的 p 值所示。“ 要记住的要点 始终报告准确的值 r 和 p-值。 在您的研究背景下解释结果,解释相关性对您的具体研究问题意味着什么。 请谨慎,不要从相关性中暗示因果关系。高或低 r 值仅表示线性关系的强度和方向,而不是一个变量引起另一个变量的变化。 考虑讨论可能影响相关性解释的任何潜在限制或因素,例如异常值的存在或线性假设。通过遵循这些准则,您可以确保您的 Pearson 相关结果报告清晰、全面且对您的受众有价值,从而有效地促进更广泛的科学对话。 统计显着性和决定系数 (r²)了解统计显着性和决定系数(r²) 在解释 Pearson 相关分析的结果时至关重要。这些概念有助于确定两个变量之间线性关系的强度和方向以及观察到的相关性的可靠性和解释力。 统计学意义皮尔逊相关性中的统计显着性表明观察到的两个变量之间的相关性并非由随机机会造成的可能性。这 p- 与 Pearson 相关的值 r 指示观察到的相关性是否具有统计显着性。 解释:统计显着性的常见阈值是 p < 0.05,意味着观察到的相关性偶然发生的概率小于 5%。然而,阈值可能会根据研究的背景或学科而有所不同。 报告:报告统计显着性时,请包括准确的 p-价值。例如, ”变量 X 和 Y 之间的相关性显着,r(48) = 0.62,p=0.003。“ 决定系数 (r²)决定系数, r²,通过皮尔逊相关系数的平方获得(r)。它表示一个变量中可从另一个变量预测的方差比例。 解释:安 r例如,² 值为 0.36 表明另一个变量的方差解释了一个变量的 36% 的方差。越高 r²,线性关系的解释力越强。 上下文相关性: r² 通过量化一个变量的变化与另一个变量的变化相关的程度,可以更直观地理解相关性的强度。 报告 r² 的示例“在我们的分析中,学习时间和考试成绩之间的 Pearson 相关系数为 r = 0.60,具有统计显着性,p < 0.001。将此相关系数平方以计算决定系数 (r²),我们找到 r² = 0.36。这表明 36% 的考试成绩差异可以用学习时间来解释。这一发现凸显了学习时间对考试成绩的重大影响。“ 广告广告描述。 Lorem ipsum dolor sat amet,consectetur adipiscing elit。 了解更多 结论在本综合指南中,我们探讨了皮尔逊相关系数的复杂性(r),统计分析中用于测量两个连续变量之间的线性关系的基本工具。从科学研究到经济预测, r 作为一个关键指标,揭示变量的同步并指导底层数据模式的发现。 关键要点包括: 皮尔逊 r 范围: 皮尔逊 r 值范围从 +1 到 -1,其中接近极值的值表示强线性相关性,值 0 表示没有线性相关性。 解读 r: 的价值 r 量化线性关系的方向和强度,从而能够预测和洞察变量的相互依赖性。 统计学意义: 的意义 r,由 p-value,评估观察到的相关性是否可能不是偶然的。 决定系数(r²): 平方 r 产量 r²,它解释了一个变量可从另一个变量预测的方差百分比,从而增强了相关性影响的可解释性。 有效性假设:Pearson 的有效应用 r 需要遵守线性、同方差性和不存在异常值等假设,以确保结果可靠。 异常值管理:识别和解决异常值至关重要,因为它们可能会严重扭曲 r,影响相关性的准确性和解释。皮尔逊相关系数超越了单纯的数值分析,为了解数据集中变量的优雅舞蹈提供了一个窗口。它迫使研究人员和分析师更深入地研究数据结构,揭示为理论提供信息、推动发现和指导决策的关系。 推荐文章在我们的专家指导文章集中探索更多见解并加深您对统计相关性的理解。 相关系数计算器 肯德尔·陶-b VS 斯皮尔曼 统计相关性 常见问题解答(FAQ)Q1:皮尔逊相关系数到底是什么? 它是一种统计度量,反映两个连续变量之间的线性关系,用 r 表示。 Q2:什么时候适合使用 Pearson's r? 使用 Pearson r 衡量两个变量之间线性关系的强度和方向。 Q3:Pearson's r 可以确定变量之间的因果关系吗? 不,Pearson r 只能表示线性关联的强度,而不能表示因果关系。 Q4:测量尺度如何影响 Pearson 的 r? 事实并非如此; Pearson 的 r 是尺度不变的,这意味着它不受变量测量单位的影响。 Q5:Pearson r 值为 0 表示什么? r 值为 0 表明所研究的变量之间不存在线性相关性。 问题 6:使用 Pearson r 时是否存在假设? 是的,数据应该是正态分布的、线性相关的、同方差的等等。 Q7:Pearson r 的取值范围是多少? Pearson 的 r 范围可以从 +1(表示完全正相关)到 -1(表示完全负相关)。 Q8:异常值如何影响 Pearson 的 r? 异常值可能会严重影响结果,使相关性看起来比实际情况更强或更弱。 Q9:Pearson's r 可以用于序数数据吗? 不,Pearson 的 r 不适用于序数数据。通常使用斯皮尔曼等级相关性。 Q10:如何报告 Pearson 相关结果? 要确定统计显着性,请报告 r 值、自由度和 p 值。 |
【本文地址】