| perf性能分析工具使用分享 | 您所在的位置:网站首页 › 统计分析软件graph › perf性能分析工具使用分享 |
perf性能分析工具使用分享
|
@ 目录前言perf的介绍和安装perf基本使用perf list使用,可以列出所有的采样事件perf stat 概览程序的运行情况perf top实时显示当前系统的性能统计信息perf record 记录采集的数据perf report输出 record的结果perf diff进行两次record对比火焰图的制作结语 前言之前有分享过自己工作中自己搭建的CPU监控脚本等,但那个属于是自己手工写的一些脚本,比较粗浅的使用。后来就直接使用perf编译到驱动里面,在设备中直接使用perf了,比起自己写的脚本,效率直线提升。今天就来分享以下perf的功能使用,它可以将消耗 CPU 时间比较大的用户程序调用栈打印出来,并生成火焰图。 perf的介绍和安装Perf 是Linux kernel自带的系统性能优化工具。 Perf的优势在于与Linux Kernel的紧密结合,它可以最先应用到加入Kernel的new feature。pef可以用于查看热点函数,查看cashe miss的比率,从而帮助开发者来优化程序性能,也可以分析程序运行期间发生的硬件事件,比如 instructions retired ,processor clock cycles 等;您也可以分析 软件事件,比如 Page Fault 和进程切换,这使得 Perf 拥有了众多的性能分析能力, 通过它,应用程序可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计。它不但可以分析指定应用程序的性能问题 (per thread),也可以用来分析内核的性能问题,当然也可以同时分析应用代码和内核,从而全面理解应用程序中的性能瓶颈。 举例来说,使用 Perf 可以计算每个时钟周期内的指令数,称为 IPC,IPC 偏低表明代码没有很好地利用 CPU。Perf 还可以对程序进行函数级别的采样,从而了解程序的性能瓶颈究竟在哪里等等。Perf 还可以替代 strace,可以添加动态内核 probe 点,还可以做 benchmark 衡量调度器的好坏。。。 ubuntu安装: sudo apt-get install linux-tools-common linux-tools-"$(uname -r)" linux-cloud-tools-"$(uname -r)" linux-tools-generic linux-cloud-tools-generic
安装好之后使用perf -v命令查看版本
它和Oprofile性能调优工具等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,那么只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。 上面介绍了perf的原理,“根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文”,我们可以改变采样的触发条件使得我们可以获得不同的统计数据,例如 以时间点 ( 如 tick) 作为事件触发采样便可以获知程序运行时间的分布;以 cache miss 事件触发采样便可以知道 cache miss 的分布,即 cache 失效经常发生在哪些程序代码中。如此等等。 首先我们可以看一下 perf 中能够触发采样的事件有哪些。 perf list使用,可以列出所有的采样事件sudo perf list
可以看到 Hadrware event Software event等 Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样 Software Event 是内核软件产生的事件,比如进程切换,tick 数等 Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等 perf stat 概览程序的运行情况perf stat选项,可以在终端上执行命令时收集性能统计信息 sudo perf stat -p 11664
指定进程查看,ctrl +c 杀死进程之后,就可以看到相应的数据了。
参考 链接 perf top实时显示当前系统的性能统计信息sudo perf top -g 用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。
[.] : user level 用户态空间,若自己监控的进程为用户态进程,那么这些即主要为用户态的cpu-clock占用的数值 [k]: kernel level 内核态空间 [g]: guest kernel level (virtualization) 客户内核级别 [u]: guest os user space 操作系统用户空间 [H]: hypervisor 管理程序 The final column shows the symbol name. 当 perf 收集调用链时,开销可以在两列中显示为Children和Self 。这里的Self列与没有“-g”的列类似:这是每个函数花费的 CPU 周期百分比。但是Children列在其下方添加了所有调用函数所花费的时间。不仅是直系子女,而且是所有后代。对于调用图的叶子,函数不调用其他任何东西,Self 和 Children 的值是相等的。但是对于 main(),它增加了在 f1() perf.folded 5 最后生成svg图 FlameGraph/flamegraph.pl perf.folded > perf.svg 生成火焰图可以指定参数,–width 可以指定图片宽度,–height 指定每一个调用栈的高度,生成的火焰图,宽度越大就表示CPU耗时越多。
sudo perf record -e cpu-clock --call-graph dwarf -p pid 范例:perf record -e cpu-clock -g -p 29713 --call-graph dwarf 使用--call-graph dwarf 之后record生成的perf.data很大,大家生成的时候要时刻注意设备剩余空间是否足够 实际测试范例 如图一段代码 main -> do_main -> foo -> bar 其中 foo 函数和 bar 各有一个for循环,用来表示代码时间运行消耗的cpu #include #include #include #include using namespace std; void bar(){ // usleep(40*1000); /* do something here */ for(int i=0;i< 4000;i++) { } } void foo(){ // usleep(60*1000); for(int i=0;i< 5700;i++) { } bar(); } void do_main() { foo(); } int main(int argc,char** argv){ while(1) { do_main(); } }运行代码之后进行 top实时查看(因为我的设备默认都是sudo权限,所以以下命令都不用前缀sudo) ps -xu | grep target perf top -e cpu-clock -p 29713 发现 foo 占用 60%cpu时间,而bar占用40%时间,和for循环展示的大致一样
perf record -e cpu-clock -g -p 29713 ctrl + c停止记录,发现当前目录下保存了文件perf.data 使用report查看
perf report -i perf.data
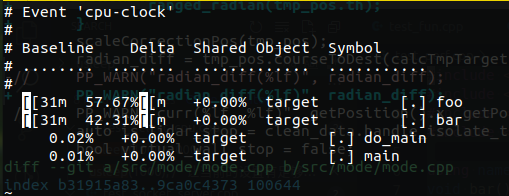
对比两者差异,因为只是单纯记录两次,代码没有修改,所以没有差异
perf diff perf.data perf.data
perf script -i perf.data &> perf.unfold
拷贝到主机端进行转换成火焰图
FlameGraph/flamegraph.pl test_data/perf.folded > test_data/perf.svg
大家可以看到这个cpu占用关系,火焰图的顶层是个大平层,说明这段代码cpu单个函数foo和bar占用率太高,这段代码优化空间很大。 结语这就是我自己的一些perf使用分享。如果大家有更好的想法和需求,也欢迎大家加我好友交流分享哈。 作者:良知犹存,白天努力工作,晚上原创公号号主。公众号内容除了技术还有些人生感悟,一个认真输出内容的职场老司机,也是一个技术之外丰富生活的人,摄影、音乐 and 篮球。关注我,与我一起同行。 ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧推荐阅读 【1】jetson nano开发使用的基础详细分享 【2】Linux开发coredump文件分析实战分享 【3】CPU中的程序是怎么运行起来的 必读 【4】cartographer环境建立以及建图测试 【5】设计模式之简单工厂模式、工厂模式、抽象工厂模式的对比 本公众号全部原创干货已整理成一个目录,回复[ 资源 ]即可获得。 |

 在设备中安装
如果你使用yocto,那么可是用bitbake perf 直接编译perf工具出来,然后做成镜像烧录到设备中,如果你使用的是其他根文件系统制作工具,方法也是类似。
在设备中安装
如果你使用yocto,那么可是用bitbake perf 直接编译perf工具出来,然后做成镜像烧录到设备中,如果你使用的是其他根文件系统制作工具,方法也是类似。 将编译好的的lib和bin目录拷贝到设备中使用。
将编译好的的lib和bin目录拷贝到设备中使用。


 注 :如果svg图出现unknown函数,使用如下命令
注 :如果svg图出现unknown函数,使用如下命令

 FlameGraph/stackcollapse-perf.pl test_data/perf.unfold &> test_data/perf.folded
FlameGraph/stackcollapse-perf.pl test_data/perf.unfold &> test_data/perf.folded

【本文地址】