| 三万字长文详解神级绘图框架 plotly | 您所在的位置:网站首页 › 绘制直方图时纵轴和横轴均需要从零开始吗 › 三万字长文详解神级绘图框架 plotly |
三万字长文详解神级绘图框架 plotly
|
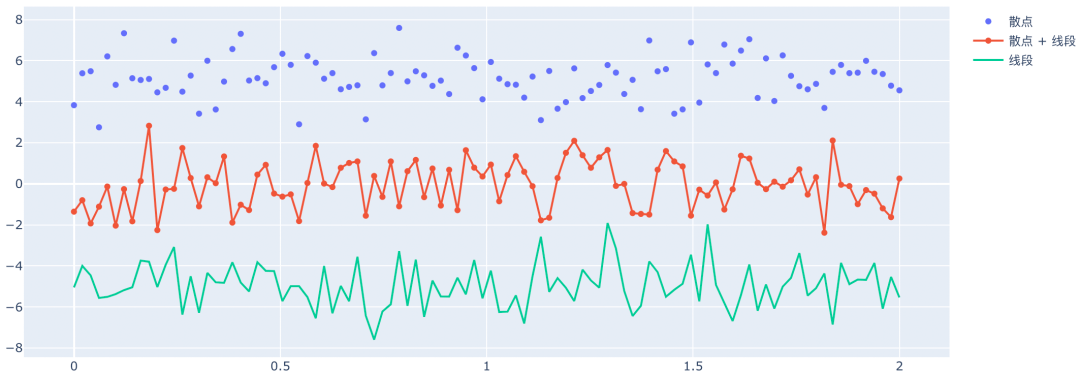
# 生成100个点 x = np.linspace( 0, 2, 100) y0 = np.random.randn( 100) + 5 y1 = np.random.randn( 100) y2 = np.random.randn( 100) - 5 # 里面的参数一会儿解释 trace0 = go.Scatter( x=x, # x 轴的坐标 y=y0, # y 轴的坐标 mode= "markers", # 纯散点绘图 name= "散点"# 曲线名称 ) trace1 = go.Scatter( x=x, y=y1, # 散点 + 线段绘图 mode= "markers + lines", name= "散点 + 线段" ) trace2 = go.Scatter( x=x, y=y2, mode= "lines", # 线段绘图 name= "线段" ) # 我们看到比较神奇的地方是,Scatter 居然也可以绘制线段 # 是的,如果不指定 mode 为 "markers",默认绘制的就是线段 # 以上就创建了三条轨迹,下面该干什么了?对,创建画布 # 将轨迹组合成列表传进去,因为一张画布是可以显示多条轨迹的 fig = go.Figure(data=[trace0, trace1, trace2]) # 在 notebook 中,直接通过 fig 即可显示图表 fig 看一下画出来的图是什么样子?
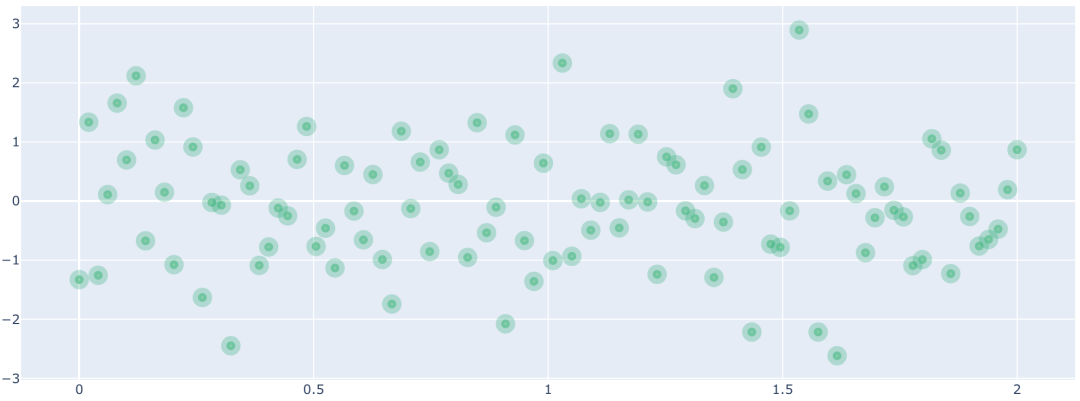
可以看到比 matplotlib 漂亮多了,在绘制轨迹的时候我们使用了 4 个参数,回顾一下: x:很好理解,就是 x 轴的坐标; y:很好理解,就是 y 轴的坐标; name:轨迹的名称,就是显示在画布右上方的那个; mode:轨迹的种类,主要有三种,"markers" 表示纯散点,"markers+lines" 表示散点加上线段,"lines" 是线段;然后再来看一个参数 marker,它接收一个字典,用来设置散点的样式。 x = np.linspace( 0, 2, 100) y0 = np.random.randn( 100) trace0 = go.Scatter( x=x, y=y0, mode= "markers", name= "散点图", marker={ # 点的大小 "size": 8, # 点的颜色 "color": "rgba(102, 198, 147, 0.7)", # 除此之外,还可以设置点的轮廓 "line": { # 线条大小 "width": 10, # 线条的颜色 "color": "rgba(1, 170, 118, 0.3)" } } ) fig = go.Figure(data=[trace0]) fig
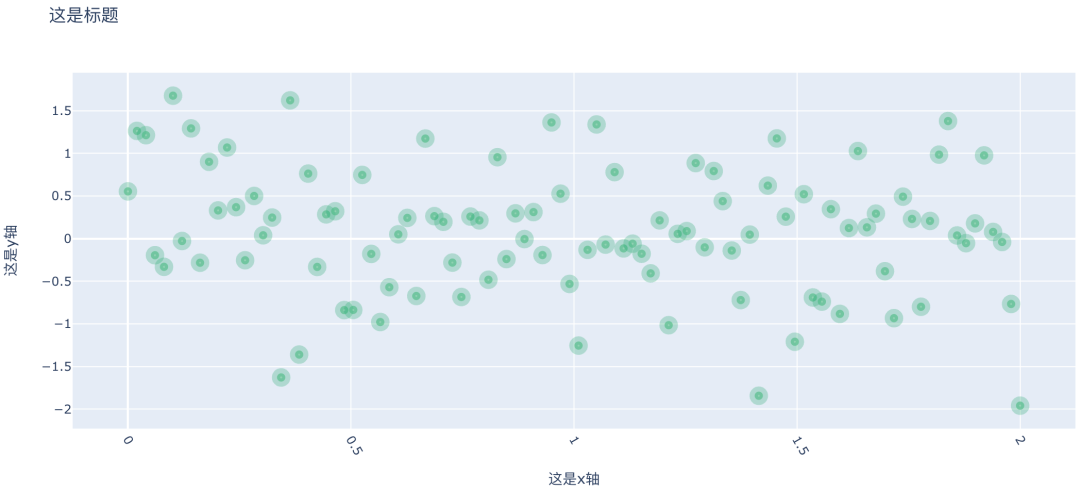
这里我们没有指定 name 参数,所以右上角不会显示轨迹的名称。再来总结一下 marker 参数: marker = { # 点的大小 "size": n, # 点的颜色,可以是 rgba,可以是 rgb; # 可以是颜色的英文名,比如 green,yellow; # 可以是一个 16 进制颜色码,比如:#FF6A04 # 以及它还可以是一个元素个数与轨迹的点的个数相同的数组 # 对应着数组中相同的值的多个点,会被标记为同一种颜色 # 在机器学习里面进行聚类的时候,非常常见 "color": "rgba(n1, n2, n3, n4)", # 点的线条、轮廓 "line": { "width": n, "color": "green"} # 是否在右侧显示一个颜色条,默认为 False,不显示 "showscale": True } 基于以上参数,我们可以将散点图的样式绘制得非常漂亮。 问题来了,如果我想添加标题以及坐标轴名称该怎么办? # 其它代码不变 fig = go.Figure( data=[trace0], layout={ "title": "这是标题", "xaxis_title": "这是x轴", "yaxis_title": "这是y轴", # x轴坐标倾斜60度 "xaxis": { "tickangle": 60} } ) fig
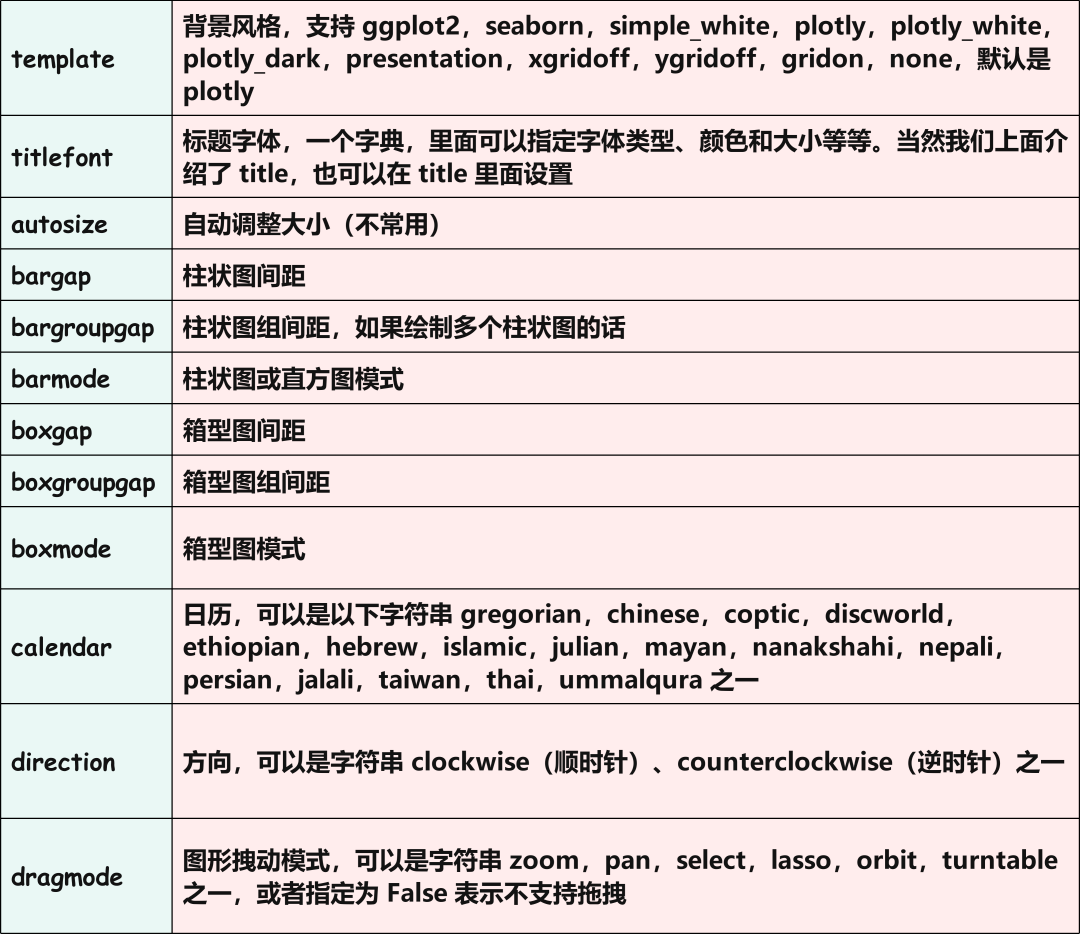
我们看到指定 layout 参数即可给画布设置一些额外属性,该参数可以接收一个字典,通过里面的 key 来指定画布属性,比如: title:标题; xaxis_title:x 轴标题; yaxis_title:y 轴标题; xaxis:x 坐标轴的属性,可以传入一个字典,来设置坐标轴,比如:tickangle 就是将坐标倾斜。尤其在坐标值比较长的时候,我们就可以通过倾斜的方式来避免堆叠在一起。角度大于0顺时针,小于0逆时针。 yaxis:y 坐标轴的属性 ,和 x 坐标轴一样,可以设置非常多的属性。具体能设置哪些,后面单独罗列出来; width:画布的宽度; height:画布的高度; template:画布的风格,可以选择 ggplot2, seaborn, simple_white, plotly, plotly_white, plotly_dark, presentation, xgridoff, ygridoff, gridon, none,默认是 plotly;
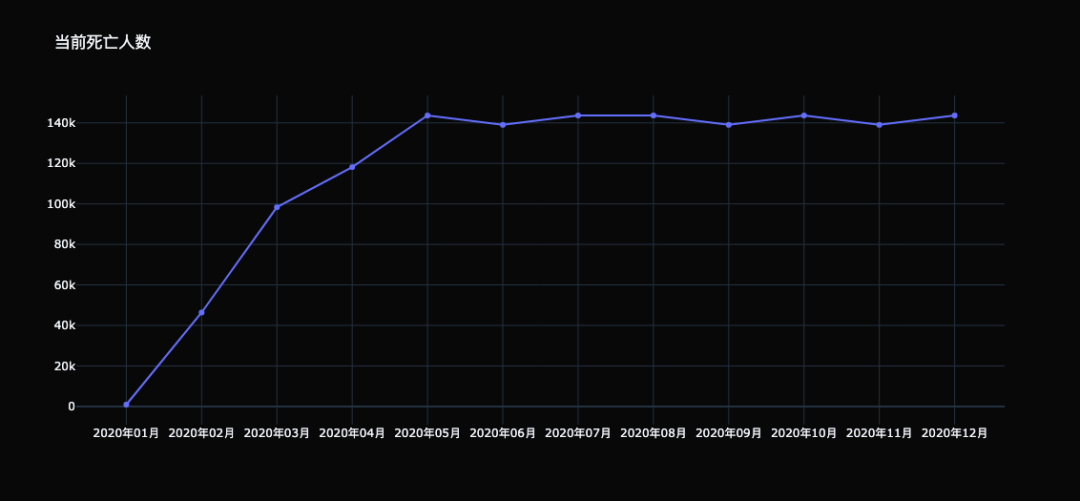
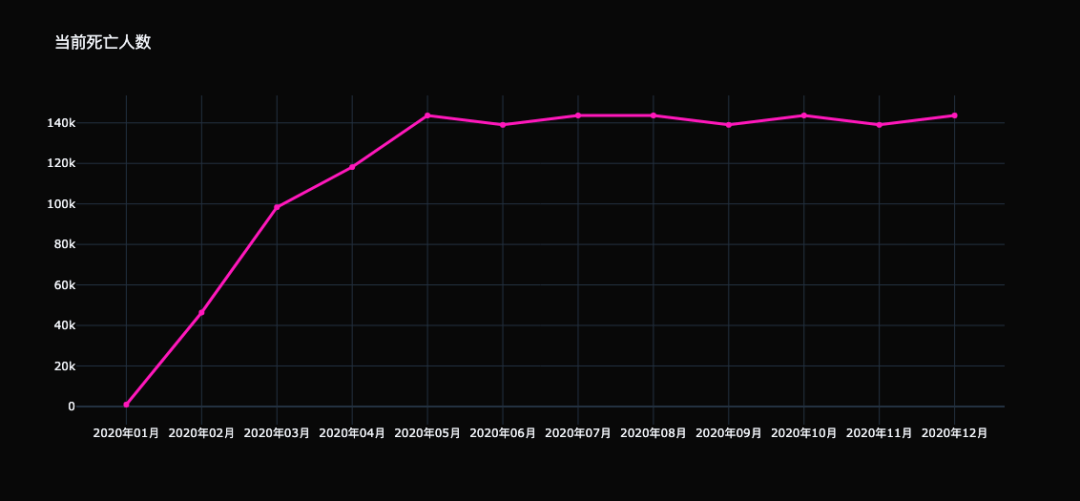
散点图的存在意义 散点图常被用于分析变量之间的相关性,如果两个变量的散点看上去都在某条直线附近波动,则称变量之间是线性相关的;如果所有点看上去都在某条曲线(非直线)附近波动,则称变量之间是非线形相关的;如果所有点在图中没有显示任何关系,则称变量之间是不相关的。 如果散点图呈现出一个集中的大致趋势,并且该趋势可以用一条光滑的曲线来近似,那么这个近似的过程就是曲线拟合,而这条曲线则被称为最佳拟合线或趋势线。如果图中存在个别远离集中区域的数据点,那么这样的点被称为离群点或异常值。 折线图 折线图(Line)是一个由笛卡尔坐标系、一些点、以及线段组成的统计图表,常用来表示数值随连续时间间隔或有序类别的变化。在折线图中,x 轴通常用作连续时间间隔或有序类别(比如阶段1、阶段2、阶段3);y 轴用于量化的数据,如果为负值则绘制于 y 轴下方;而连线用于连接两个相邻的数据点。 # covid_19_deaths 是数据集,这个不需要关心 # 你完全可以使用其他的数据集代替 trace0 = go.Scatter( x=covid_19_deaths[ "date"], y=covid_19_deaths[ "count"], ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark", "title": "当前死亡人数"}) fig
虽然用的是 go.Scatter,但默认绘制的是折线图。还记得怎么绘制散点图吗?对的,将 mode 指定为 "markers" 即可。 然后是给折线添加样式,我们给散点图添加样式是通过 marker 参数,而给折线添加样式也有对应的参数。 trace0 = go.Scatter( x=covid_19_deaths[ "date"], y=covid_19_deaths[ "count"], line={ # 折线的宽度和颜色 "width": 3, "color": "rgba(255, 30, 186, 1)" } ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark", "title": "当前死亡人数"}) fig
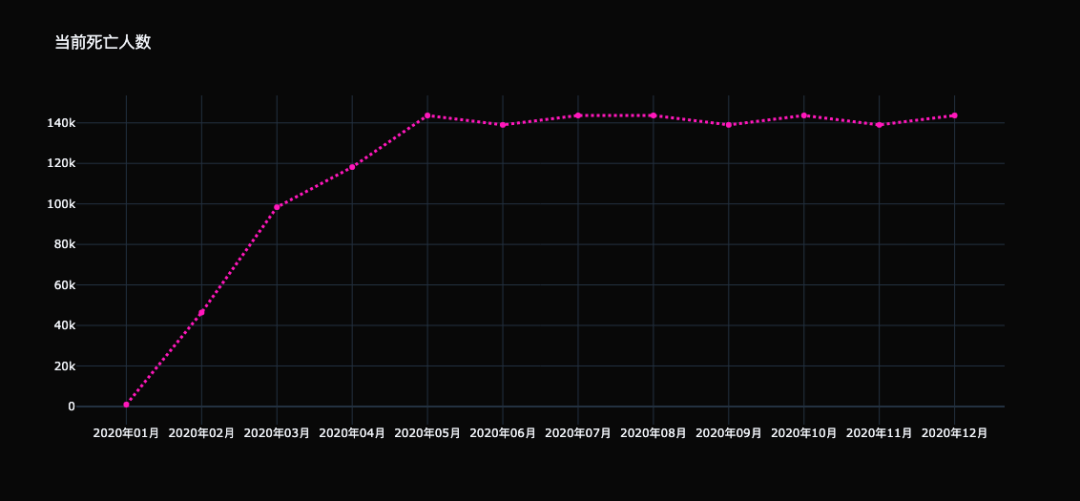
此时折线的样式就改变了,但是我们记得之前在设置散点图的时候好像也用到了 line。没错,只不过那个 line 是传给 marker 参数的字典里面的一个 key,用来设置点的线条、或者轮廓的样式。而这里的 line 它是一个参数,和 marker 参数是同级别的,是用来设置折线样式的。 参数 line 里面还可以指定折线的种类,是虚线、实线等等之类的。 trace0 = go.Scatter( x=covid_19_deaths[ "date"], y=covid_19_deaths[ "count"], line={ "width": 3, "color": "rgba(255, 30, 186, 1)", "dash": "dot"# 指定为虚线 } ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark", "title": "当前死亡人数"}) fig
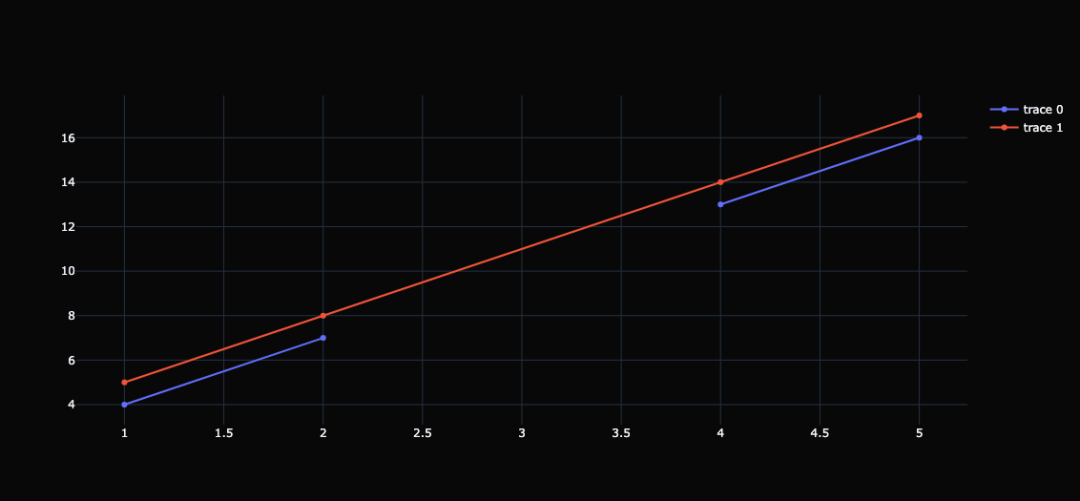
"dash" 表示线条的种类,可选的 value 如下: "dot":由点组成的虚线; "dash":由短线组成的虚线; "dashdot":由点和短线组成的虚线;绘制直线的时候,数据可能不是连续的,那么绘制出来的图像就会出现断层。这个时候我们可以指定 connectgaps 参数,举个例子: x = np.array([ 1, 2, np.nan, 4, 5]) y1 = x * 3+ 1 y2 = x * 3+ 2 trace0 = go.Scatter( x=x, y=y1, ) trace1 = go.Scatter( x=x, y=y2, connectgaps= True ) fig = go.Figure(data=[trace0, trace1], layout={ "template": "plotly_dark"}) fig
当数据出现了空值的时候,那么折线默认是会出现断层的,而将 connectgaps 指定为 True ,那么会将缺失值两端的点直接相连,使得直线是完整的。
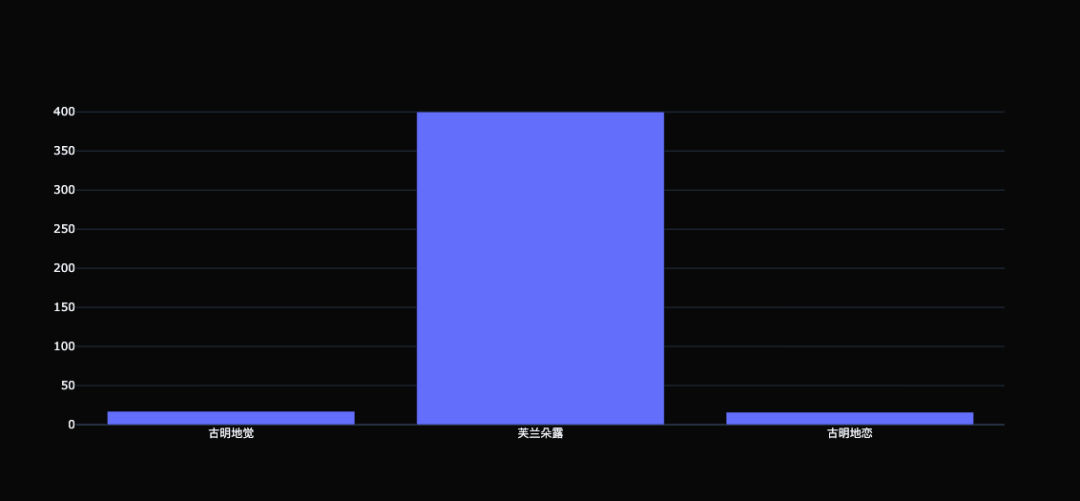
折线图的存在意义 折线图用于分析事物随时间或有序类别而变化的趋势,如果有多组数据,则用于分析多组数据随时间变化或有序类别的相互作用和影响。折线的方向表示正 / 负变化,折线的斜率表示变化的程度。 柱状图 柱状图,是一种使用矩形条,对不同类别进行数值比较的统计图表。最基础的柱形图,需要一个分类变量和一个数值变量。在柱状图上,分类变量的每个实体都被表示为一个矩形(通俗来讲就是柱子),而数值则决定了柱子的高度。 trace0 = go.Bar( x=[ "古明地觉", "芙兰朵露", "古明地恋"], y=[ 17, 400, 16], ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
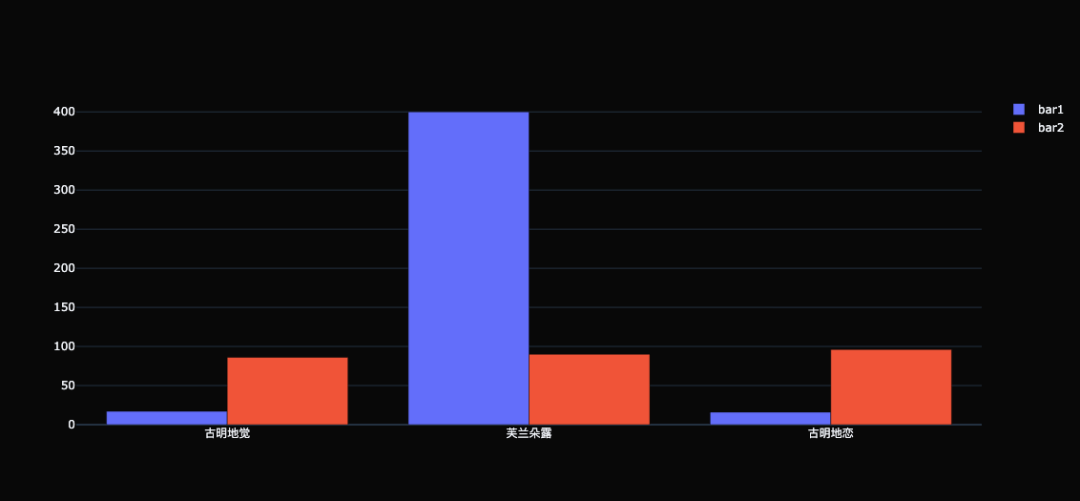
这是最简单的柱状图,很明显,即便我们什么参数都不加,样式就已经把 matplotlib 给秒杀了。所以先不管 plotly 这个框架的功能如何(很强),光图表的颜值就足以让我们去学习它。 当然我们也可以绘制多个柱状图: trace0 = go.Bar( x=[ "古明地觉", "芙兰朵露", "古明地恋"], y=[ 17, 400, 16], name= "bar1" ) trace1 = go.Bar( x=[ "古明地觉", "芙兰朵露", "古明地恋"], y=[ 86, 90, 96], name= "bar2" ) fig = go.Figure(data=[trace0, trace1], layout={ "template": "plotly_dark"}) fig
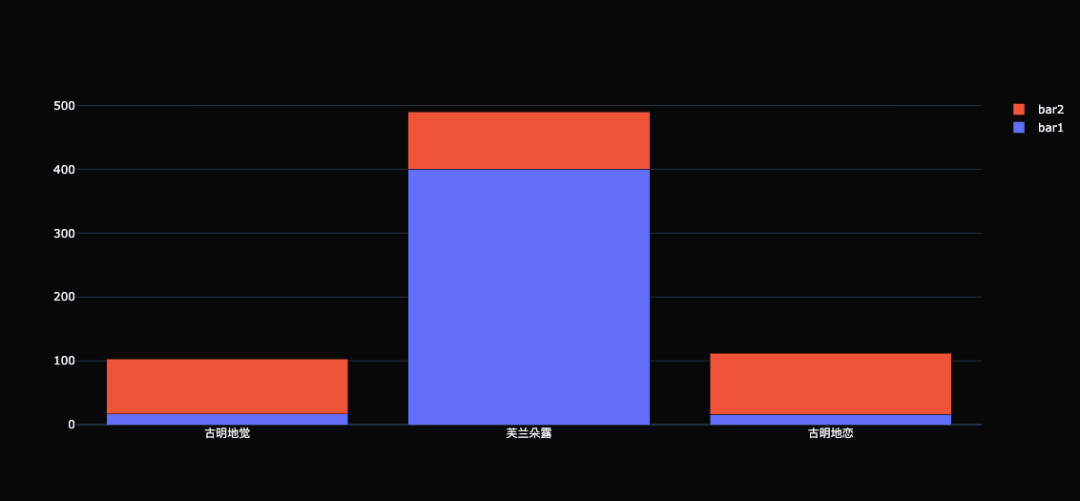
可以看到柱状图并排显示在一起了,此外我们还可以设置层叠柱状图。 trace0 = go.Bar( x=[ "古明地觉", "芙兰朵露", "古明地恋"], y=[ 17, 400, 16], name= "bar1" ) trace1 = go.Bar( x=[ "古明地觉", "芙兰朵露", "古明地恋"], y=[ 86, 90, 96], name= "bar2" ) # 指定 barmode 为 stack,会将柱状图堆叠在一起 # 这里又多了一个 barmode,所以可调节的属性非常多 # 但是不同的属性适用于不同的轨迹,我们需要哪个就设置哪个即可 fig = go.Figure(data=[trace0, trace1], layout={ "template": "plotly_dark", "barmode": "stack"}) fig
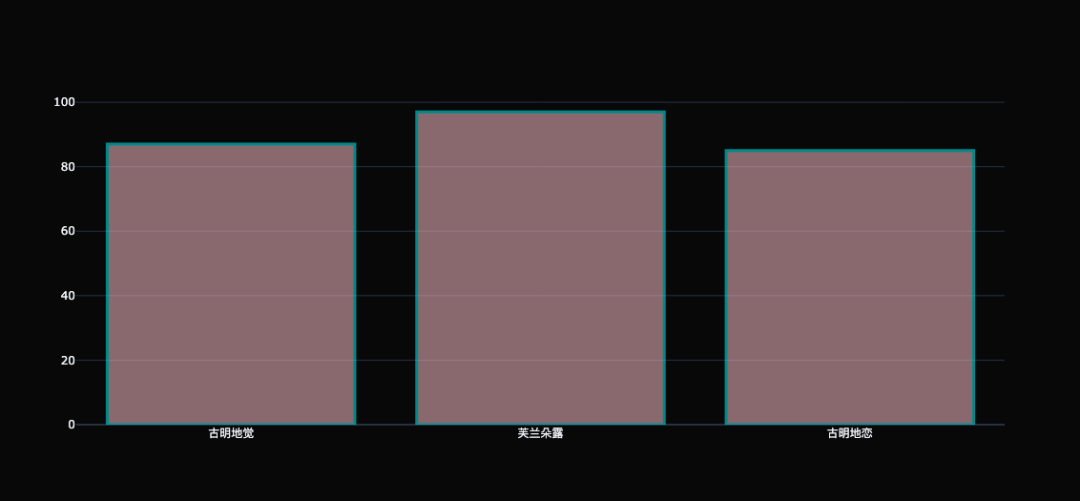
所以层叠柱状图是在画布里面设置的,因为两个轨迹要显示在画布上。至于 Bar 里面的参数是设置轨迹本身, 比如我们还可以调节颜色什么的,通过参数 marker 指定: trace0 = go.Bar( x=[ "古明地觉", "芙兰朵露", "古明地恋"], y=[ 87, 97, 85], name= "bar1", marker={ # 除了rgba,还可以通过颜色的名称指定 "color": "pink", # 指定透明度 # 这里指定透明度的方式,同样适用于Scatter "opacity": 0.5, "line": { "width": 3, # 轮廓的宽度 "color": "cyan", # 轮廓的颜色 } } ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
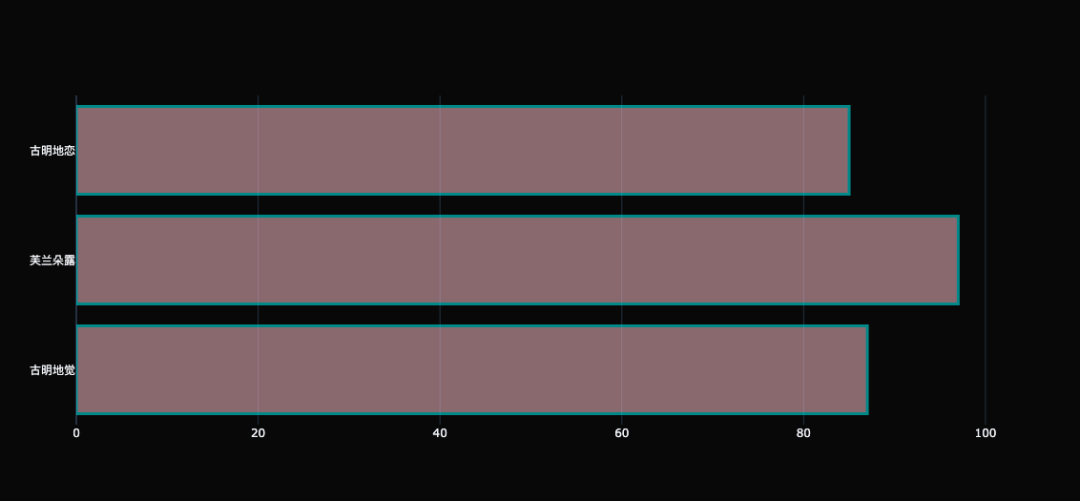
柱状图如果想调节样式,也是通过 marker 参数,和 Scatter 里面 marker 一样。 柱状图的存在意义 柱状图最适合对分类的数据进行比较,尤其是当数值比较接近时,由于人眼对于高度的感知优于其它视觉元素(如面积、角度等),因此使用柱状图更加合适。 作为人们最常用的图表之一,柱状图也衍生出多种多样的图表形式。例如,将多个并列的类别聚类、形成一组,再在组与组之间进行比较,这种图表叫做分组柱状图或簇状柱形图。还可以将类别拆分成多个子类别,形成堆叠柱状图。再比如将柱形图和折线图结合起来,共同绘制在一张图上,俗称双轴图等等。 水平柱状图 水平柱状图也叫条形图,和柱状图类似,也是通过 go.Bar 来绘制,只不过需要多加一个参数。 trace0 = go.Bar( # 方向变了,所以 x 轴和 y 轴的数据也要调换位置 y=[ "古明地觉", "芙兰朵露", "古明地恋"], x=[ 87, 97, 85], marker={ "color": "pink", "opacity": 0.5, "line": { "width": 3, "color": "cyan", } }, # 指定为水平方向即可 orientation= "h" ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
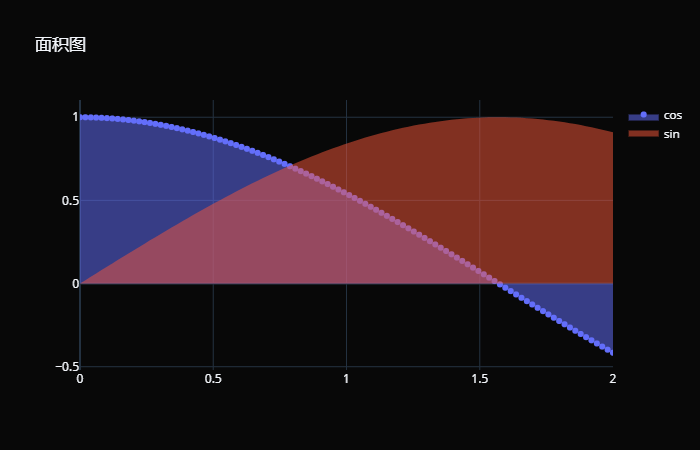
柱状图有多高取决于 y 轴,而水平柱状图有多长就取决于 x 轴了,所以此时 x 轴就是代表数值的那一方。至于设置颜色、轮廓等参数,和之前的柱状图一样。 面积图 面积图,又称区域图,是一种随有序变量的变化,反映数值变化的统计图表,原理与折线图相似。而面积图的特点在于,折线与自变量坐标轴之间的区域,会用颜色或者纹理填充。 绘制面积图依旧使用 Scatter,只需要指定一个 fill 参数即可。 x = np.linspace( 0, 2, 100) y0 = np.cos(x) y1 = np.sin(x) trace0 = go.Scatter( x=x, y=y0, name= "cos", mode= "markers", fill= "tozeroy" ) trace1 = go.Scatter( x=x, y=y1, name= "sin", # mode还可以设置为none,表示将线段隐藏 mode= "none", fill= "tozeroy" ) fig = go.Figure(data=[trace0, trace1], layout={ "title": "面积图", "template": "plotly_dark"}) fig
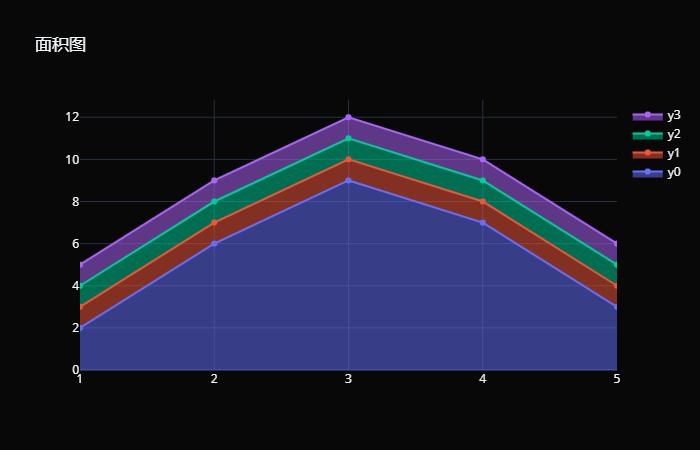
我们看到面积图就是将轨迹和 x 轴围成的部分涂上颜色,仔细观察橘色的 sin,线段没了,所以线段或者此时的面积图的边界线就相当于被隐藏掉了。如果不指定 fill,直接指定 mode="none" 也是可以隐藏的,只不过此时绘制的线段你就看不到了。另外我们看到即使是散点,也是可以围成面积图的,会用线将点拟合起来,再绘制围成的面积图。 然后注意 fill 参数,它的可选值如下: tozeroy:与 x 轴围成的面积; tozerox:与 y 轴围成的面积; toself:与自身围成的面积;除了这三个可选值之外,其实还有几个,不过一般用不到。我们主要用的还是 tozeroy,绘制和 x 轴围成的面积。 x = np.array([ 1, 2, 3, 4, 5]) y0 = np.array([ 2, 6, 9, 7, 3]) y1 = y0 + 1 y2 = y0 + 2 y3 = y0 + 3 trace0 = go.Scatter( x=x, y=y0, name= "y0", fill= "tonexty" ) trace1 = go.Scatter( x=x, y=y1, name= "y1", fill= "tonexty" ) trace2 = go.Scatter( x=x, y=y2, name= "y2", fill= "tonexty" ) trace3 = go.Scatter( x=x, y=y3, name= "y3", fill= "tonexty" ) fig = go.Figure(data=[trace0, trace1, trace2, trace3], layout={ "title": "面积图", "template": "plotly_dark"}) fig
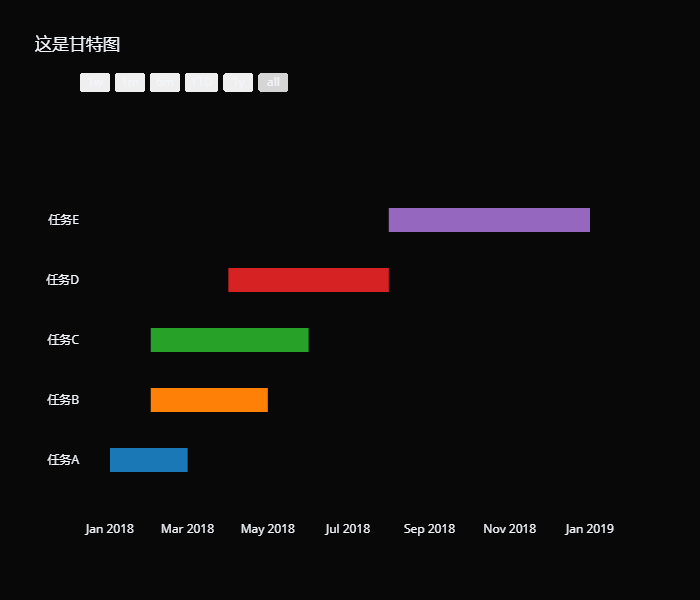
还是很简单的。 面积图的存在意义 面积图可用于多个系列数据的比较,此时面积图的外观看上去类似层叠的山脉,在错落有致的外形下表达数据的总量和趋势。相较于折线图,面积图不仅可以清晰地反映出数据的趋势变化,也能够强调不同类别的数据间的差距对比。 但它的劣势在于,填充会让形状互相遮盖,反而看不清变化。我们上面的数据弄的比较规整,所以看起来很清晰,但实际工作中绘制出来的面积图就不一定了。而一种解决方法是使用有透明度的颜色,来让出覆盖区域。 甘特图 甘特图又称横道图,是用来显示项目进度等与时间相关的数据的。直接看个例子就很好理解了: # 创建甘特图,使用plotly.figure_factory # 然后调用内部的create_gantt即可 importplotly.figure_factory asff tasks = [ { "Task": "任务A", "Start": "2018-1-1", "Finish": "2018-3-1"}, { "Task": "任务B", "Start": "2018-2-1", "Finish": "2018-5-1"}, { "Task": "任务C", "Start": "2018-2-1", "Finish": "2018-6-1"}, { "Task": "任务D", "Start": "2018-4-1", "Finish": "2018-8-1"}, { "Task": "任务E", "Start": "2018-8-1", "Finish": "2019-1-1"} ] # 但是数据格式有要求,里面是一个列表,列表里面是字典 # 字典包含至少三个键值对,分别是 Task、Start、Finish # 表示任务、开始时间、结束时间,不能是其它的名字 fig = ff.create_gantt(tasks, title= "这是甘特图") # 此时会直接返回画布,想调整属性的话 # 通过 fig.layout.update 即可 fig.layout.update({ "template": "plotly_dark"}) fig
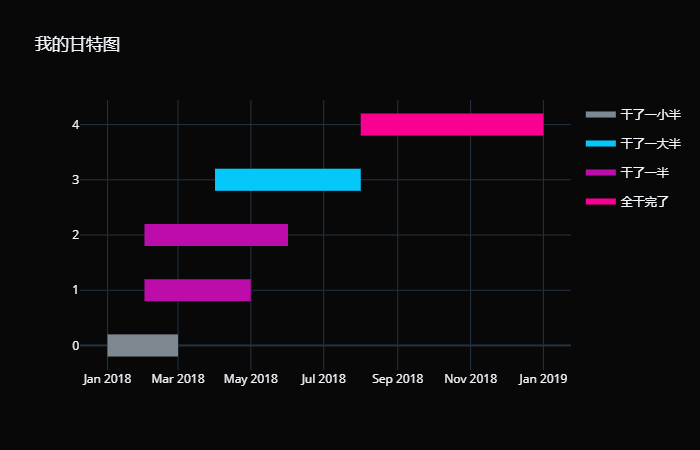
创建甘特图的时候,除了传递一个包含字典的列表,还可以传递 DataFrame,当然列名同样必须是 Task, Start, Finish。 此外我们还可以指定颜色,以及进度。 # 创建甘特图,使用plotly.figure_factory # 然后调用内部的create_gantt即可 importplotly.figure_factory asff tasks = [ { "Task": "任务A", "Start": "2018-1-1", "Finish": "2018-3-1", "Complete": "干了一小半"}, { "Task": "任务B", "Start": "2018-2-1", "Finish": "2018-5-1", "Complete": "干了一半"}, { "Task": "任务C", "Start": "2018-2-1", "Finish": "2018-6-1", "Complete": "干了一半"}, { "Task": "任务D", "Start": "2018-4-1", "Finish": "2018-8-1", "Complete": "干了一大半"}, { "Task": "任务E", "Start": "2018-8-1", "Finish": "2019-1-1", "Complete": "全干完了"} ] # 为不同的进度赋予不同的颜色 colors = { "干了一小半": "rgb(125, 135, 144)", "干了一半": "rgb(187, 20, 168)", "干了一大半": "rgb(14, 199, 250)", "全干完了": "rgb(250, 1, 144)" } fig = ff.create_gantt(tasks, # 为不同的进度赋予不同的颜色 colors=colors, # 表示进度,名字任意 # 这里我们叫 "Complete" index_col= "Complete", # 显示颜色条 show_colorbar= True) # fig.data 获取所有的轨迹 # fig.layout 获取画布的属性 fig = go.Figure(fig.data, layout={ "template": "plotly_dark", "title": "我的甘特图"}) fig
甘特图感觉在工作中用的不是很多,了解一下就好。 直方图 直方图,又称质量分布图,用于表示数据的分布情况,是一种常见的统计图表。一般用横轴表示数据区间,纵轴表示分布情况,柱子越高,则落在该区间的数量越大。根据数据分布状况不同,直方图展示的数据有不同的模式,包括对称单峰、偏左单峰、偏右单峰、双峰、多峰以及对称多峰。 构建直方图,首先要确定组距、对数值的范围进行分区,通俗的说就是划定有几根柱子(例如 0-100 分,每隔20分划一个区间,共5个区间)。接着,对落在每个区间的数值进行频次计算(如落在 80-100 分的 10 人,60-80 分的 20 人,以此类推)。最后,绘制矩形,高度由频数决定。 直方图与上面介绍的柱状图有点相像,但其实是完全不同的。前者反映数据分布情况,后者则不具备此功能,只能对数值进行比较。从数据结构来说,柱状图需要 1 个分类变量,是离散的(如一班、二班、三班),因此柱子间有空隙。但直方图的数据均为连续的数值变量(如成绩),因此柱子间是没有空隙的。 x = np.random.randint( 1, 20, 1000) trace0 = go.Histogram(x=x) fig = go.Figure(data=[trace0], layout={ "title": "直方图", "template": "plotly_dark"}) fig
横坐标是数值,纵坐标是出现的次数。但是有些不完美,就是跨度太大了,所以我们可以指定 xaxis 属性,让跨度小一些。 x = np.random.randint( 1, 20, 1000) trace0 = go.Histogram( x=x, # 指定histnorm为probability # 那么y轴将显示出现的次数所占的比例 histnorm= "probability" ) fig = go.Figure(data=[trace0], layout={ "title": "直方图", "template": "plotly_dark", # range表示坐标范围 # dtick表示相邻坐标之间的差值 # 这里是 2,所以就是 0 2 4 6... "xaxis": { "dtick": 2, "range": [ 0, 20]} }) fig
忘记说了,其实所有的图表对应的类里面,很多参数都是相同的,比如 marker 设置图表本身的颜色透明度、以及轮廓的颜色、大小,name 设置图表的名称等等,这些参数我们不再赘述,而是会直接使用。 然后我们也可以绘制多个直方图: x0 = np.random.randn( 1000) x1 = np.random.chisquare( 5, 1000) trace0 = go.Histogram( x=x0, histnorm= "probability", marker={ "opacity": 0.75 } ) trace1 = go.Histogram( x=x1, histnorm= "probability", marker={ "opacity": 0.75 } ) fig = go.Figure(data=[trace0, trace1], layout={ "title": "直方图", "template": "plotly_dark", "xaxis": { "dtick": 2, "range": [ 1, 20]} }) fig
但是我们发现这个直方图貌似有些不对劲,因为 plotly 将多个直方图强制变窄了,我们需要将 barmode 指定为 "overlay"。 x0 = np.random.randn( 1000) x1 = np.random.chisquare( 5, 1000) trace0 = go.Histogram( x=x0, histnorm= "probability", marker={ "opacity": 0.75 } ) trace1 = go.Histogram( x=x1, histnorm= "probability", marker={ "opacity": 0.75 } ) fig = go.Figure(data=[trace0, trace1], layout={ "title": "直方图", "template": "plotly_dark", "barmode": "overlay"}) fig
如果将 barmode 改成 "stack",那么就会创建堆叠直方图。 x0 = np.random.randn( 1000) x1 = np.random.randn( 1000) trace0 = go.Histogram( x=x0, histnorm= "probability", marker={ "opacity": 0.75 } ) trace1 = go.Histogram( x=x1, histnorm= "probability", marker={ "opacity": 0.75 } ) fig = go.Figure(data=[trace0, trace1], layout={ "title": "堆叠直方图", "template": "plotly_dark", "barmode": "stack"}) fig
最后是累计直方图,它的特点是:第n+1个区间的样本数是第n-1个区间的样本数加上第n个区间的样本数。 x0 = np.random.randn( 1000) trace0 = go.Histogram( x=x0, histnorm= "probability", marker={ "opacity": 0.75 }, # 指定 cumulative 即可 cumulative={ "enabled": True} ) fig = go.Figure(data=[trace0], layout={ "title": "累计直方图", "template": "plotly_dark", "barmode": "stack"}) fig
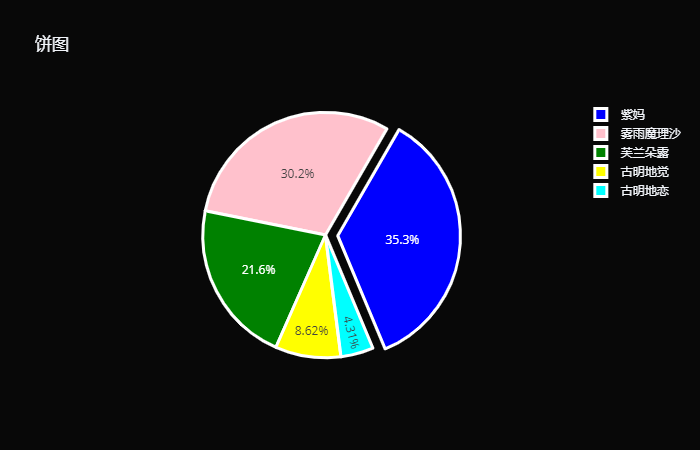
直方图的种类还是蛮多的,但说实话,感觉直方图用的也不是很多。如果只是做简单的报表统计,那么几乎用不到直方图。但我们接下来要介绍的饼图,使用就很广泛了。 饼图 饼图是一种划分为几个扇形的圆形统计图表。在饼图中,每个扇形的弧长(以及圆心角和面积)大小,表示该种类占总体的比例,并且这些扇形合在一起刚好是一个完全的圆形。 饼图最显著的功能在于表现占比。习惯上,人们也用饼图来比较扇形的大小,从而获得对数据的认知。但是,由于人类对角度的感知能力不如长度,因此在需要准确的表达数值(尤其是当数值接近、或数值很多)时,饼图常常不能胜任,建议用柱状图代替。 # 饼图就很简单了,使用 Pie 这个类 trace0 = go.Pie( labels=[ "古明地觉", "芙兰朵露", "古明地恋", "雾雨魔理沙", "紫妈"], values=[ 10, 25, 5, 35, 41] ) fig = go.Figure(data=[trace0], layout={ "title": "饼图", "template": "plotly_dark"}) fig
我们还可以设置环形饼图,就是在中间挖一个洞。 trace0 = go.Pie( labels=[ "古明地觉", "芙兰朵露", "古明地恋", "雾雨魔理沙", "紫妈"], values=[ 10, 25, 5, 35, 41], hole= 0.7# 从中心挖掉百分之70的部分 ) fig = go.Figure(data=[trace0], layout={ "title": "饼图", "template": "plotly_dark"}) fig
我们还可以将饼图旋转一定角度,因为最上方的两个部分明显是垂直分隔的,另外也可以使某一个部分突出。 trace0 = go.Pie( labels=[ "古明地觉", "芙兰朵露", "古明地恋", "雾雨魔理沙", "紫妈"], values=[ 10, 25, 5, 35, 41], pull=[ 0, 0, 0, 0, 0.1], # 突出最后一个 rotation= 30, # 旋转30度 marker={ # 饼图也有marker参数,基本上所有图表都有marker参数 # 散点图可以指定一种颜色来让所有的点都呈现相同的颜色 # 但是饼图的每一部分应该是不同的颜色,这才符合饼图这种图形的意义 # 所以我们要传入一个列表,而数据有五个,那么也要指定五种颜色 # 但是即便不指定五个、或者颜色重复也是可以的 # 如果颜色不够,plotly会帮你补充,颜色多了,会只选列表的前五个 "colors": [ "yellow", "green", "cyan", "pink", "blue"], # 并且这里不叫 color 了,而是叫 colors,因为多个颜色 "line": { "width": 3, "color": "white", # 轮廓颜色 } } ) fig = go.Figure(data=[trace0], layout={ "title": "饼图", "template": "plotly_dark"}) fig
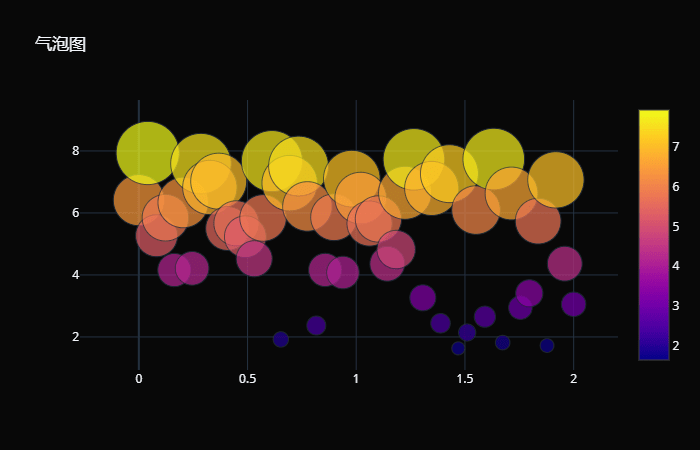
作为最常见的图表之一,饼图大量应用于各行各业的报告中。比如一家公司有着 5 个业务,现在要看每个业务的营收占据总营收的比例,那么饼图再合适不过了。 气泡图 气泡图是一种多变量的统计图表,由笛卡尔坐标系和大小不一的圆组成,可以看作是散点图的变形。在气泡图中,每个气泡都代表着一组三个维度的数据,其中前两个维度决定了气泡在笛卡尔坐标系中的位置(即x,y轴上的值),另外一个则通过气泡的大小来表示。例如,x 轴表示产品销量,y 轴表示产品利润,气泡大小代表产品市场份额百分比。 当然,气泡图也可以容纳更多维的数据,例如用第4个变量决定气泡的颜色、透明度等。 # 生成100个点,x 是横坐标 x = np.linspace( 0, 2, 50) # y 是纵坐标 y = np.random.uniform( 1, 8, 50) # x 和 y 确定了气泡的位置 # 而数值的大小,则确定气泡的大小 trace0 = go.Scatter( x=x, y=y, mode= "markers", marker={ # size 还可以是一个数组 # 手动指定每一个气泡的大小 "size": 13* y / np.min(y), # color 同样可以是数组 # 值相同的气泡会使用同一种颜色 "color": y, # 显示颜色条 "showscale": True } ) fig = go.Figure(data=[trace0], layout={ "title": "气泡图", "template": "plotly_dark"}) fig
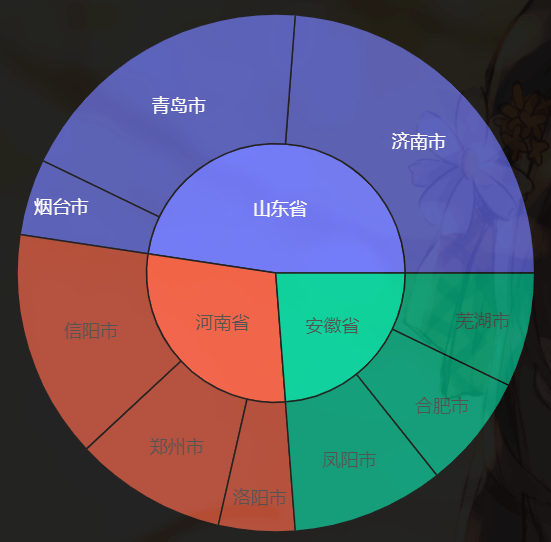
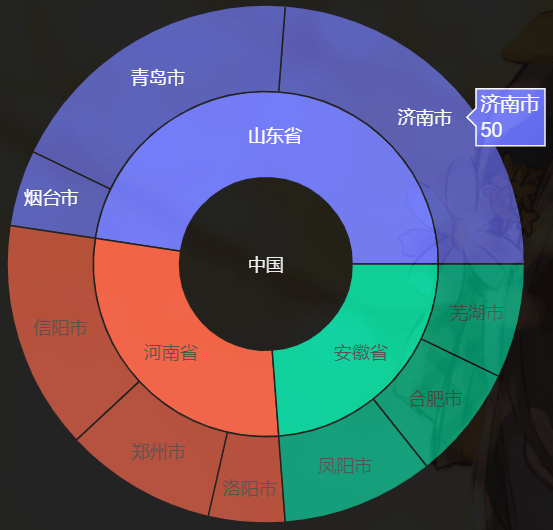
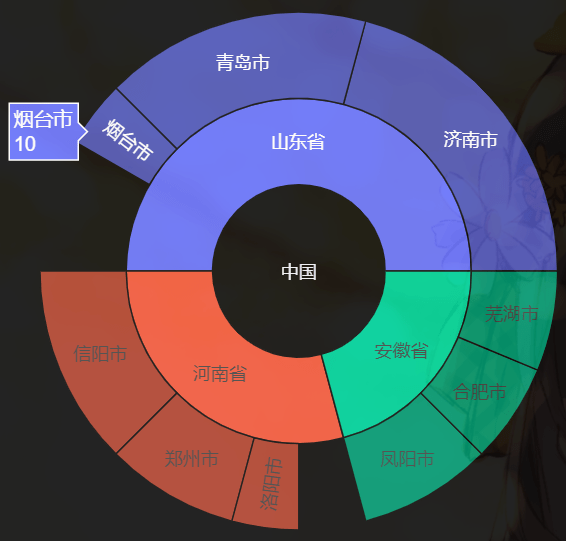
气泡图通常用于展示和比较数据之间的关系和分布,通过比较气泡位置和大小来分析数据维度之间的相关性。 气泡图也可以用于二维数据,即 y 轴和气泡大小使用同一维度的数据(y 轴和气泡大小的双视觉编码)。这种情况下,它实际上是作为柱状图的替代,用于对比分类数据,但比柱状图更加简洁美观。 旭日图 旭日图是一种表现层级数据的图表,它以父子层次结构来显示数据,并构成一个同心圆,因此又被成为称为多层饼图。离原点越近,数据的层级越高。换句话说,相邻的两层,内层是外层的父。 同时,一个父可以有多个子,即某一个环形又可以被分割成多个环形,环形的弧度由它在父层中所占比例来决定。若无占比关系,则处理成均分。 labels=[ "河南省", "信阳市", "郑州市", "洛阳市", "山东省", "济南市", "青岛市", "烟台市", "安徽省", "凤阳市", "合肥市", "芜湖市"] parents=[ "", "河南省", "河南省", "河南省", "", "山东省", "山东省", "山东省", "", "安徽省", "安徽省", "安徽省"] # values 为出生了多少万人(数字瞎编的) values=[ 0, 30, 20, 10, 0, 50, 40, 10, 0, 20, 15, 15] trace0 = go.Sunburst( # 注意:每一个层级都要表示 labels=labels, parents=parents, values=values ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
市的父级是省,基于每个市的总人数可以算出省的人数,因此内层的圆对应每个省人数所占的比例。然后每个省根据比例再对应外层的圆的一片扇形区域,每个区域再根据比例划分为不同的子区域。 我们可以绘制很多层,目前有两层。但要注意的是,我们需要将每一层的对应关系都描述出来,比如市的父级是省,那么省的父级呢?这里我们假设省为最高级,那么它的父级就是空字符串,父级的值就写成 0。 然后我们改一下,我们将省的父级设置为中国。 labels=[ "河南省", "信阳市", "郑州市", "洛阳市", "山东省", "济南市", "青岛市", "烟台市", "安徽省", "凤阳市", "合肥市", "芜湖市"] parents=[ "中国", "河南省", "河南省", "河南省", "中国", "山东省", "山东省", "山东省", "中国", "安徽省", "安徽省", "安徽省"] values=[ 0, 30, 20, 10, 0, 50, 40, 10, 0, 20, 15, 15] trace0 = go.Sunburst( labels=labels, parents=parents, values=values ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
然后再来关注 values 里面的几个 0,它们表示啥含义呢? labels=[ "河南省", "信阳市", "郑州市", "洛阳市", "山东省", "济南市", "青岛市", "烟台市", "安徽省", "凤阳市", "合肥市", "芜湖市"] parents=[ "中国", "河南省", "河南省", "河南省", "中国", "山东省", "山东省", "山东省", "中国", "安徽省", "安徽省", "安徽省"] # 河南省、山东省分别还有 10 万人、20 万人没有统计 # 这些人可能来自于别的市 values=[ 10, 30, 20, 10, 20, 50, 40, 10, 0, 20, 15, 15] trace0 = go.Sunburst( labels=labels, parents=parents, values=values, ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
旭日图的本质是树状关系,与树图是等价的,因此也被称为极坐标下的矩形树图。它可以在承载大量数据的同时,清晰的显示数据间的结构关系。在许多工具中,旭日图被赋予交互功能,方便读图者自行探索。如支持鼠标悬浮高亮、筛选、显示当前层级等等。 桑基图 桑基图 (Sankey Diagram),是一种表现流程的示意图,用于描述一组值到另一组值的流向,分支的宽度对应了数据流量的大小。 1869年,查尔斯米纳德绘制了1812年拿破仑征俄图,描绘了拿破仑大军在东进时,兵力是如何一步步削弱的,这也是目前公认较早的桑基图。
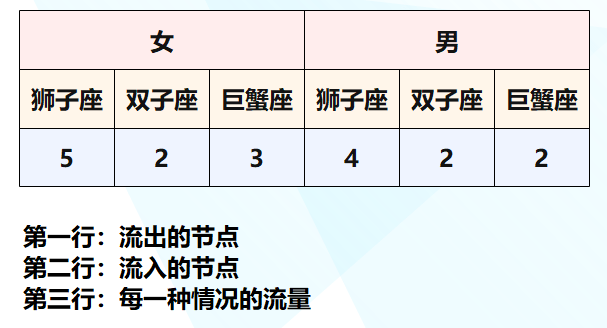
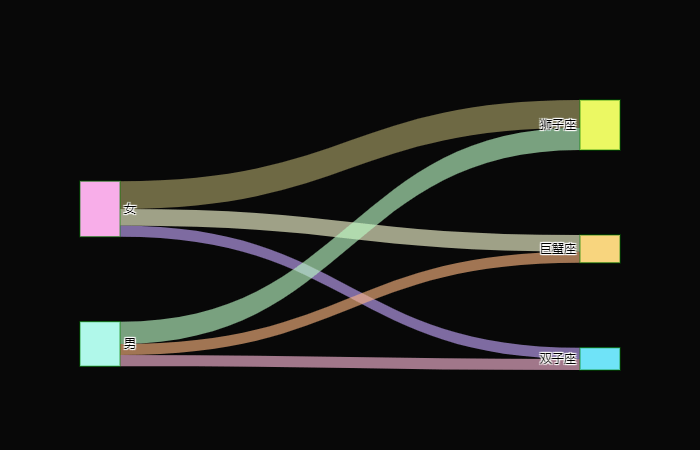
假设有上面这种数据,我们来看看如何将它绘制成桑基图。 trace0 = go.Sankey( node={ "pad": 85, "thickness": 40, "line": { "color": "green", "width": 0.5}, "label": [ "女", "男", "狮子座", "双子座", "巨蟹座"], "color": [ "#f8ade8", "#aff8e9", "#eaf863", "#6fe2f8", "#f8d47d"], }, link={ # source 和 target 中的元素都表示上面 label 的索引 # 两者都是一一对应的,比如只看三个数组中的第一个元素 # (0, 2, 5) 就表示 ("女", "狮子座", 5) "source": [ 0, 0, 0, 1, 1, 1], "target": [ 2, 3, 4, 2, 3, 4], "value": [ 5, 2, 3, 4, 2, 2], "color": [ "rgba(172, 163, 105, 0.6)", "rgba(196, 166, 255, 0.6)", "rgba(252, 255, 212, 0.6)", "rgba(188, 255, 199, 0.6)", "rgba(255, 185, 217, 0.6)", "rgba(255, 182, 129, 0.6)"], }, ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
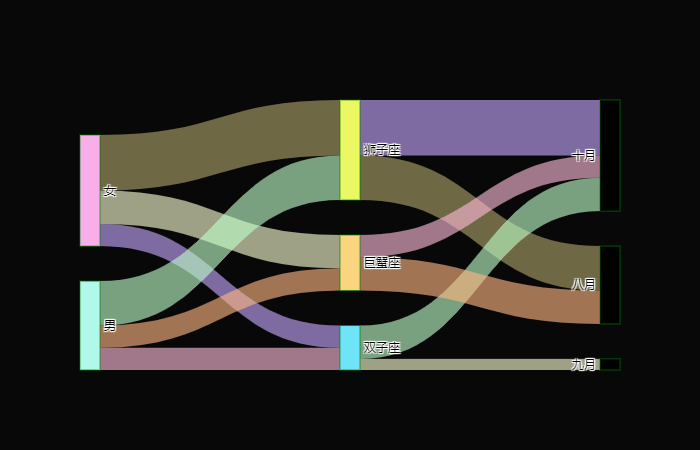
绘制出来就长这个样子,我们来解释一下这张图。 Sankey 里面的参数 node 就表示这几个节点,键 "pad" 表示节点之间的距离,"thickness" 表示节点宽度,"line" 表示线条,"label" 表示节点的名称,"color" 表示节点的颜色。 参数 link 表示节点之间的连接情况,source 和 target 决定了流向,value 表示每个方向的流量,color 表示颜色。 当然我们这里只有一个流出和一个流入,但其实一个流入还可以作为下一个流入的流出,比如:
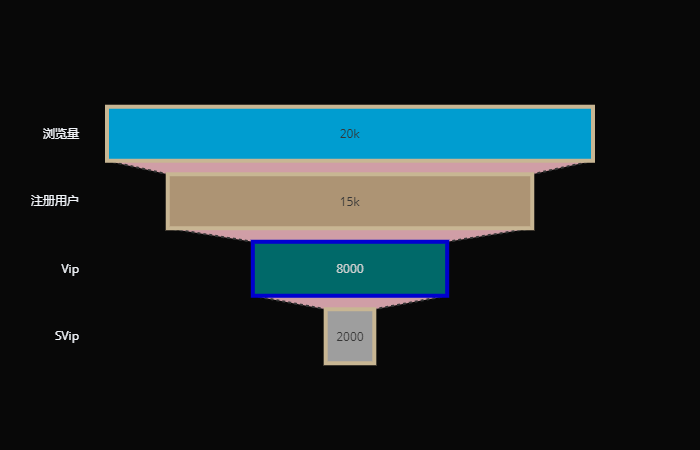
以上便是桑基图,适合表现分配情况、归类情况,以及变化和流动情况。 漏斗图 漏斗图,形如漏斗,用于单流程分析,在开始和结束之间由N个流程环节组成。漏斗图的起始总是100%,并在各个环节依次减少,每个环节用一个梯形来表示,整体形如漏斗。一般来说,所有梯形的高度应是一致的,这会有助人们辨别数值间的差异。 trace0 = go.Funnel( y = [ "浏览量", "注册用户", "Vip", "SVip"], x = [ 20000, 15000, 8000, 2000], # 以前指定透明度的时候,是通过 marker 参数实现的 # 在 marker 参数里面指定一个 "opacity" # 但有的图表不行,需要单独使用 opacity 参数 opacity = 0.8, marker={ # 漏斗每部分的颜色 "color": [ "deepskyblue", "tan", "teal", "silver"], # 轮廓 "line": { "width": 4, "color": [ "wheat", "wheat", "blue", "wheat"] } }, # 漏斗之间的连接部分 connector={ "fillcolor": "pink", "line": { "width": 2, "dash": "dot"}} ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
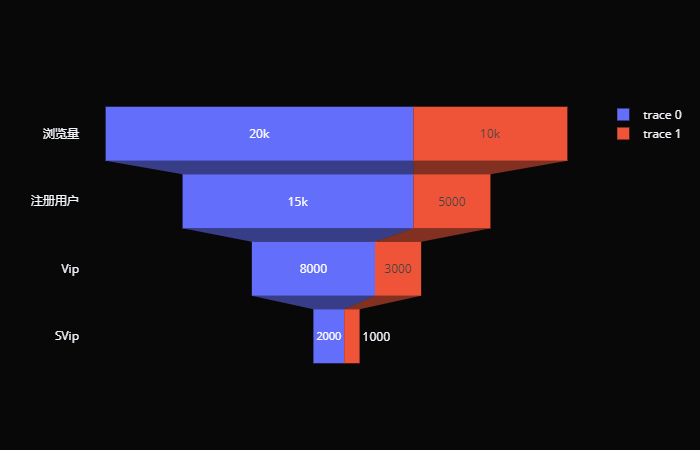
同样的,你也可以绘制多个漏斗图,比如:
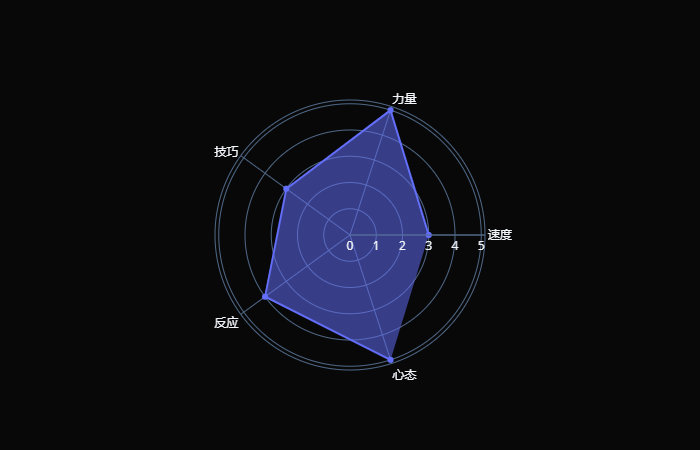
需要注意的是,漏斗图的各个环节,有逻辑上的顺序关系,同时漏斗图的所有环节的流量都应该使用同一个度量。漏斗图最适宜用来呈现业务流程的推进情况,如用户的转化情况、订单的处理情况、招聘的录用情况等。通过漏斗图,可以较直观的看出流程中各部分的占比、发现流程中的问题,进而做出决策。 雷达图 雷达图是一种显示多变量数据的图形方法,通常从同一中心点开始等角度间隔地射出三个以上的轴,每个轴代表一个定量变量,各轴上的点依次连接成线或几何图形。 雷达图可以用来在变量间进行对比,或者查看变量中有没有异常值。另外,多幅雷达图之间或者雷达图的多层数据线之间,还可以进行总体数值情况的对比。 trace0 = go.Scatterpolar( r=[ 3, 5, 3, 4, 5], theta=[ "速度", "力量", "技巧", "反应", "心态"], fill= 'toself' ) fig = go.Figure(data=[trace0], layout={ "template": "plotly_dark"}) fig
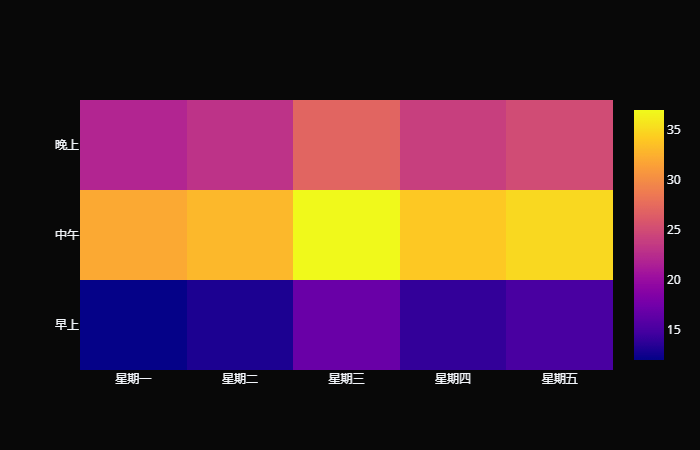
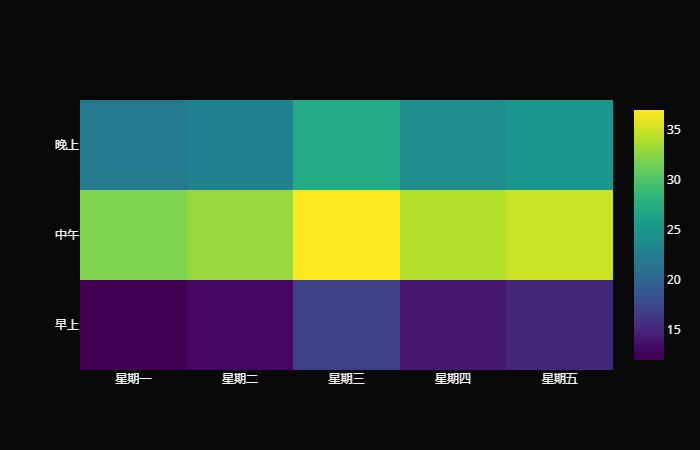
使用雷达图时,特征类别不能过多,并且特征之间要归一化,或者按照统一标准来标准化。 热力图 热力图是一种通过对色块着色来显示数据的统计图表,绘图时需指定颜色映射的规则。例如,较大的值由较深的颜色表示,较小的值由较浅的颜色表示;或者较大的值由较暖的颜色表示,较小的值由较冷的颜色表示等等。 trace0 = go.Heatmap( x=[ "星期一", "星期二", "星期三", "星期四", "星期五"], y=[ "早上", "中午", "晚上"], z=[ # 星期一到星期五的早上 [ 12, 13, 17, 14, 15], # 星期一到星期五的中午 [ 32, 33, 37, 34, 35], # 星期一到星期五的晚上 [ 22, 23, 27, 24, 25], ] ) fig = go.Figure( data=[trace0], layout={ "template": "plotly_dark"}, ) fig
我们还可以调整颜色: trace0 = go.Heatmap( x=[ "星期一", "星期二", "星期三", "星期四", "星期五"], y=[ "早上", "中午", "晚上"], z=[[ 12, 13, 17, 14, 15], [ 32, 33, 37, 34, 35], [ 22, 23, 27, 24, 25], ], colorscale = 'Viridis' )
通过指定 colorscale,即可选择不同风格的色块,它的可选值如下:
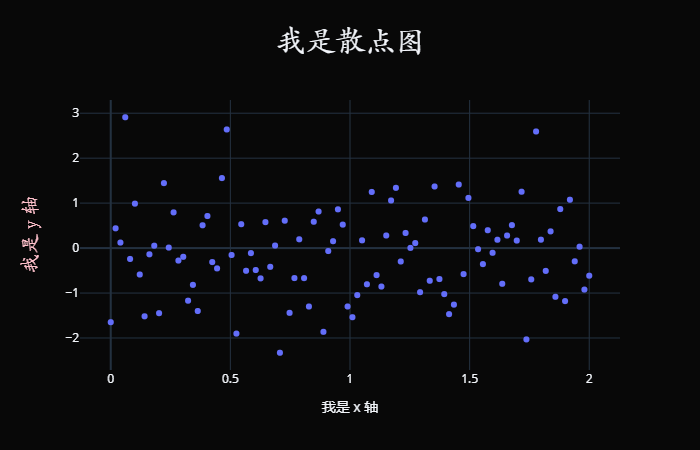
从数据结构来划分,热力图需要 2 个分类字段和 1 个数值字段,分类字段确定 x、y 轴,将图表划分为规整的矩形块,而数值字段决定了矩形块的颜色。 热力图适合用于查看总体的情况、发现异常值、显示多个变量之间的差异,以及检测它们之间是否存在任何相关性。它的优势在于空间利用率高,可以容纳较为庞大的数据。热力图不仅有助于发现数据间的关系、找出极值,也常用于刻画数据的整体样貌,方便在数据集之间进行比较。 但热力图也有缺陷,尽管热力图能够容纳较多的数据,然而人们很难将其中的色块转换为精确的数字。因此当需要清楚知道数值的时候,可能需要额外的标注,plotly 支持这一点,当把鼠标放到色块上时,会显示相应的数值。 其它轨迹 我们上面已经介绍了工作中常用的图表,如果你还想知道更多的图表,可以查看 plotly 官网。 https://plotly.com/python/ https://plotly.com/python/ 画布属性 layout 重点来了,我们创建画布的时候用的是 Figure 类,它里面接收两个参数。第一个参数 data 负责接收轨迹,第二个参数 layout 负责调整画布属性。我们创建完画布之后,也可以通过 fig.data 或 fig.layout 拿到相应的轨迹和画布。 然后我们来看看画布都支持哪些属性。 title 标题,可以是一个字符串,也可以是一个字典。 layout = { "title": "这是标题" } # 或者传递一个字典,指定标题的同时 # 还可以指定字体、位置 layout = { "title": { "text": "这是标题", # 字体(一会单独说) "font": { "family": "STKaiti", "size": 30}, # 水平位置,0.5 表示居中 "x": 0.5} } xaxis_title、yaxis_title x 轴名称和 y 轴名称,同样支持字符串和字典。 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) trace0 = go.Scatter( x=x, y=y, mode= "markers" ) fig = go.Figure( data=[trace0], layout={ "template": "plotly_dark", "title": { "text": "我是散点图", "font": { "family": "STKaiti", "size": 30}, "x": 0.5}, "xaxis_title": "我是 x 轴", "yaxis_title": { "text": "我是 y 轴", "font": { "family": "STKaiti", "size": 20, "color": "pink"}}, } ) fig
我们看到标题和 y 轴的字体变了,但 x 轴没有变。因为 x 轴传递的字符串,它只能表示标题内容,样式则使用默认的。
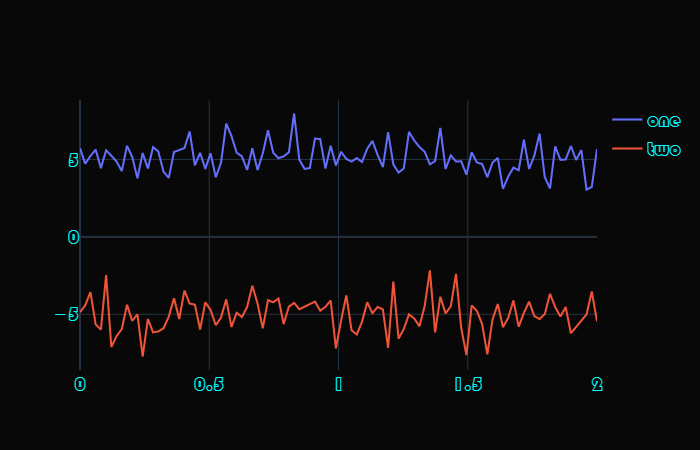
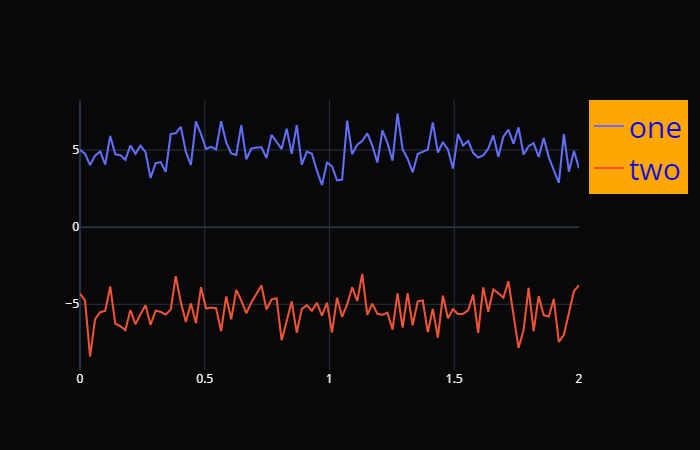
这些用表格罗列出来的,就不演示了,可以自己测试一下,看看这些参数的效果。 font 字体,和 titlefont 属性一致,通过传递一个字典来指定颜色、大小、种类等等。但 titlefont 的效果只会作用于标题,而这里的 font 会作用于所有地方,比如标题、x 轴和 y轴的名称、坐标刻度等等。 x = np.linspace( 0, 2, 100) y0 = np.random.randn( 100) + 5 y1 = np.random.randn( 100) - 5 trace0 = go.Scatter( x=x, y=y0, name= "one" ) trace1 = go.Scatter( x=x, y=y1, name= "two" ) fig = go.Figure( data=[trace0, trace1], layout={ "font": { "color": "cyan", "size": 20, "family": "stcaiyun"}, "template": "plotly_dark" } ) fig
所有能看到字的部分,其字体的颜色、大小、类型都变了。 legend 设置展示轨迹名称时的属性。 x = np.linspace( 0, 2, 100) y0 = np.random.randn( 100) + 5 y1 = np.random.randn( 100) - 5 trace0 = go.Scatter( x=x, y=y0, name= "one" ) trace1 = go.Scatter( x=x, y=y1, name= "two" ) fig = go.Figure( data=[trace0, trace1], layout={ "legend": { "bgcolor": "orange", "font": { "size": 30, "color": "blue"}}, "template": "plotly_dark" } ) fig
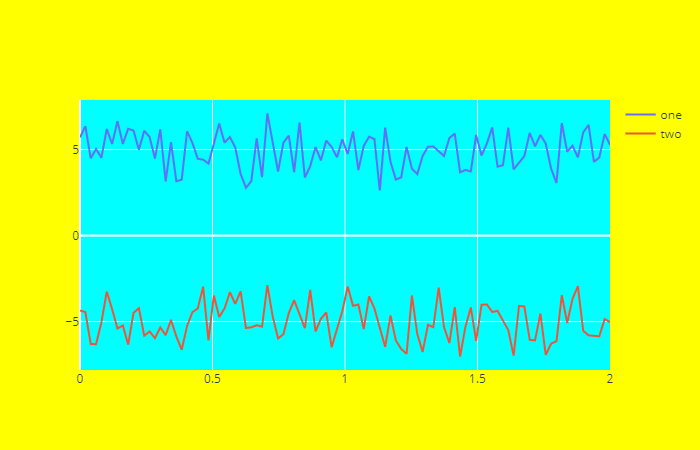
paper_bgcolor、plot_bgcolor 分别表示画布背景颜色、和图表背景颜色。 x = np.linspace( 0, 2, 100) y0 = np.random.randn( 100) + 5 y1 = np.random.randn( 100) - 5 trace0 = go.Scatter( x=x, y=y0, name= "one" ) trace1 = go.Scatter( x=x, y=y1, name= "two" ) fig = go.Figure( data=[trace0, trace1], layout={ "paper_bgcolor": "yellow", "plot_bgcolor": "cyan" } ) fig
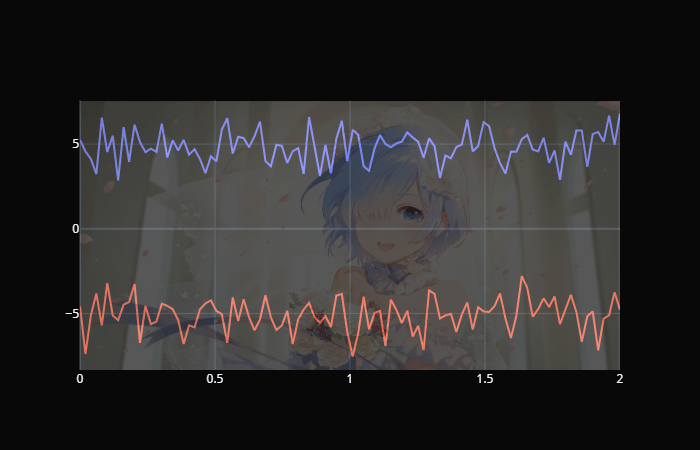
images 我个人觉得最牛的一个功能,就是可以将图片作为背景。 fromPIL importImage x = np.linspace( 0, 2, 100) y0 = np.random.randn( 100) + 5 y1 = np.random.randn( 100) - 5 # 使用 PIL 打开图片 im = Image.open( "../lemu.jpg") trace0 = go.Scatter(x=x, y=y0, name= "one") trace1 = go.Scatter(x=x, y=y1, name= "two") fig = go.Figure( data=[trace0, trace1], layout={ "images": [{ # 可以是PIL读取的Image对象,也可以是base64字符 "source": im, "sizex": 1, "sizey": 1, "yanchor": "bottom", "opacity": 0.3, }], "showlegend": False, "template": "plotly_dark" }) fig
以上就是画布 layout 支持的一些属性,但还有两个最重要没有说,就是 xaxis 和 yaxis。 xaxis 和 yaxis xaxis 和 yaxis 非常重要,关键的东西我们留到最后,由于它们支持的属性是一样的,都是坐标轴,就一起说了。首先 xaxis 和 yaxis 同样是传递给 layout 的字典里面的 key,但关键的是它们对应的 value 也是一个字典,这个字典里面同样可以支持很多的属性。 color: 颜色,针对于当前坐标轴的刻度 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) + 5 trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ "xaxis": { "color": "red"}, "template": "plotly_dark" }) fig
坐标轴刻度变成了红色。
gridcolor、gridwidth 网格线颜色和网格线宽度。 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) + 5 trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ "xaxis": { "gridwidth": 5, "gridcolor": "cyan"}, "template": "plotly_dark", }) fig
linecolor、linewidth 坐标轴线条颜色与宽度 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) + 5 trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ "xaxis": { "linewidth": 5, "linecolor": "cyan"}, "template": "plotly_dark", }) fig
rangeslider 范围滑块 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) + 5 trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ "xaxis": { "rangeslider": { "bgcolor": "cyan"}}, "template": "plotly_dark" }) fig
下方有一个滑块,可以拖动,然后显示对应的图形部分。 showgrid 是否显示网格。 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) + 5 trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ "xaxis": { "showgrid": False}, "yaxis": { "showgrid": False}, "template": "plotly_dark" }) fig
side 设置坐标轴刻度位置 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) + 5 trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ "xaxis": { "side": "top"}, "yaxis": { "side": "right"}, "template": "plotly_dark" }) fig
showline:显示线条开关; spikecolor:峰值数据颜色; tickangle:刻度倾斜角度,之前用过的。 tickprefix、ticksuffix:刻度前缀和后缀 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) + 5 trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ "xaxis": { "tickprefix": ">"}, "template": "plotly_dark" }) fig
title、titlefont 设置坐标轴名称,类似于 layout 中的 title 和 titlefont,当然坐标轴名称还可以通过 xaxis_title 和 yaxis_title 指定。 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) + 5 trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ # title 也可以是一个字典 # 在里面通过 "font" 指定字体 "xaxis": { "title": "我是 x 轴", "titlefont": { "color": "cyan", "size": 20}}, "template": "plotly_dark" }) fig
type:刻度类型 可以是 '-', 'linear', 'log', 'date', 'category', 'multicategory' 之一。 zeroline:是否显示零线、就是值全部为 0 的线 对于 xaxis 就是 y 轴,对于 yaxis 就是 x轴。 zerolinecolor、zerolinewidth 零线的颜色和宽度 x = np.linspace( 0, 2, 100) y = np.random.randn( 100) trace0 = go.Scatter(x=x, y=y) fig = go.Figure( data=[trace0], layout={ "xaxis": { "zerolinecolor": "cyan", "zerolinewidth": 5 }, "yaxis": { "zerolinecolor": "pink", "zerolinewidth": 5 }, "template": "plotly_dark" }) fig
以上就是两个坐标轴支持的属性设置,可以看到支持的属性非常多,而且都可以自定制,只不过很多我们都用不到。 小结 plotly 真的是一个绘图神器,支持大量的图表,当然我们只介绍了一部分,不过它们都是最常用的。在使用 plotly 的时候要记住轨迹和画布两个概念,我们说图表在 plotly 中就是轨迹,然后轨迹需要展示在画布上,而画布有很多属性,这些我们上面介绍的比较详细了,虽然很多都用不到。 然后就是 plotly 的图表保存问题,我这里都是直接在 jupyter 上生成,然后下载下来的。至于如何用 plotly 的 API 来生成图片,以及多图绘制,我们下一篇文章再说。 申明:本文中对一些图表所做的概念上的解析,来自于网站 "图之典" ,这是由一些爱好数据可视化的人创建的。里面对图表进行了概念上的详细描述,包括来源、适用场景、以及不适用场景等等,都做了详细的说明。如果你喜欢数据可视化,那么这个网站你一定不能错过。 申明:本文中对一些图表所做的概念上的解析,来自于网站 "图之典" ,这是由一些爱好数据可视化的人创建的。里面对图表进行了概念上的详细描述,包括来源、适用场景、以及不适用场景等等,都做了详细的说明。如果你喜欢数据可视化,那么这个网站你一定不能错过。 - EOF - 加主页君微信,不仅Python技能+1 主页君日常还会在个人微信分享 Python相关工具、资源和 精选技术文章,不定期分享一些 有意思的活动、 岗位内推以及 如何用技术做业余项目 加个微信,打开一扇窗 点击标题可跳转 1、 统计学基础知识梳理,建议收藏! 2、 Python 数据可视化的 3 大步骤,你知道吗? 3、 编译器大佬Chris Lattner全新编程语言「Mojo」:兼容Python核心功能,提速35000倍 觉得本文对你有帮助?请分享给更多人 推荐关注「Python开发者」,提升Python技能 点赞和在看就是最大的支持❤️返回搜狐,查看更多 |




【本文地址】