| 小样本多变量时间序列回归预测 | 您所在的位置:网站首页 › 线性回归时间序列分析 › 小样本多变量时间序列回归预测 |
小样本多变量时间序列回归预测
|
来讲一下实习碰到的实际问题,针对每个小样本set进行多变量的时序预测,但是每个set的样本数比较少,12-46个不等;本文尝试使用可以预测多变量的单回归器,和预测单变量的单回归器的组合,和多个回归器取均值的三种策略来寻找最优的办法 先看一下原始数据:主要关注标黄的四个变量的预测:
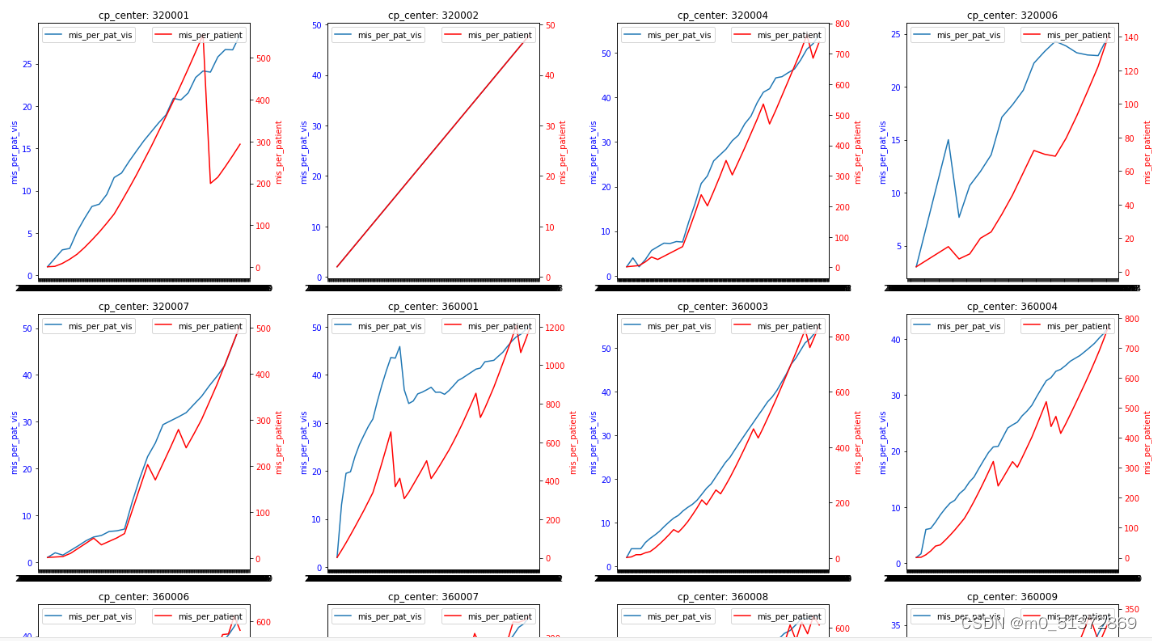
# 查看数据的基本信息,包括变量类型和空缺值情况 # 查看数据的基本信息,包括变量类型和空缺值情况 df.info() Int64Index: 1926 entries, 0 to 1926 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 cp_center 1926 non-null int64 1 ENDPOINT 1926 non-null datetime64[ns] 2 form_mis_all 1926 non-null int64 3 form_tot_all 1926 non-null int64 4 pat_vis 1926 non-null float64 5 pat 1926 non-null float64 6 mis_per_pat_vis 1926 non-null float64 7 mis_per_patient 1926 non-null float64 8 center_record 1926 non-null int64 9 max_value 1926 non-null float64 dtypes: datetime64[ns](1), float64(5), int64(4) memory usage: 165.5 KB发现有一行存在缺失值,drop一下: # 如果需要,可以查看空缺值的详细情况 df.isnull().sum() cp_center 0 ENDPOINT 0 form_mis_all 0 form_tot_all 0 pat_vis 1 pat 1 mis_per_pat_vis 1 mis_per_patient 1 center_record 0 max_value 0 dtype: int64 #删除缺失值的行 df = df.dropna()然后查看每个set的样本个数: # 统计cp_center列的取值情况 cp_center_counts = df['cp_center'].value_counts() cp_center_counts 360001 44 360003 42 360004 41 1520002 40 1520001 40 .. 8400002 12 7920005 12 8260002 12 7920008 12 1560004 12 Name: cp_center, Length: 80, dtype: int64 可视化一下看看数据的样子:#按照cp_center分组绘画mis_per_pat_vis 和mis_per_patient关于ENDPOINT列作为x轴的折线图 #按照cp_center分组绘画mis_per_pat_vis 和mis_per_patient关于ENDPOINT列作为x轴的折线图 import matplotlib.dates as mdates import math # 获取cp_center的唯一值 cp_centers = df['cp_center'].unique() # 计算需要多少行来放置所有子图 num_rows = math.ceil(len(cp_centers) / 4) # 创建一个新的Figure对象 fig, axes = plt.subplots(nrows=num_rows, ncols=4, figsize=(20, 5 * num_rows)) # 遍历每个cp_center值 for i, cp_center in enumerate(cp_centers): # 获取当前cp_center的数据 group = df[df['cp_center'] == cp_center] # 获取当前子图的轴对象 ax1 = axes[i // 4, i % 4] # 在主y轴上绘制mis_per_pat_vis ax1.plot(group['ENDPOINT'], group['mis_per_pat_vis'], label='mis_per_pat_vis') ax1.set_ylabel('mis_per_pat_vis', color='blue') ax1.tick_params(axis='y', labelcolor='blue') # 创建次y轴 ax2 = ax1.twinx() ax2.plot(group['ENDPOINT'], group['mis_per_patient'], label='mis_per_patient', color='red') ax2.set_ylabel('mis_per_patient', color='red') ax2.tick_params(axis='y', labelcolor='red') # 设置x轴日期格式 ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) ax1.xaxis.set_major_locator(mdates.DayLocator(interval=1)) # 根据需要调整间隔 # 设置标题 ax1.set_title(f'cp_center: {cp_center}') # 显示图例 ax1.legend(loc='upper left') ax2.legend(loc='upper right') # 调整子图间距 plt.tight_layout() # 显示图形 plt.show()
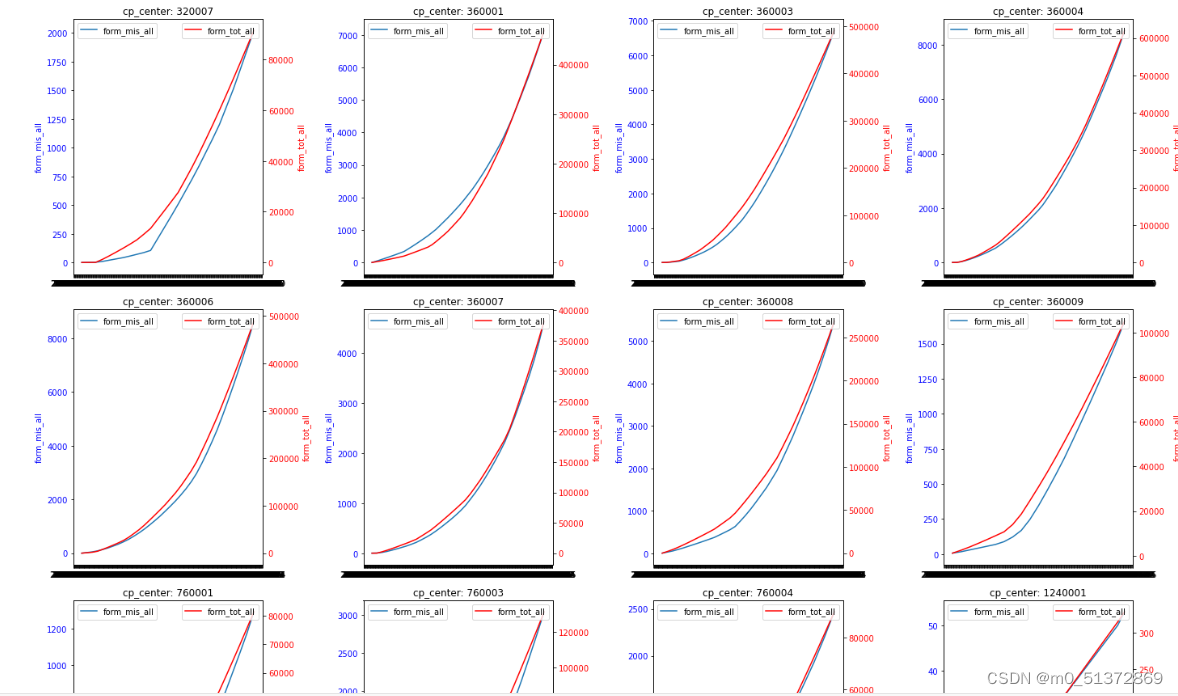
#按照cp_center分组绘画form_mis_all和form_tot_all关于ENDPOINT列作为x轴的折线图
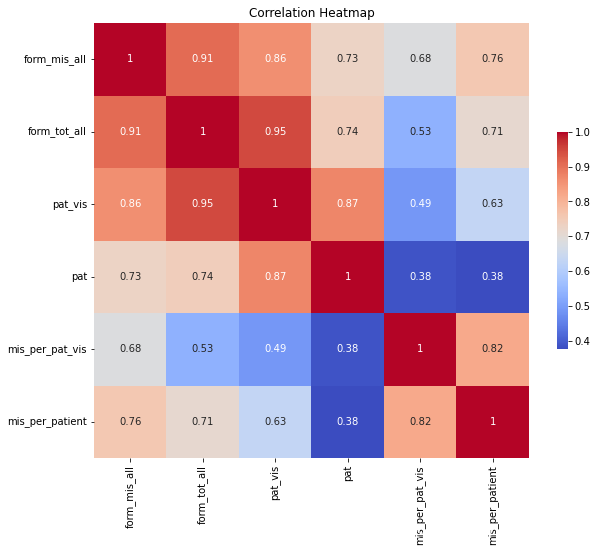
发现要预测的4个特征变量两两很相关啊,看一下热力图: import seaborn as sns # 选择要计算相关系数的列 columns_of_interest = ['form_mis_all', 'form_tot_all', 'pat_vis', 'pat', 'mis_per_pat_vis', 'mis_per_patient'] # 计算相关系数矩阵 correlation_matrix = df[columns_of_interest].corr() # 使用seaborn绘制热力图 plt.figure(figsize=(10, 8)) # 设置图形大小 sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', square=True, cbar_kws={"shrink": .5}) plt.title('Correlation Heatmap') plt.show()
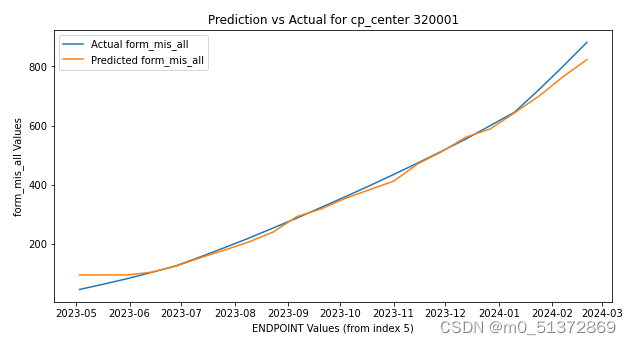
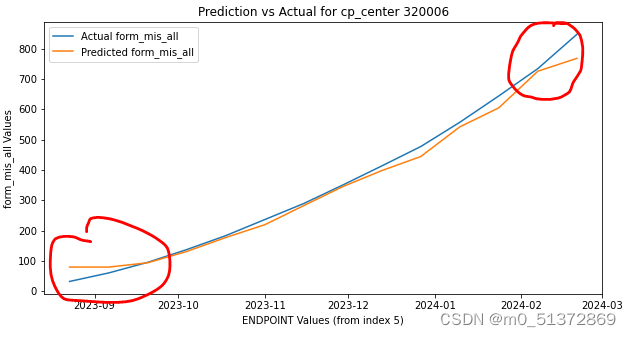
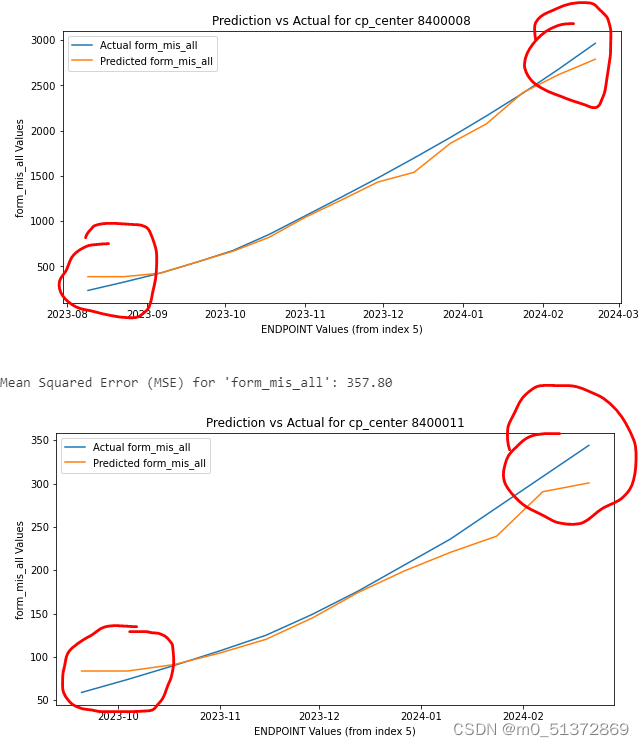
选择随机森林和梯度提升进行回归测试: 建模-预测多变量的单回归器思路是这样: 针对每个cp_center,ENDPOINT为时间日期变量,取前5个时间点的cp_center,使用form_mis_all,form_tot_all,pat_vis,pat四个特征变量来预测下一个时间点的form_mis_all,form_tot_all,pat_vis,pat的变量; 先封装好如下功能函数:#画图函数 def plot_prediction_vs_actual(model, X, cp_center_data, cp_center): # 定义创建时间序列数据集的函数 def create_dataset(data, seq_length=5): # 定义训练和评估模型的函数 def train_and_evaluate_model(cp_center_data,base_model): # 运行模型并输出评估信息的dataframe def create_metrics_df(df, features): #封装好的函数 import numpy as np import pandas as pd from sklearn.multioutput import MultiOutputRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score def plot_prediction_vs_actual(model, X, cp_center_data, cp_center): # 使用整个训练集来获取预测值的'Label_want_show' 列 Label_want_show = "form_mis_all" Label_want_show_num = 0 Y_predict = model.predict(X)[:, Label_want_show_num] # 提取 'form_mis_all' 列的实际值 actual_values = cp_center_data[Label_want_show][5:].values index = cp_center_data['ENDPOINT'][5:].values # 计算RMSE rmse = np.sqrt(mean_squared_error(actual_values, Y_predict)) # 输出MSE #print(f"RMSEfor '{Label_want_show}': {rmse:.2f}") # 绘制折线图 plt.figure(figsize=(10, 5)) plt.plot(index, actual_values, label=f'Actual {Label_want_show}') plt.plot(index, Y_predict, label=f'Predicted {Label_want_show}') plt.title(f'Prediction vs Actual for cp_center {cp_center}') plt.xlabel('ENDPOINT Values (from index 5)') plt.ylabel(f'{Label_want_show} Values') plt.legend() plt.show() # 定义创建数据集的函数 def create_dataset(data, seq_length=5): X, Y = [], [] data = data[['form_mis_all', 'form_tot_all', 'pat_vis', 'pat']] for i in range(len(data) - seq_length): sequence_X = data.iloc[i:(i + seq_length)] X.append(sequence_X.values.flatten()) sequence_Y = data.iloc[i + seq_length] Y.append(sequence_Y.values.flatten()) X, Y = np.array(X), np.array(Y) return X, Y # 定义训练和评估模型的函数 def train_and_evaluate_model(cp_center_data,base_model): # 创建训练和测试数据集 X, Y = create_dataset(cp_center_data, seq_length=5) X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=42) # 使用MultiOutputRegressor包装器 model = MultiOutputRegressor(base_model) # 训练模型 model.fit(X_train, Y_train) # 预测 predictions = model.predict(X_test) # 计算每一列的MSE和RMSE mse_per_column, rmse_per_column = [], [] for i in range(Y_test.shape[1]): Y_true_column = Y_test[:, i] Y_pred_column = predictions[:, i] column_mse = mean_squared_error(Y_true_column, Y_pred_column) column_rmse = np.sqrt(column_mse) mse_per_column.append(column_mse) rmse_per_column.append(column_rmse) #绘图: #plot_prediction_vs_actual(model, X, cp_center_data, cp_center) return model, mse_per_column, rmse_per_column # 运行模型并输出评估信息的dataframe def create_metrics_df(df, features): models = {} for cp_center in df["cp_center"].unique(): cp_center_data = df[df["cp_center"] == cp_center] model, mse, rmse = train_and_evaluate_model(cp_center_data,base_model) # 保存模型和评估信息 models[cp_center] = {'model': model, 'mse': mse, 'rmse': rmse} # 存储预测集的评估信息 metrics_df_test = pd.DataFrame() for cp_center, info in models.items(): rmse_values = [info['rmse'][i] for i in range(len(features))] rmse_dict = { 'cp_center': cp_center, 'RMSE_form_mis_all': round(rmse_values[0], 2), 'RMSE_form_tot_all': round(rmse_values[1], 2), 'RMSE_pat_vis': round(rmse_values[2], 2), 'RMSE_pat': round(rmse_values[3], 2) } # 将字典添加到DataFrame中 metrics_df_test = metrics_df_test.append(rmse_dict, ignore_index=True) # 假设 new_row 是一个包含新行数据的字典或者是一个 DataFrame new_row = {'cp_center': "平均", 'RMSE_form_mis_all': round(metrics_df_test.RMSE_form_mis_all.mean(),2),'RMSE_form_tot_all': round(metrics_df_test.RMSE_form_tot_all.mean(),2), 'RMSE_pat_vis':round(metrics_df_test.RMSE_pat_vis.mean(),2),'RMSE_pat':round(metrics_df_test.RMSE_paan(),2)} # 使用 append 来追加行,并赋值回 df metrics_df_test = metrics_df_test.append(new_row, ignore_index=True) return metrics_df_test,new_row # Excel文件路径 excel_file_path = r'C:\Users\U1031084\vscode\long term task\2024-3-2-yuanjiang-时序预测\Datapoint missing per site-critical datapoint FEB2024.xlsx' # 指定要读取的Sheet名称 sheet_name = 'Datapoint missing per site-crit' # 使用pandas的read_excel函数导入指定Sheet的Excel文件 df = pd.read_excel(excel_file_path, sheet_name=sheet_name) #删除缺失值的行 df = df.dropna() features = ['form_mis_all', 'form_tot_all', 'pat_vis', 'pat']上述代码是封装好的函数,可以使用了model = MultiOutputRegressor(base_model)来套学习器;这样无论是只能预测单变量的,还是可以预测多变量的,都可以塞进去训练,然后输出RMSE的表格; 随机森林回归 base_model = RandomForestRegressor(n_estimators=100, n_jobs=-1, random_state=42) # 调用函数创建和填充评估信息DataFrame metrics_df,new_row = create_metrics_df(df, features) new_row直接调用上述封装好的函数,塞进去basemodel为随机森林即可,结果如下: {'cp_center': '平均', 'RMSE_form_mis_all': 87.56, 'RMSE_form_tot_all': 5288.03, 'RMSE_pat_vis': 3.14, 'RMSE_pat': 0.4} 展平技巧其中:create_dataset()函数生成时间序列数据,用了展平技巧 create_dataset函数用来生成5个时间步的4个特征变量的被预测数据和1个时间步的4个特征变量的预测数据,这里用了一个技巧,因为随机森林和其他机器学习模型的回归不能输入三维数据然后输出三维数据,所以需要把5个时间步的4个特征变量的被预测数据展平:取5个时间步的话,时间序列数据的X长度就是lenth-seqence_lenth
其中:plot_prediction_vs_actual()函数用来每次set训练好model后针对某一个特征绘画预测曲线和原始曲线的对比: 可以看到,我的随机森林回归模型存在一个很明显的前翘和后压的特征,以第一个特征变量form_mis_all为例,从每个set的第6个值开始,蓝色是真实值,橙色是预测值:
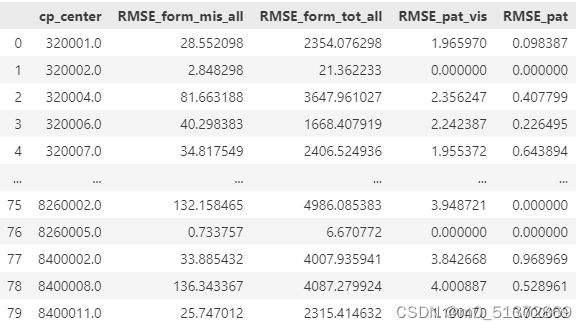
在model部分套一个MultiOutputRegressor,就可以尝试其他单一变量回归模型实现多变量回归预测输出: from sklearn.linear_model import LinearRegression # 假设我们有一个LinearRegression模型 base_model = LinearRegression() # 调用函数创建和填充评估信息DataFrame metrics_df,new_row = create_metrics_df(df, features) new_row from sklearn.ensemble import GradientBoostingRegressor # 创建一个基本的回归模型 base_model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42) # 调用函数创建和填充评估信息DataFrame metrics_df,new_row = create_metrics_df(df, features) new_row from sklearn.svm import SVR # 假设我们有一个SVR模型 base_model = SVR(kernel='rbf', C=1.0, epsilon=0.2) # 调用函数创建和填充评估信息DataFrame metrics_df,new_row = create_metrics_df(df, features) new_row #输出: {'cp_center': '平均', 'RMSE_form_mis_all': 34.66, 'RMSE_form_tot_all': 1489.92, 'RMSE_pat_vis': 3.83, 'RMSE_pat': 1.59} {'cp_center': '平均', 'RMSE_form_mis_all': 107.16, 'RMSE_form_tot_all': 6101.83, 'RMSE_pat_vis': 3.14, 'RMSE_pat': 0.38} {'cp_center': '平均', 'RMSE_form_mis_all': 777.57, 'RMSE_form_tot_all': 45896.42, 'RMSE_pat_vis': 16.74, 'RMSE_pat': 0.65} 评估指标的解释:MSE和RMSE针对多变量的MSE存在一个尺度问题,我在上篇文章已经提到,这里为了避免未作标准化产生的尺度问题,我希望针对4个特征变量分别输出RMSE作为评估指标 输出示例:
但是三个模型的优劣如何比较呢?四个指标都有自己尺度的RMSE,这就涉及到了多变量预测的模型比较问题,这个问题下一篇再说 参考链接:多元输出回归模型_multioutputregressor-CSDN博客 归一与反归一及哪些模型需要归一化: 【Python机器学习系列】一文彻底搞懂机器学习中的归一化与反归一化问题_归一化之后的高斯过程回归得到的标准差怎么逆归一化-CSDN博客相关 |

【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |