| 【2022最新版】数据结构+算法面试题总结(9+20道题含答案解析) | 您所在的位置:网站首页 › 算法面试精选100题 › 【2022最新版】数据结构+算法面试题总结(9+20道题含答案解析) |
【2022最新版】数据结构+算法面试题总结(9+20道题含答案解析)
|
文章目录
1、栈(stack)2、队列(queue)3、链表(Link)4、散列表(Hash Table)5、排序二叉树6、 前缀树7、红黑树8、B-TREE9、位图
算法面试题1、数据里有{1,2,3,4,5,6,7,8,9},请随机打乱顺序,生成一个新的数组(请以代码实现)2、写出代码判断一个整数是不是2的阶次方(请代码实现,谢绝调用API方法)3、假设今日是2015年3月1日,星期日,请算出13个月零6天后是星期几,距离现在多少天(请用代码实现,谢绝调用 API方法)4、有两个篮子,分别为A 和 B,篮子A里装有鸡蛋,篮子B里装有苹果,请用面向对象的思想实现两个篮子里的物品交换(请用代码实现)5、二分查找6、冒泡排序算法7、插入排序算法8、快速排序算法9、希尔排序算法10、归并排序算法11、桶排序算法12、基数排序算法13、剪枝算法14、回溯算法15、最短路径算法16、最小生成树算法17、AES18、RSA19、CRC20、MD5
总结
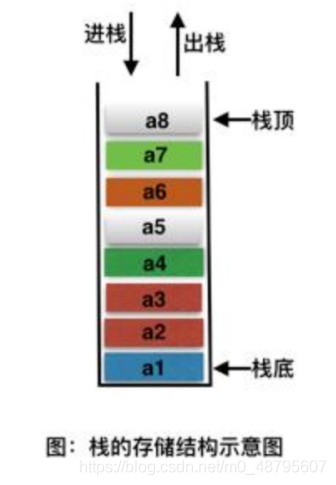
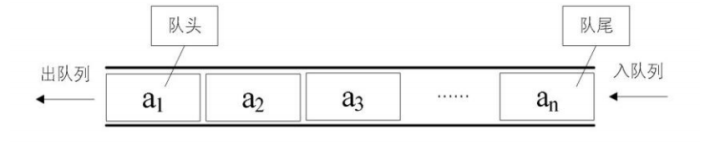
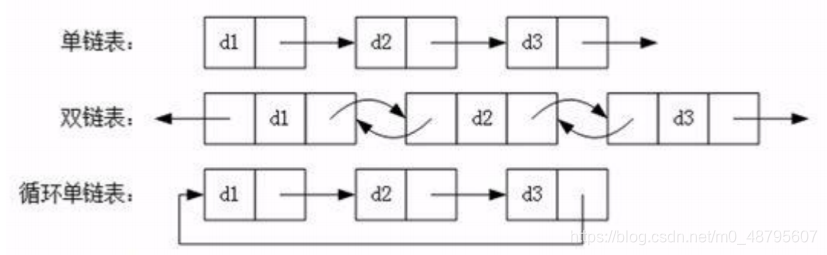
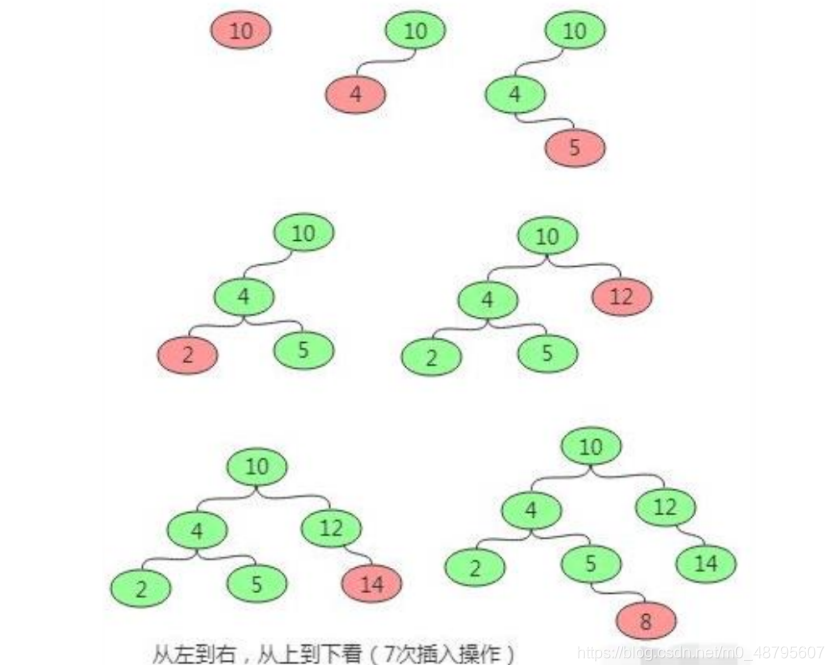
最近面试的小伙伴很多,对此我整理了一份Java面试题手册:基础知识、JavaOOP、Java集合/泛型面试题、Java异常面试题、Java中的IO与NIO面试题、Java反射、Java序列化、Java注解、Java多线程&并发、JVM、Mysql、Redis、Memcached、MongoDB、Spring、SpringBoot、SpringCloud、RabbitMQ、Dubbo、MyBatis、ZooKeeper、数据结构、算法、Elasticsearch、Kafka、微服务、Linux等等。可以分享给大家学习。【持续更新中】 一键获取数据结构与算法面试题总结 序号内容地址链接1【2022最新版】JavaOOP面试题总结https://blog.csdn.net/m0_58479954/article/details/1247105802【2022最新版】Java基础面试题总结https://blog.csdn.net/m0_58479954/article/details/1247141243【2022最新版】多线程&并发面试题总结https://blog.csdn.net/m0_58479954/article/details/1247212094【2022最新版】JVM面试题总结https://blog.csdn.net/m0_58479954/article/details/1247411145【2022最新版】Mysql面试题总结https://blog.csdn.net/m0_58479954/article/details/1247413316【2022最新版】Redis面试题总结https://blog.csdn.net/m0_58479954/article/details/1247903497【2022最新版】Memcached面试题总结https://blog.csdn.net/m0_58479954/article/details/1248260388【2022最新版】MongoDB面试题总结https://blog.csdn.net/m0_58479954/article/details/1248518959【2022最新版】Spring面试题总结https://blog.csdn.net/m0_58479954/article/details/12485200810【2022最新版】Spring Boot面试题总结https://blog.csdn.net/m0_58479954/article/details/12485215811【2022最新版】Spring Cloud面试题总结https://blog.csdn.net/m0_58479954/article/details/12485230812【2022最新版】RabbitMQ面试题总结https://blog.csdn.net/m0_58479954/article/details/12485238613【2022最新版】Dubbo面试题总结https://blog.csdn.net/m0_58479954/article/details/12485245914【2021最新版】MyBatis面试题总结https://blog.csdn.net/m0_58479954/article/details/12485256015【2022最新版】ZooKeeper面试题总结https://blog.csdn.net/m0_58479954/article/details/12498293516【2022最新版】数据结构面试题总结https://blog.csdn.net/m0_58479954/article/details/12498314717【2022最新版】算法面试题总结https://blog.csdn.net/m0_58479954/article/details/12498314718【2022最新版】Elasticsearch面试题总结https://blog.csdn.net/m0_58479954/article/details/12498350319【2022最新版】Kafka面试题总结https://blog.csdn.net/m0_58479954/article/details/12498372120【2022最新版】微服务面试题总结https://blog.csdn.net/m0_58479954/article/details/12498404921【2022最新版】Linux面试题总结https://blog.csdn.net/m0_58479954/article/details/125662548 1、栈(stack)答: 栈( stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈顶(top)。它是后进先出(LIFO)的。对栈的基本操作只有 push(进栈)和 pop(出栈)两种,前者相当于插入,后者相当于删除最后的元素。 答: 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。 答: 链表是一种数据结构,和数组同级。比如, Java中我们使用的ArrayList,其实现原理是数组。而LinkedList的实现原理就是链表了。链表在进行循环遍历时效率不高,但是插入和删除时优势明显。 答: 散列表(Hash table,也叫哈希表)是一种查找算法,与链表、树等算法不同的是,散列表算法在查找时不需要进行一系列和关键字(关键字是数据元素中某个数据项的值,用以标识一个数据元素)的比较操作。 散列表算法希望能尽量做到不经过任何比较,通过一次存取就能得到所查找的数据元素,因而必须要在数据元素的存储位置和它的关键字(可用key表示)之间建立一个确定的对应关系,使每个关键字和散列表中一个唯一的存储位置相对应。因此在查找时,只要根据这个对应关系找到给定关键字在散列表中的位置即可。这种对应关系被称为散列函数(可用h(key)表示)。 用的构造散列函数的方法有: 1) 直接定址法: 取关键字或关键字的某个线性函数值为散列地址。 即: h(key) = key或h(key) = a * key + b, 其中a和b为常数。 (2) 数字分析法 (3) 平方取值法:取关键字平方后的中间几位为散列地址。 (4) 折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址。 (5) 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址, 即: h(key) = key MOD p p ≤ m (6) 随机数法:选择一个随机函数,取关键字的随机函数值为它的散列地址, 即: h(key) = random(key) 5、排序二叉树答: 首先如果普通二叉树每个节点满足:左子树所有节点值小于它的根节点值,且右子树所有节点值大于它的根节点值,则这样的二叉树就是排序二叉树。 插入操作 首先要从根节点开始往下找到自己要插入的位置(即新节点的父节点);具体流程是:新节点与当前节点比较,如果相同则表示已经存在且不能再重复插入;如果小于当前节点,则到左子树中 寻找,如果左子树为空则当前节点为要找的父节点,新节点插入到当前节点的左子树即可;如果大于当前节点,则到右子树中寻找,如果右子树为空则当前节点为要找的父节点,新节点插入到当前节点的右子树即可。 删除操作主要分为三种情况, 即要删除的节点无子节点,要删除的节点只有一个子节点,要删除的节点有两个子节点。 5、排序二叉树 对于要删除的节点无子节点可以直接删除,即让其父节点将该子节点置空即可。 对于要删除的节点只有一个子节点,则替换要删除的节点为其子节点。 对于要删除的节点有两个子节点, 则首先找该节点的替换节点(即右子树中最小的节点),接着替换要删除的节点为替换节点,然后删除替换节点。 查找操作的主要流程为:先和根节点比较,如果相同就返回, 如果小于根节点则到左子树中归查找,如果大于根节点则到右子树中递归查找。因此在排序二叉树中可以很容易获取最大(最右最深子节点)和最小(最左最深子节点)值 6、 前缀树答: 前缀树(Prefix Trees 或者 Trie)与树类似,用于处理字符串相关的问题时非常高效。它可以实现快速检索,常用于字典中的单词查询,搜索引擎的自动补全甚至 IP 路由。 下图展示了“top”, “thus”和“their”三个单词在前缀树中如何存储的:
答: 红黑树的特性 (1)每个节点或者是黑色,或者是红色。 (2)根节点是黑色。 (3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL 或NULL)的叶子节点! (4)如果一个节点是红色的,则它的子节点必须是黑色的。 (5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。 左旋 对 x 进行左旋,意味着,将“x 的右孩子”设为“x 的父亲节点”;即,将 x 变成了一个左节点(x成了为 z 的左孩子)!。 因此,左旋中的“左”,意味着“被旋转的节点将变成一个左节点”。
第一步: 将红黑树当作一颗二叉查找树,将节点插入。 第二步:将插入的节点着色为"红色"。 根据被插入节点的父节点的情况,可以将"当节点 z 被着色为红色节点,并插入二叉树"划分为三种情况来处理。 ① 情况说明:被插入的节点是根节点。 处理方法:直接把此节点涂为黑色。 ② 情况说明:被插入的节点的父节点是黑色。 处理方法:什么也不需要做。节点被插入后,仍然是红黑树。 ③ 情况说明:被插入的节点的父节点是红色。这种情况下,被插入节点是一定存在非空祖父节点的;进一步的讲,被插入节点也一定存在叔叔节点(即使叔叔节点为空,我们也视之为存在,空节点本身就是黑色节点)。理解这点之后,我们依据"叔叔节点的情况",将这种情况进一步划分为 3种情况(Case) 删除 第一步:将红黑树当作一颗二叉查找树, 将节点删除。 这和"删除常规二叉查找树中删除节点的方法是一样的"。分 3 种情况: ① 被删除节点没有儿子,即为叶节点。那么,直接将该节点删除就 OK 了。 ② 被删除节点只有一个儿子。那么,直接删除该节点,并用该节点的唯一子节点顶替它的位置。 ③ 被删除节点有两个儿子。那么,先找出它的后继节点;然后把“它的后继节点的内容”复制给“该节点的内容”;之后,删除“它的后继节点”。 第二步:通过"旋转和重新着色"等一系列来修正该树,使之重新成为一棵红黑树。 因为"第一步"中删除节点之后,可能会违背红黑树的特性。所以需要通过"旋转和重新着色"来修正该树,使之重新成为一棵红黑树。 选择重着色 3 种情况。 ① 情况说明: x 是“红+黑”节点。 处理方法:直接把 x 设为黑色,结束。此时红黑树性质全部恢复。 ② 情况说明: x 是“黑+黑”节点,且 x 是根。 处理方法:什么都不做,结束。此时红黑树性质全部恢复。 ③ 情况说明: x 是“黑+黑”节点,且 x 不是根。 处理方法:这种情况又可以划分为 4 种子情况。这 4 种子情况如下表所示: 代码实现: https://www.cnblogs.com/skywang12345/p/3624343.html 8、B-TREE答: B-tree 又叫平衡多路查找树。一棵 m 阶的 B-tree (m 叉树)的特性如下(其中 ceil(x)是一个取上限的函数) : 树中每个结点至多有 m 个孩子; 除根结点和叶子结点外,其它每个结点至少有有 ceil(m / 2)个孩子; 若根结点不是叶子结点,则至少有 2 个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点); 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询失败的结点,实际上这些结点不存在,指向这些结点的指针都为 null); 5. 每个非终端结点中包含有 n 个关键字信息: (n, P0, K1, P1, K2, P2, …, Kn, Pn)。其中: a) Ki (i=1…n)为关键字,且关键字按顺序排序 K(i-1)< Ki。 b) Pi 为指向子树根的接点,且指针 P(i-1)指向子树种所有结点的关键字均小于 Ki,但都大于 K(i-1)。 c) 关键字的个数 n 必须满足: ceil(m / 2)-1 = 12) { if (((year + 1) % 4 == 0 && (year + 1) % 100 != 0)||(year + 1) % 400 == 0) { sum += 366 + newDay; for(int i = 0;i < newMonth - 12;i++) { sum += monthday1[month + i]; } } else { sum += 365 + newDay; for(int i = 0;i < newMonth - 12;i++) { sum += monthday1[month + i]; } } }else {for(int i = 0;i < newMonth;i++) { sum += monthday1[month + i]; }sum += newDay; }return week[sum%7]; }public static void main(String[] args) { Scanner scanner = new Scanner(System.in); System.out.println("请输入当前年份"); int year = scanner.nextInt(); System.out.println("请输入当前月份"); int month = scanner.nextInt(); System.out.println("请输入当前天数"); int day = scanner.nextInt(); System.out.println("请输入当前是星期几:以数字表示,如:星期天 为 0"); int index = scanner.nextInt(); System.out.println("今天是:" + year + "-" + month + "-" + day + " " + week[index]); System.err.println("请输入相隔月份"); int newMonth = scanner.nextInt(); System.out.println("请输入剩余天数"); int newDay = scanner.nextInt(); System.out.println("经过" + newMonth + "月" + newDay + "天后,是" + distance(year,month,day,newMonth,newDay)); } } 4、有两个篮子,分别为A 和 B,篮子A里装有鸡蛋,篮子B里装有苹果,请用面向对象的思想实现两个篮子里的物品交换(请用代码实现) 答: //面向对象思想实现篮子物品交换 public class Demo5 { public static void main(String[] args) { //创建篮子 Basket A = new Basket("A"); Basket B = new Basket("B"); //装载物品 A.load("鸡蛋"); B.load("苹果"); //交换物品 A.change(B); A.show(); B.show(); } }class Basket{ public String name; //篮子名称 private Goods goods; //篮子中所装物品 public Basket(String name) { // TODO Auto-generated constructor stub this.name = name; System.out.println(name + "篮子被创建"); } //装物品函数 public void load(String name) { goods = new Goods(name); System.out.println(this.name + "装载了" + name + "物品"); }public void change(Basket B) { System.out.println(this.name + " 和 " + B.name + "中的物品发生了交换"); String tmp = this.goods.getName(); this.goods.setName(B.goods.getName()); B.goods.setName(tmp); }public void show() { System.out.println(this.name + "中有" + goods.getName() + "物品"); } }class Goods{ private String name; //物品名称 public String getName() { return name; }public void setName(String name) { this.name = name; }public Goods(String name) { // TODO Auto-generated constructor stub this.name = name; } } 5、二分查找答: 又叫折半查找,要求待查找的序列有序。每次取中间位置的值与待查关键字比较,如果中间位置的值比待查关键字大,则在前半部分循环这个查找的过程,如果中间位置的值比待查关键字小,则在后半部分循环这个查找的过程。直到查找到了为止,否则序列中没有待查的关键字。 public static int biSearch(int []array,int a){ int lo=0; int hi=array.length-1; int mid; while(lo int i, j; for(i=0; i for(int i =1; i int start = low; int end = high; int key = a[low]; while(end>start){ //从后往前比较 while(end>start&&a[end]>=key) //如果没有比关键值小的,比较下一个,直到有比关键值小的交换位置,然后又从前往后比较 end--; if(a[end]start&&a[start]=key){ int temp = a[start]; a[start] = a[end]; a[end] = temp; }//此时第一次循环比较结束,关键值的位置已经确定了。左边的值都比关键值小,右边的值都比关键值大,但是两边的顺序还有可能是不一样的,进行下面的递归调用 }//递归 if(start>low) sort(a,low,start-1);//左边序列。第一个索引位置到关键值索引-1 if(endtj, tk=1; 2. 按增量序列个数k,对序列进行k趟排序;每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m的子序列,分别对各子表进行直接插入排序。仅增量因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度。 |
 删除操作
删除操作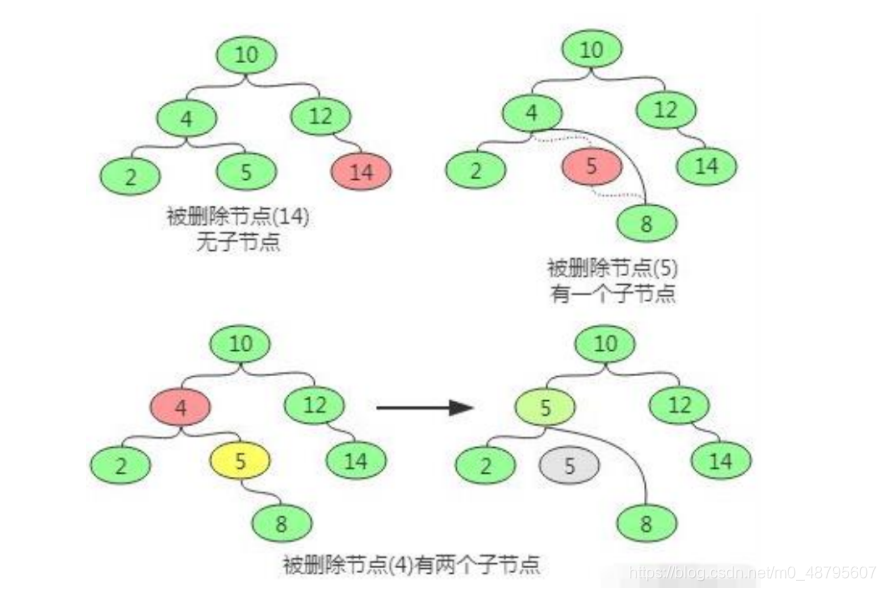 查询操作
查询操作

 右旋 对 x 进行右旋,意味着,将“x 的左孩子”设为“x 的父亲节点”;即,将 x 变成了一个右节点(x成了为 y 的右孩子)! 因此,右旋中的“右”,意味着“被旋转的节点将变成一个右节点”。
右旋 对 x 进行右旋,意味着,将“x 的左孩子”设为“x 的父亲节点”;即,将 x 变成了一个右节点(x成了为 y 的右孩子)! 因此,右旋中的“右”,意味着“被旋转的节点将变成一个右节点”。 
 添加
添加 第三步: 通过一系列的旋转或着色等操作,使之重新成为一颗红黑树。
第三步: 通过一系列的旋转或着色等操作,使之重新成为一颗红黑树。 参考: https://www.jianshu.com/p/038585421b73
参考: https://www.jianshu.com/p/038585421b73
【本文地址】