| 1 | 您所在的位置:网站首页 › 笔趣阁VIP版网址 › 1 |
1
|
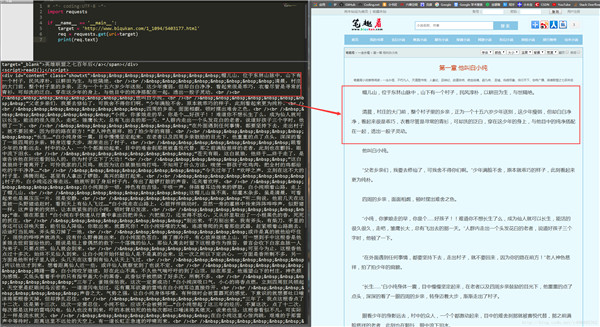
笔趣看是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。所以可以通过python爬取文本信息保存,从而达到下载的目的 以首页的《一念永恒》作为测试: 1、先查看第一章地址中的html文本:https://www.biqukan.com/1_1094/5403177.html 通过requests库获取: # -*- coding:UTF-8 -*- import requests if __name__ == '__main__': target = 'http://www.biqukan.com/1_1094/5403177.html' req = requests.get(url=target) print(req.text)运行代码,可以看到如下结果:(获取到他的html文本,你可以通过chrome审查元素来对照)
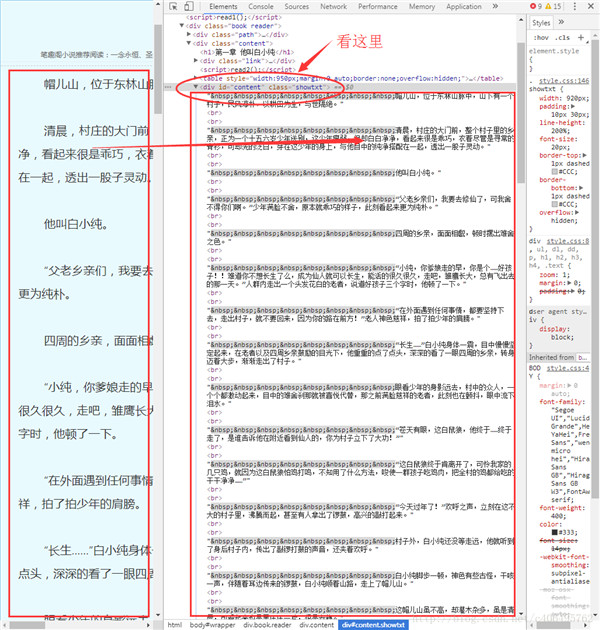
可以看到,我们很轻松地获取了HTML信息。但是,很显然,很多信息是我们不想看到的,我们只想获得如右侧所示的正文内容,我们不关心div、br这些html标签。如何把正文内容从这些众多的html标签中提取出来呢?这就是本次实战的主要内容。 Beautiful Soup 爬虫的第一步,获取整个网页的HTML信息,我们已经完成。接下来就是爬虫的第二步,解析HTML信息,提取我们感兴趣的内容。对于本小节的实战,我们感兴趣的内容就是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup等。对于初学者而言,最容易理解,并且使用简单的方法就是使用Beautiful Soup提取感兴趣内容。 Beautiful Soup的安装方法和requests一样(我安装的是3.7版本): pip3 install beautifulsoup4Beautiful Soup中文的官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/ 通过google chrome中审查元素方法,查看一下我们的目标页面,你会看到如下内容:
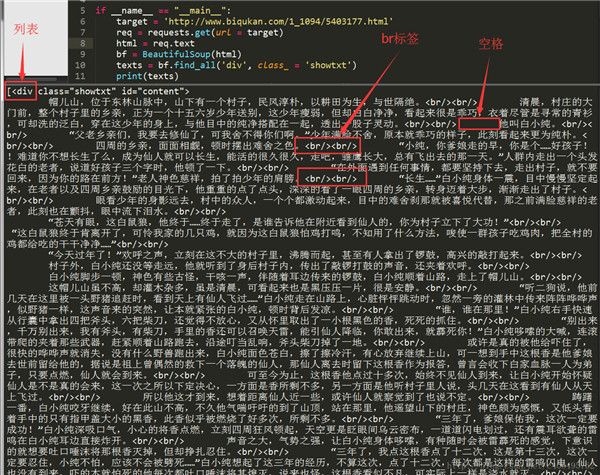
可以看到文本内容都放置在这个标签中 ,这样就可以开始通过库来获取这个标签中的内容: # -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests if __name__ == "__main__": target = 'http://www.biqukan.com/1_1094/5403177.html' req = requests.get(url = target) bf = BeautifulSoup(req.text) #查询所有div标签,并且class为'showtxt' texts = bf.find_all('div', class_ = 'showtxt') print(texts)获取到如下内容:
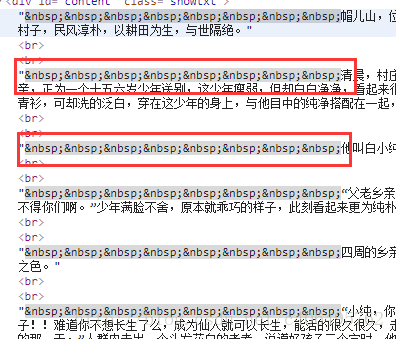
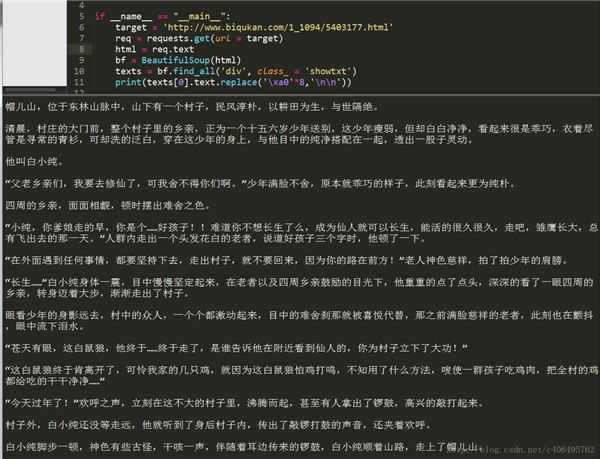
我们可以看到,我们已经顺利匹配到我们关心的正文内容,但是还有一些我们不想要的东西。比如div标签名,br标签,以及各种空格。怎么去除这些东西呢?我们继续编写代码: # -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests if __name__ == "__main__": target = 'http://www.biqukan.com/1_1094/5403177.html' req = requests.get(url = target) html = req.text bf = BeautifulSoup(html) texts = bf.find_all('div', class_ = 'showtxt') #replace(‘\xa0’*8,’\n\n’)就是去掉八个空格符号,并用回车代替 print(texts[0].text.replace('\xa0'*8,'\n\n'))find_all匹配的返回的结果是一个列表。提取匹配结果后,使用text属性,提取文本内容,滤除br标签。随后使用replace方法,剔除空格,替换为回车进行分段。 在html中是用来表示空格的。replace(‘\xa0’*8,’\n\n’)就是去掉下图的八个空格符号,并用回车代替:
程序运行结果如下:
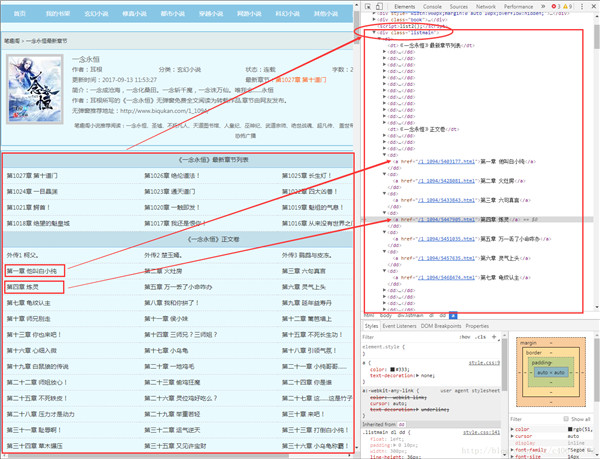
我们已经顺利获得了一个章节的内容,要想下载正本小说,我们就要获取每个章节的链接。我们先分析下小说目录:
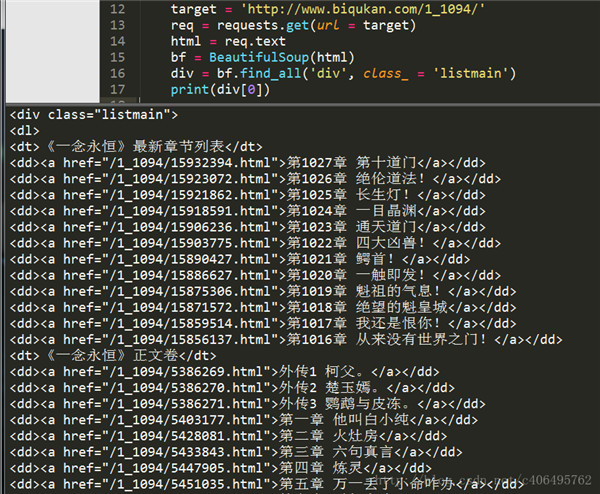
通过审查元素,我们发现可以发现,这些章节都存放在了class属性为listmain的div标签下,选取部分html代码如下: 《一念永恒》最新章节列表 第1027章 第十道门 第1026章 绝伦道法! 第1025章 长生灯! 第1024章 一目晶渊 第1023章 通天道门 第1022章 四大凶兽! 第1021章 鳄首! 第1020章 一触即发! 第1019章 魁祖的气息! 第1018章 绝望的魁皇城 第1017章 我还是恨你! 第1016章 从来没有世界之门! 《一念永恒》正文卷 外传1 柯父。 外传2 楚玉嫣。 外传3 鹦鹉与皮冻。 第一章 他叫白小纯 第二章 火灶房 第三章 六句真言 第四章 炼灵 根据第一章的内容和获取到的列表中a标签 href后面的内容可以知道,每个章节的内容就是http://www.biqukan.com+a标签href后的内容: http://www.biqukan.com/1_1094/5403177.html 第一章 他叫白小纯我们先获取listmain中的内容: 目录链接地址为:https://www.biqukan.com/1_1094/ # -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests if __name__ == "__main__": target = 'http://www.biqukan.com/1_1094/' req = requests.get(url = target) html = req.text div_bf = BeautifulSoup(html) div = div_bf.find_all('div', class_ = 'listmain') print(div[0])还是使用find_all方法,运行结果如下:
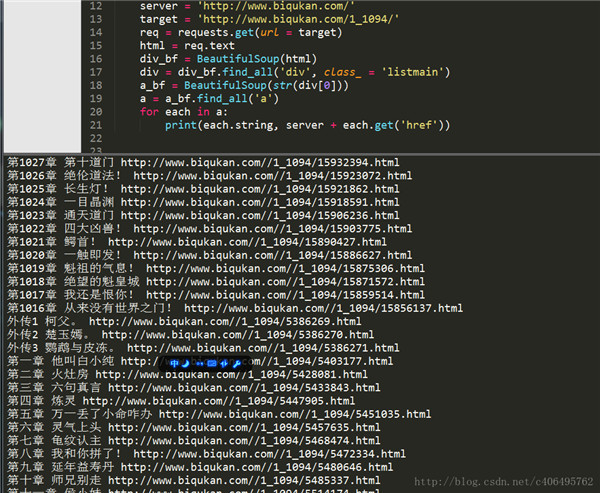
很顺利,接下来再匹配每一个标签,并提取章节名和章节文章。如果我们使用Beautiful Soup匹配到了下面这个标签,如何提取它的href属性和标签里存放的章节名呢? 第一章 他叫白小纯方法很简单,对Beautiful Soup返回的匹配结果a,使用a.get(‘href’)方法就能获取href的属性值,使用a.string就能获取章节名,编写代码如下: # -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests if __name__ == "__main__": server = 'http://www.biqukan.com/' target = 'http://www.biqukan.com/1_1094/' req = requests.get(url = target) html = req.text div_bf = BeautifulSoup(html) div = div_bf.find_all('div', class_ = 'listmain') a_bf = BeautifulSoup(str(div[0])) a = a_bf.find_all('a') for each in a: print(each.string, server + each.get('href'))因为find_all返回的是一个列表,里边存放了很多的标签,所以使用for循环遍历每个标签并打印出来,运行结果如下。
最上面匹配的一千多章的内容是最新更新的12章节的链接。这12章内容会和下面的重复,所以我们要滤除,除此之外,还有那3个外传,我们也不想要。这些都简单地剔除就好。 3)整合代码每个章节的链接、章节名、章节内容都有了。接下来就是整合代码,将获得内容写入文本文件存储就好了。编写代码如下: # -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests, sys, threading , os , shutil """ 类说明:下载《笔趣看》网小说《一念永恒》 Parameters: 无 Returns: 无 Modify: 2017-09-13 """ class downloader(object): def __init__(self): self.server = 'http://www.biqukan.com/' self.target = 'http://www.biqukan.com/1_1094/' self.names = [] #存放章节名 self.urls = [] #存放章节链接 self.nums = 0 #章节数 """ 函数说明:获取章节列表以及对应的下载链接列表 Parameters: 无 Returns: 无 Modify: 2017-09-13 """ def get_download_url(self): req = requests.get(url = self.target) html = req.text div_bf = BeautifulSoup(html) div = div_bf.find_all('div', class_ = 'listmain') a_bf = BeautifulSoup(str(div[0])) a = a_bf.find_all('a') self.nums = len(a[15:]) #剔除不必要的章节,并统计章节数 for each in a[15:]: self.names.append(each.string) self.urls.append(self.server + each.get('href')) """ 函数说明:获取对应章节的内容 Parameters: target - 下载连接(string) Returns: texts - 章节内容(string) Modify: 2017-09-13 """ def get_contents(self, target): req = requests.get(url = target) html = req.text bf = BeautifulSoup(html) texts = bf.find_all('div', class_ = 'showtxt') texts = texts[0].text.replace('\xa0'*8,'\n\n') return texts """ 函数说明:将爬取的文章内容写入文件 Parameters: name - 章节名称(string) path - 当前路径下,小说保存名称(string) text - 章节内容(string) Returns: 无 Modify: 2017-09-13 """ def writer(self, name, path, text): write_flag = True with open(path, 'a', encoding='utf-8') as f: f.write(name + '\n') f.writelines(text) f.write('\n\n') class myThread (threading.Thread): #继承父类threading.Thread def __init__(self, name,temdl,startNum,endNum): threading.Thread.__init__(self) self.runlist = list() self.name = name self.temdl = temdl self.startNum = startNum self.endNum = endNum def run(self): #把要执行的代码写到run函数里面 线程在创建后会直接运行run函数 print ("Starting " + self.name) startDownloadTxt(self.temdl,self.startNum,self.endNum) print ("Exiting " + self.name) def mkdir(path): ''' 判断路径是否存在 存在 True 不存在 False ''' isExists=os.path.exists(path) if not isExists: os.makedirs(path) return True else: return False def subFile(path): #特定目录下的文件列表 docList = os.listdir(path) # 显示当前文件夹下所有文件并进行排序 ''' key = lambda x:int(x[:-4]) 忽略文件名开始到倒数第四个字符为止 docList.remove(i) 删除数组中点开头的系统隐藏文件,因为会影响排序 ''' for i in docList: if(i[0]=='.'): docList.remove(i) break docList.sort(key = lambda x: int(x[:-4])) #创建一个以书籍名字命名的文件 fnamepath = path+'/一念永恒.txt' fname = open(fnamepath, "w") #打开你之前命名的下载文件 for i in docList: tempath = path+'/'+i x = open (tempath, "r") #打开列表中的文件,读取文件内容 fname.write(x.read()) #写入新建的文件中 x.close() #关闭列表文件 fname.close() #移动最后的完成文件到桌面,在删除download文件夹(windows环境下根据情况自己修改路径) shutil.move(fnamepath, '/Users/chen/Desktop') shutil.rmtree(path) ''' temdl:downloader类 startNum,endNum开始和结束的rang ''' def startDownloadTxt(temdl,startNum,endNum): mkdir('download') for i in range(startNum,endNum): temPath = './download/'+str(i)+'.txt' temdl.writer(temdl.names[i], temPath, temdl.get_contents(temdl.urls[i])) print(temdl.names[i]+'done') if __name__ == "__main__": dl = downloader() #获取章节列表以及对应的下载链接列表 dl.get_download_url() print('《一年永恒》开始下载:') # 创建二十个线程(太多的话,会卡) threads = [] threadNum = 20 for p in range(threadNum): threadname = '"Thread'+str(p) stepNum = dl.nums//threadNum if(p==threadNum-1): thread = myThread(threadname,dl,p*stepNum,dl.nums) else: thread = myThread(threadname,dl,p*stepNum,(p+1)*stepNum) threads.append(thread) try: # 开启线程 for t in threads: t.start() for t in threads: t.join() except: print ("Error: unable to start thread") subFile('./download') print('一念永恒下载完成')我开了20个线程同时去下载这个小说,大概花费2分钟的时间,如果你觉得慢,可以调成40下载大概只需要1分钟左右 一个11m的小说就能下载好了! 代码内容涉及多线程、文件操作、请求、解析(是一个很不错的例子 大家可以互相学习一下)
|
【本文地址】