| python 网页爬虫实践(附完整代码) | 您所在的位置:网站首页 › 空白id代码知乎 › python 网页爬虫实践(附完整代码) |
python 网页爬虫实践(附完整代码)
|
PS: 封面照片由大师姐拍摄,版权归大师姐所有。 本文将介绍如何从简书页面抓取全部超链接,以及如何从简书抓取页面文章标题和正文内容,并且将抓取到这些信息存入txt文档中。 本文仅作为python爬虫技术学习交流,尊重作者著作权,不对抓取到的文章做其他用途。 目录0. 要抓取的页面介绍 1.抓取简书页面所有的超链接 2.保存所有的超链接 3.抓取1中超链接对应页面的文章标题和正文内容 4.保存抓取的文章标题和正文内容 文章最后附完整代码 0. 要抓取的页面介绍本文将以抓取如下页面为例进行展开: 这是一个包含英语流利说付费课程,懂你英语level1-level8全部笔记链接的汇总页面。我们将在1、2中抓取出这些有用的笔记链接。  在3、4部分将循环进入所有的笔记页面,并抓取所有的标题、正文,并保存。下图是其中一个详情页面的例子。 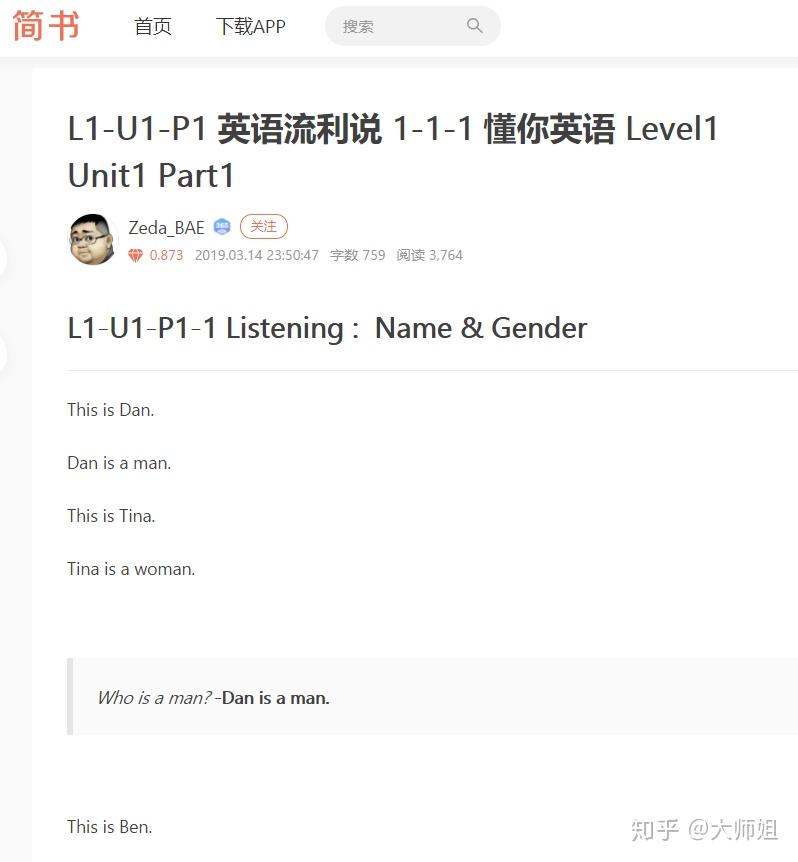 1.抓取简书页面所有的超链接from bs4 import BeautifulSoup
import urllib.request
url = "https://www.jianshu.com/p/deb8002bbba6"
# define a header to address the error: 'HTTP Error 403: Forbidden'
user_agent = 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.7) Gecko/2009021910 Firefox/3.0.7'
headers={'User-Agent':user_agent,}
request=urllib.request.Request(url,None,headers) #The assembled request
response = urllib.request.urlopen(request)
html =response.read()
# 解析网页内容
soup = BeautifulSoup(html, 'html.parser')
usefulurls=[]
pageurls = soup.find_all('a')
for link in pageurls:
url = link.get('href')
if url[0:5]!='https':
pass # 排除不符合要求的网址
elif len(url) 1.抓取简书页面所有的超链接from bs4 import BeautifulSoup
import urllib.request
url = "https://www.jianshu.com/p/deb8002bbba6"
# define a header to address the error: 'HTTP Error 403: Forbidden'
user_agent = 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.7) Gecko/2009021910 Firefox/3.0.7'
headers={'User-Agent':user_agent,}
request=urllib.request.Request(url,None,headers) #The assembled request
response = urllib.request.urlopen(request)
html =response.read()
# 解析网页内容
soup = BeautifulSoup(html, 'html.parser')
usefulurls=[]
pageurls = soup.find_all('a')
for link in pageurls:
url = link.get('href')
if url[0:5]!='https':
pass # 排除不符合要求的网址
elif len(url) |
【本文地址】
公司简介
联系我们
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |