| 多层感知机(MLP)简介 | 您所在的位置:网站首页 › 神经网络预测优缺点是什么 › 多层感知机(MLP)简介 |
多层感知机(MLP)简介
|
一、多层感知机(MLP)原理简介 多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:
从上图可以看到,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。 隐藏层的神经元怎么得来?首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是 f (W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数: 注:神经网络中的Sigmoid型激活函数: 1. 为嘛使用激活函数? a. 不使用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。 b. 使用激活函数,能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以利用到更多的非线性模型中。 激活函数需要具备以下几点性质: 1. 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参 数。 2. 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。 3. 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。 2. sigmod 函数 导数为: 3 . Tanh 函数
取值范围为[-1,1] tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。 与sigmod的区别是 tanh 是0 的均值,因此在实际应用中tanh会比sigmod更好。 在具体应用中,tanh函数相比于Sigmoid函数往往更具有优越性,这主要是因为Sigmoid函数在输入处于[-1,1]之间时,函数值变 化敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态。
最后就是输出层,输出层与隐藏层是什么关系? 其实隐藏层到输出层可以看成是一个多类别的逻辑回归,也即softmax回归,所以输出层的输出就是softmax(W2X1+b2),X1表示隐藏层的输出f(W1X+b1)。 MLP整个模型就是这样子的,上面说的这个三层的MLP用公式总结起来就是,函数G是softmax。 因此,MLP所有的参数就是各个层之间的连接权重以及偏置,包括W1、b1、W2、b2。对于一个具体的问题,怎么确定这些参数?求解最佳的参数是一个最优化问题,解决最优化问题,最简单的就是梯度下降法了(SGD):首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止(比如误差足够小、迭代次数足够多时)。这个过程涉及到代价函数、规则化(Regularization)、学习速率(learning rate)、梯度计算等,本文不详细讨论,读者可以参考本文底部给出的两个链接。 了解了MLP的基本模型,下面进入代码实现部分。 二、多层感知机(MLP)代码详细解读(基于python+theano)代码来自:Multilayer Perceptron,本文只是做一个详细解读,如有错误,请不吝指出。 这个代码实现的是一个三层的感知机,但是理解了代码之后,实现n层感知机都不是问题,所以只需理解好这个三层的MLP模型即可。概括地说,MLP的输入层X其实就是我们的训练数据,所以输入层不用实现,剩下的就是“输入层到隐含层”,“隐含层到输出层”这两部分。上面介绍原理时已经说到了,“输入层到隐含层”就是一个全连接的层,在下面的代码中我们把这一部分定义为HiddenLayer。“隐含层到输出层”就是一个分类器softmax回归,在下面的代码中我们把这一部分定义为logisticRegression。 代码详解开始: (1)导入必要的python模块 主要是numpy、theano,以及python自带的os、sys、time模块,这些模块的使用在下面的程序中会看到。 import os import sysimport time import numpy import theano import theano.tensor as T(2)定义MLP模型(HiddenLayer+LogisticRegression) 这一部分定义MLP的基本“构件”,即上文一直在提的HiddenLayer和LogisticRegression HiddenLayer 隐含层我们需要定义连接系数W、偏置b,输入、输出,具体的代码以及解读如下: class HiddenLayer(object): def __init__(self, rng, input, n_in, n_out, W=None, b=None, activation=T.tanh): """ 注释: 这是定义隐藏层的类,首先明确:隐藏层的输入即input,输出即隐藏层的神经元个数。输入层与隐藏层是全连接的。 假设输入是n_in维的向量(也可以说时n_in个神经元),隐藏层有n_out个神经元,则因为是全连接, 一共有n_in*n_out个权重,故W大小时(n_in,n_out),n_in行n_out列,每一列对应隐藏层的每一个神经元的连接权重。 b是偏置,隐藏层有n_out个神经元,故b时n_out维向量。 rng即随机数生成器,numpy.random.RandomState,用于初始化W。 input训练模型所用到的所有输入,并不是MLP的输入层,MLP的输入层的神经元个数时n_in,而这里的参数input大小是(n_example,n_in),每一行一个样本,即每一行作为MLP的输入层。 activation:激活函数,这里定义为函数tanh """ self.input = input #类HiddenLayer的input即所传递进来的input """ 注释: 代码要兼容GPU,则W、b必须使用 dtype=theano.config.floatX,并且定义为theano.shared 另外,W的初始化有个规则:如果使用tanh函数,则在-sqrt(6./(n_in+n_hidden))到sqrt(6./(n_in+n_hidden))之间均匀 抽取数值来初始化W,若时sigmoid函数,则以上再乘4倍。 """ #如果W未初始化,则根据上述方法初始化。 #加入这个判断的原因是:有时候我们可以用训练好的参数来初始化W if W is None: W_values = numpy.asarray( rng.uniform( low=-numpy.sqrt(6. / (n_in + n_out)), high=numpy.sqrt(6. / (n_in + n_out)), size=(n_in, n_out) ), dtype=theano.config.floatX ) if activation == theano.tensor.nnet.sigmoid: W_values *= 4 W = theano.shared(value=W_values, name='W', borrow=True) if b is None: b_values = numpy.zeros((n_out,), dtype=theano.config.floatX) b = theano.shared(value=b_values, name='b', borrow=True) #用上面定义的W、b来初始化类HiddenLayer的W、b self.W = W self.b = b #隐含层的输出 lin_output = T.dot(input, self.W) + self.b self.output = ( lin_output if activation is None else activation(lin_output) ) #隐含层的参数 self.params = [self.W, self.b]LogisticRegression 逻辑回归(softmax回归),代码详解如下。 """ 定义分类层,Softmax回归 在deeplearning tutorial中,直接将LogisticRegression视为Softmax, 而我们所认识的二类别的逻辑回归就是当n_out=2时的LogisticRegression """ #参数说明: #input,大小就是(n_example,n_in),其中n_example是一个batch的大小, #因为我们训练时用的是Minibatch SGD,因此input这样定义 #n_in,即上一层(隐含层)的输出 #n_out,输出的类别数 class LogisticRegression(object): def __init__(self, input, n_in, n_out): #W大小是n_in行n_out列,b为n_out维向量。即:每个输出对应W的一列以及b的一个元素。 self.W = theano.shared( value=numpy.zeros( (n_in, n_out), dtype=theano.config.floatX ), name='W', borrow=True ) self.b = theano.shared( value=numpy.zeros( (n_out,), dtype=theano.config.floatX ), name='b', borrow=True ) #input是(n_example,n_in),W是(n_in,n_out),点乘得到(n_example,n_out),加上偏置b, #再作为T.nnet.softmax的输入,得到p_y_given_x #故p_y_given_x每一行代表每一个样本被估计为各类别的概率 #PS:b是n_out维向量,与(n_example,n_out)矩阵相加,内部其实是先复制n_example个b, #然后(n_example,n_out)矩阵的每一行都加b self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b) #argmax返回最大值下标,因为本例数据集是MNIST,下标刚好就是类别。axis=1表示按行操作。 self.y_pred = T.argmax(self.p_y_given_x, axis=1) #params,LogisticRegression的参数 self.params = [self.W, self.b]
ok!这两个基本“构件”做好了,现在我们可以将它们“组装”在一起。 我们要三层的MLP,则只需要HiddenLayer+LogisticRegression, 如果要四层的MLP,则为HiddenLayer+HiddenLayer+LogisticRegression........以此类推。 下面是三层的MLP: #3层的MLP class MLP(object): def __init__(self, rng, input, n_in, n_hidden, n_out): self.hiddenLayer = HiddenLayer( rng=rng, input=input, n_in=n_in, n_out=n_hidden, activation=T.tanh ) #将隐含层hiddenLayer的输出作为分类层logRegressionLayer的输入,这样就把它们连接了 self.logRegressionLayer = LogisticRegression( input=self.hiddenLayer.output, n_in=n_hidden, n_out=n_out ) #以上已经定义好MLP的基本结构,下面是MLP模型的其他参数或者函数 #规则化项:常见的L1、L2_sqr self.L1 = ( abs(self.hiddenLayer.W).sum() + abs(self.logRegressionLayer.W).sum() ) self.L2_sqr = ( (self.hiddenLayer.W ** 2).sum() + (self.logRegressionLayer.W ** 2).sum() ) #损失函数Nll(也叫代价函数) self.negative_log_likelihood = ( self.logRegressionLayer.negative_log_likelihood ) #误差 self.errors = self.logRegressionLayer.errors #MLP的参数 self.params = self.hiddenLayer.params + self.logRegressionLayer.params # end-snippet-3MLP类里面除了隐含层和分类层,还定义了损失函数、规则化项,这是在求解优化算法时用到的。 Ref: 1. https://blog.csdn.net/m0_38045485/article/details/81749385 2. https://blog.csdn.net/u012162613/article/details/43221829 经详细注释的代码:放在github地址上https://github.com/wepe/MachineLearning/tree/master/DeepLearning Tutorials/mlp |




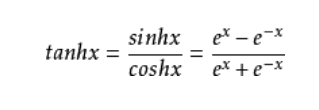

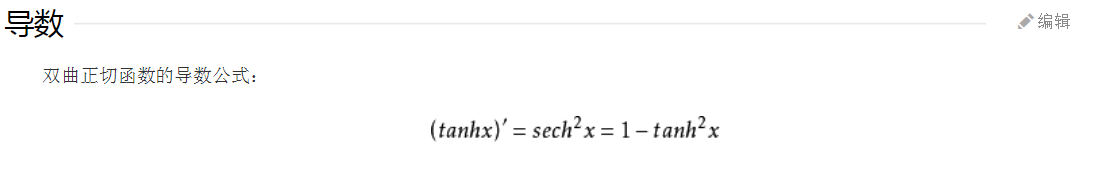
【本文地址】