| 一文看懂BP神经网络的基础数学知识 | 您所在的位置:网站首页 › 神经网络需要什么数学知识 › 一文看懂BP神经网络的基础数学知识 |
一文看懂BP神经网络的基础数学知识
|
看懂本文需要的基础知识有:
能够理解最基本的最优化问题(例如最小二乘法优化)学习过高数和线性代数,对数学符号有概念一定的编程基础最好明白感知器的概念神经网络的基本知识
1.0 历史与发展
线性神经网络只能解决线性可分的问题,这与其单层网络的结构有关。 BP 神经网络是包含多个隐含层的网络, 具备处理线性不可分问题的能力。 在历史上, 由于一直没有找到合适的多层神经网络的学习算法, 导致神经网络的研究一度陷入低迷。 M.Minsky 等仔细分析了以感知器为代表的神经网络系统的功能及局限后, 于 1969 年出版了 “ Perceptron ”一书, 指出感知器不能解决高阶谓词问题, 他们的观点加深了人们对神经网络的悲观情绪。 20世纪80年代中期, Rumelhart,MicClelland 等成立了 Parallel Distributed Procession(PDP) 小组, 提出了著名的误差反向传播算法( Error Back Propagtion,BP),解决了多层神经网络的学习问题,极大促进了神经网络的发展, 这种神经网络就被称为BP神经网络。感知器、线性神经网络、BP网络与径向基神经网络都属于前向网络,其中BP网络和径向基网络属于多层前向神经网络。 BP网络是前向神经网络的核心部分,也是整个人工神经网络体系中的精华,广泛应用于分类识别、 逼近、回归、压缩等领域。在实际应用中,大约80%的神经网络模型采取了 BP网络或BP网络的变化形式。
划重点:
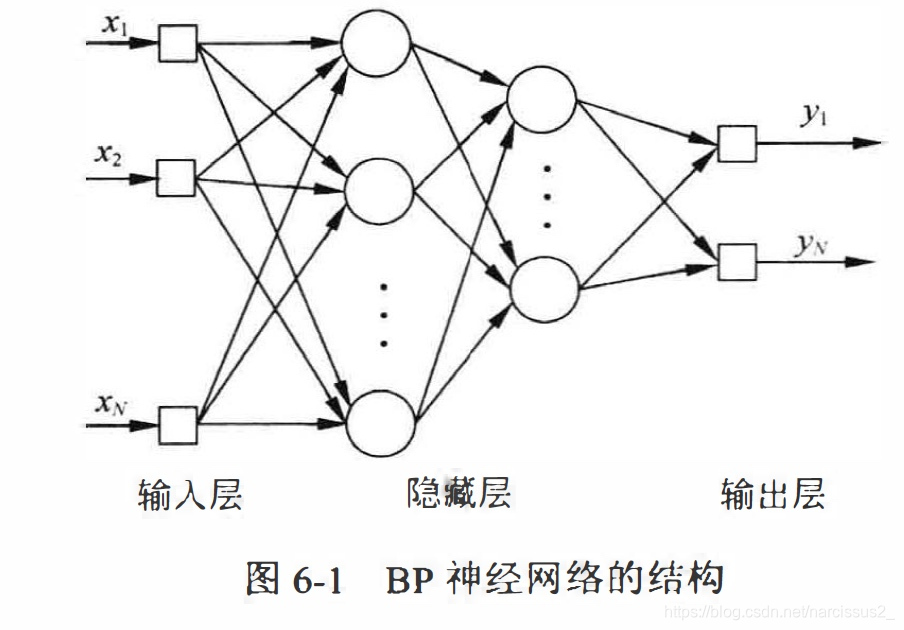
BP神经网络有/是 多个隐藏层线性不可分误差反向传播算法前向网络 1.1 BP神经网络的结构 BP神经网络一般是多层的,与之相关的另一个概念是多层感知器(Multi-Layer perceptron,MLP)。多层感知器除了输入层和输出层意外,还具有若干个隐含层。多层感知器强调神经网络在结构上由多层组成,**BP神经网络也是一种多层感知器,它强调网络采用误差反向传播的学习算法。**大部分情况下多层感知器采用误差反向传播的算法进行权值调整,因此两者一般指的是同一种网络,在本书中两个概念同时使用。BP神经网络的隐含层可以为一层或多层,一个包含2层隐含层的BP神经网络的拓扑结构如图6-1
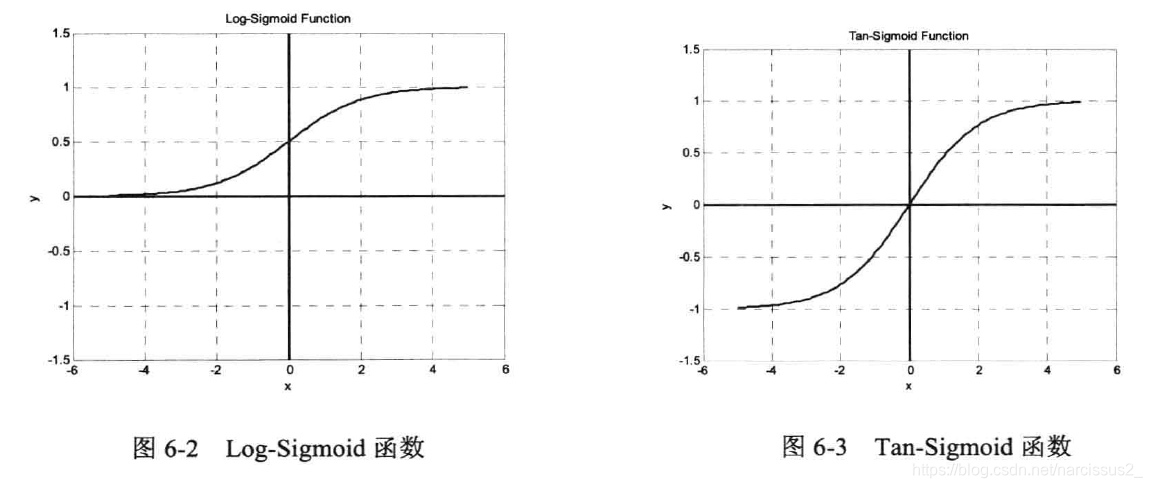 从图中可以看出**,Sigmoid函数是光滑、可微的函数,在分类时它比线性函数更精确,容错性较好。** **它将输入从负无穷到正无穷的范围映射到(一1,1)或(0,1)区间内,具有非线性的放大功能。**以正半轴为例,在靠近原点处,输入信号较小,此时曲线上凸,输出值大于输入值:随着信号增大,非线性放大的系数逐渐减小。Sigmoid函数可微的特性使它可以利用梯度下降法。在输出层,如果采用Sigmoid函数,将会把输出值限制在一个较小的范围,因此,BP神经网络的典型设计是隐含层采用Sigmoid函数作为传递函数,而输出层则采用线性函数作为传递函数。(3) 采用误差反向传播算法(Back-Propagation Algorithm)进行学习。在BP网络中,数据从输入层经隐含层逐层向后传播1,训练网络权值时,则沿着减少误差的方向2,从输出层经过中间各层逐层向前修正网络的连接权值。注意:切记要区分”误差反向传播“与”反馈神经网络“。在BP网络中,”反向传播“指的是误差信号反向传播,修正权值时,网络根据误差从后向前边层进行修正。BP神经网络属于多层前向网络,工作信号始终正向流动,没有反馈结构。在本书第9章中会专门介绍反馈神经网络,包括Hopfield网络、Elman网络等。在反馈神经网络中,输出层的输出值又连接到输入神经元,作为下一次计算的输入,如此循环迭代,直到网络的输出值进入稳定状态为止。
划重点:
sigmoid函数层和层全连接函数可微分误差反向传播权值从后向前修正信号正向流动两张图
1.2 BP网络的学习算法
1.2.1 BP网络学习算法的大体感知
确定BP网络的层数和每层的神经元个数确定各层之间的权值系数。
训练时先使用随机权值。输入学习样本后得到输出。然后反复修改使误差不再下降,训练完成修改权值有不同的规则。标准的BP网络沿着误差性能函数梯度的反方向。原理与LMS算法比较类似,属于最速下降法。此外,还有一些改进算法,动量最速下降法,拟牛顿法。
1.2.1 最速下降法
最速下降法即LMS概念:
梯度下降法又称为梯度下降法,是一种可微函数最优化算法。LMS算法即最小均方误差算法(Least Mean Square Algorithm)。LMS就是目标函数为均方误差的最速下降法。
最速下降法原理 从图中可以看出**,Sigmoid函数是光滑、可微的函数,在分类时它比线性函数更精确,容错性较好。** **它将输入从负无穷到正无穷的范围映射到(一1,1)或(0,1)区间内,具有非线性的放大功能。**以正半轴为例,在靠近原点处,输入信号较小,此时曲线上凸,输出值大于输入值:随着信号增大,非线性放大的系数逐渐减小。Sigmoid函数可微的特性使它可以利用梯度下降法。在输出层,如果采用Sigmoid函数,将会把输出值限制在一个较小的范围,因此,BP神经网络的典型设计是隐含层采用Sigmoid函数作为传递函数,而输出层则采用线性函数作为传递函数。(3) 采用误差反向传播算法(Back-Propagation Algorithm)进行学习。在BP网络中,数据从输入层经隐含层逐层向后传播1,训练网络权值时,则沿着减少误差的方向2,从输出层经过中间各层逐层向前修正网络的连接权值。注意:切记要区分”误差反向传播“与”反馈神经网络“。在BP网络中,”反向传播“指的是误差信号反向传播,修正权值时,网络根据误差从后向前边层进行修正。BP神经网络属于多层前向网络,工作信号始终正向流动,没有反馈结构。在本书第9章中会专门介绍反馈神经网络,包括Hopfield网络、Elman网络等。在反馈神经网络中,输出层的输出值又连接到输入神经元,作为下一次计算的输入,如此循环迭代,直到网络的输出值进入稳定状态为止。
划重点:
sigmoid函数层和层全连接函数可微分误差反向传播权值从后向前修正信号正向流动两张图
1.2 BP网络的学习算法
1.2.1 BP网络学习算法的大体感知
确定BP网络的层数和每层的神经元个数确定各层之间的权值系数。
训练时先使用随机权值。输入学习样本后得到输出。然后反复修改使误差不再下降,训练完成修改权值有不同的规则。标准的BP网络沿着误差性能函数梯度的反方向。原理与LMS算法比较类似,属于最速下降法。此外,还有一些改进算法,动量最速下降法,拟牛顿法。
1.2.1 最速下降法
最速下降法即LMS概念:
梯度下降法又称为梯度下降法,是一种可微函数最优化算法。LMS算法即最小均方误差算法(Least Mean Square Algorithm)。LMS就是目标函数为均方误差的最速下降法。
最速下降法原理
最速下降法基于这样的原理:对于实值函数F(x),如果F(x)在某点X0处有定义且可微,则函数在该点处沿着梯度相反的方向 − ∇ F ( x 0 ) -\nabla F(x_0) −∇F(x0)下降最快。因此,使用梯度下降法时, 应首先计算函数在某点处的梯度,再沿着梯度的反方向以一定的步长调整自变量的值。 假设 x 1 = x 0 − η ∇ F ( x 0 ) x_1=x_0-\eta \nabla F(x_0) x1=x0−η∇F(x0),当步长 η \eta η足够小时,必有以下公式 F ( x 1 ) ; F ( x 0 ) F(x_1);F(x_0) F(x1) |
【本文地址】
公司简介
联系我们