| 利用BP神经网络进行函数拟合 | 您所在的位置:网站首页 › 神经网络训练结果分析 › 利用BP神经网络进行函数拟合 |
利用BP神经网络进行函数拟合
|
利用BP神经网络进行函数拟合
摘要关键词问题描述算法设计结果分析与讨论结论Python源代码
摘要
数据拟合是在假设模型结构已知的条件下最优确定模型中未知参数使预测值与数据吻合度最高,本文选取线性项加激活函数组成一个非线性模型,利用神经网络算法最优确定模型中的未知参数,利用随机搜索的方式确定函数模型,从而达到很好的拟合效果 关键词BP神经网络 随机搜索 随机重启 参数优化 数据拟合 RELU 问题描述数据拟合问题普遍存在,拟合问题本质上是在假设模型结构已知的条件下最优确定模型中未知参数以使得模型预测与数据的吻合度最高,即数据拟合问题往往描述为一个参数优化问题。 复杂工业过程对于模型精度的要求,线性模型往往不能满足。因此模型结构假设为非线性更为合理。此处我们假设模型结构为: BP神经网络是一种按照误差逆向传播训练的多层前馈神经网络。神经网络理论上可以拟合任意曲线,这一点已经得到了严格的数学证明。 三层神经网络模型 通常一个多层神经网络由L层构成,其中有1层输出层,1层输入层,L-2层隐藏层。输入层是神经网络的第一层,表示一列矩阵或多列矩阵的输入。输出层是神经网络的最后一层,表示网络的输出结果,通常是一列矩阵。隐藏层有L-2层,表示每一层神经元通过前向传播算法计算的结果矩阵。 在本程序中,采用3层神经网络。输入矩阵X=[X1,X2],题目中给出的模型需要对输入矩阵X进行增广,然后乘以参数 通常一个多层神经网络由L层构成,其中有1层输出层,1层输入层,L-2层隐藏层。输入层是神经网络的第一层,表示一列矩阵或多列矩阵的输入。输出层是神经网络的最后一层,表示网络的输出结果,通常是一列矩阵。隐藏层有L-2层,表示每一层神经元通过前向传播算法计算的结果矩阵。 在本程序中,采用3层神经网络。输入矩阵X=[X1,X2],题目中给出的模型需要对输入矩阵X进行增广,然后乘以参数 ,其实相当于神经网络中的偏置项bi,i=1,2。因此在本程序中无需对输入矩阵进行增广。wi,wi, i=1,2;bi,i=1,2分别是输入层与隐藏层之间,隐藏层与输出层之间的连接权重和偏置项。设 ,其实相当于神经网络中的偏置项bi,i=1,2。因此在本程序中无需对输入矩阵进行增广。wi,wi, i=1,2;bi,i=1,2分别是输入层与隐藏层之间,隐藏层与输出层之间的连接权重和偏置项。设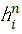 ,n=1,i=1,2,3,…,M,表示隐藏层的第i个神经元的输出。激活函数 本程序中采用的激活函数为RELU函数,即函数模型中的,目的是去除整个神经网络输出的线性化,使得整个神经网络模型呈非线性化。损失函数 本程序中采用的损失函数为MSE(均方误差),利用均方误差和激活函数的导数来更新权重和偏置。 ,n=1,i=1,2,3,…,M,表示隐藏层的第i个神经元的输出。激活函数 本程序中采用的激活函数为RELU函数,即函数模型中的,目的是去除整个神经网络输出的线性化,使得整个神经网络模型呈非线性化。损失函数 本程序中采用的损失函数为MSE(均方误差),利用均方误差和激活函数的导数来更新权重和偏置。 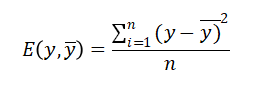 前向传播算法是指依次向前计算相邻隐藏层之间的连接输出,直到模型的最终输出值。其特点作用于相邻层的两个神经元之间的计算,且前一层神经元的输出是后一层的神经元的输入。 设对于第n层的第i个神经元,有n-1层的M(M为超参数)个神经元与该神经元有突触相连,则第n层第i个神经元的输入为: 前向传播算法是指依次向前计算相邻隐藏层之间的连接输出,直到模型的最终输出值。其特点作用于相邻层的两个神经元之间的计算,且前一层神经元的输出是后一层的神经元的输入。 设对于第n层的第i个神经元,有n-1层的M(M为超参数)个神经元与该神经元有突触相连,则第n层第i个神经元的输入为: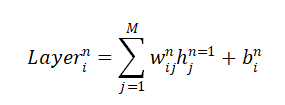 第n层的第i个神经元的输出为: 第n层的第i个神经元的输出为: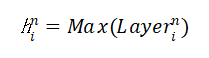 反向传播算法 结合前向传播的两个式子,得到第n层第i个神经元的输入与第n-1层第i个神经元的输出的关系为: 反向传播算法 结合前向传播的两个式子,得到第n层第i个神经元的输入与第n-1层第i个神经元的输出的关系为: 梯度下降算法 得到每一个隐藏层的连接权重和偏置项的梯度后,利用学习率和梯度下降算法更新每一层的连接权重和偏置项: 梯度下降算法 得到每一个隐藏层的连接权重和偏置项的梯度后,利用学习率和梯度下降算法更新每一层的连接权重和偏置项: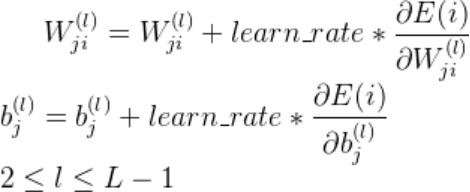 学习率更新策略 在配合梯度下降优化的过程中,如果学习率设置过大,则容易导致模型过拟合;如果设置过小,会使得模型优化的速度变得很缓慢。为此加入衰减因子和学习次数来计算模型每次学习的学习率: 学习率更新策略 在配合梯度下降优化的过程中,如果学习率设置过大,则容易导致模型过拟合;如果设置过小,会使得模型优化的速度变得很缓慢。为此加入衰减因子和学习次数来计算模型每次学习的学习率: 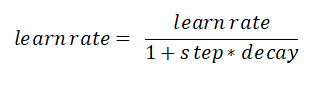 归一化与反归一化 归一化与反归一化   随机重启算法 为了防止更新参数时陷入局部极小,采用随机重启的方式更换初始参数状态。超参数M的确定 本程序的超参数M的确定方法为随机搜索法,最终确定M的取值为20。编程环境和程序主要函数说明 全部内容均在JetBrains发布的PyCharm社区版(版本号2019.2.5)编程环境中完成,使用的语言为Python,解释器为Python3.8。 随机重启算法 为了防止更新参数时陷入局部极小,采用随机重启的方式更换初始参数状态。超参数M的确定 本程序的超参数M的确定方法为随机搜索法,最终确定M的取值为20。编程环境和程序主要函数说明 全部内容均在JetBrains发布的PyCharm社区版(版本号2019.2.5)编程环境中完成,使用的语言为Python,解释器为Python3.8。
#产生数据,并将产生的数据方阵降维,方便计算处理 def init(inpit_n_row): #激活函数 def relu(x): #激活函数RELU的导数 def d_relu(x): #归一化数据 def normalize(data): #反归一化数据 def d_normalize(norm_data, data): #计算损失函数:平方损失函数 def quadratic_cost(y_, y): #评价函数RSSE def rsse(y_predict, y): #前向传播算法 def prediction(l0, W, B): #反向传播算法:根据损失函数优化各个隐藏层的权重 def optimizer(Layers, W, B, y, learn_rate): #训练BP神经网络 def train(X, y, W, B, method, learn_rate): #拟合曲面可视化 def visualize(y, inpit_n_row, input_n_col, hidden_n_1): #为了解决陷入局部极小值,随机重启 def random_restart(): #main()函数 if name == ‘main’: 结果分析与讨论
|
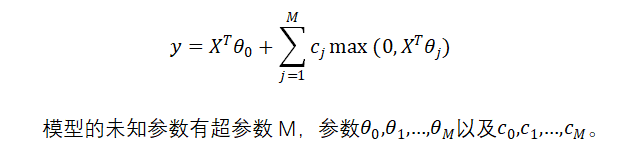
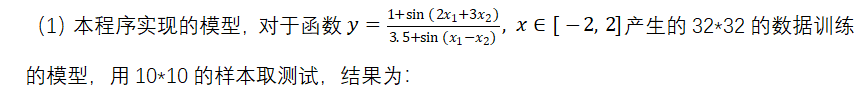


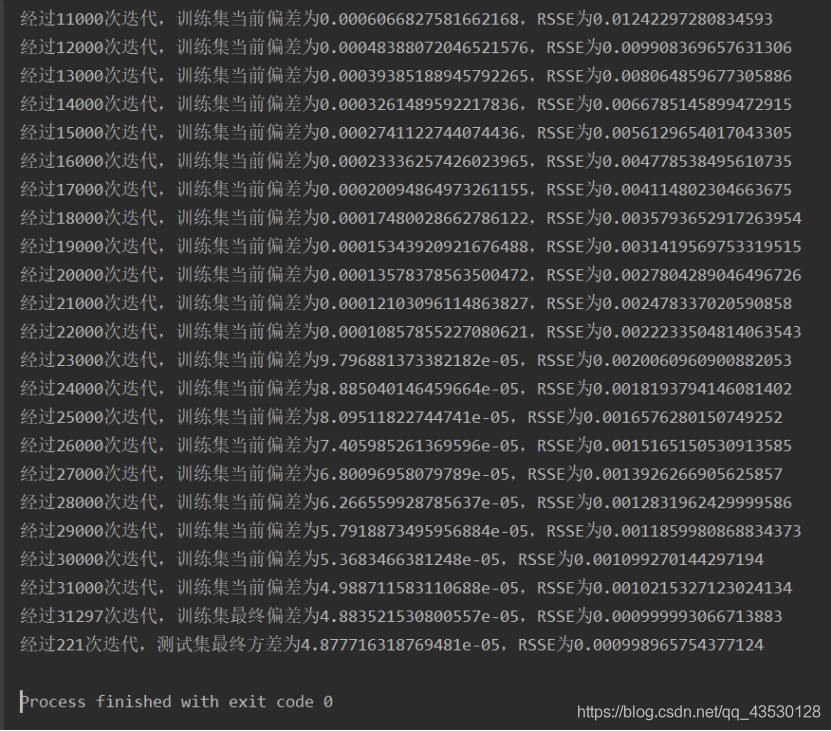
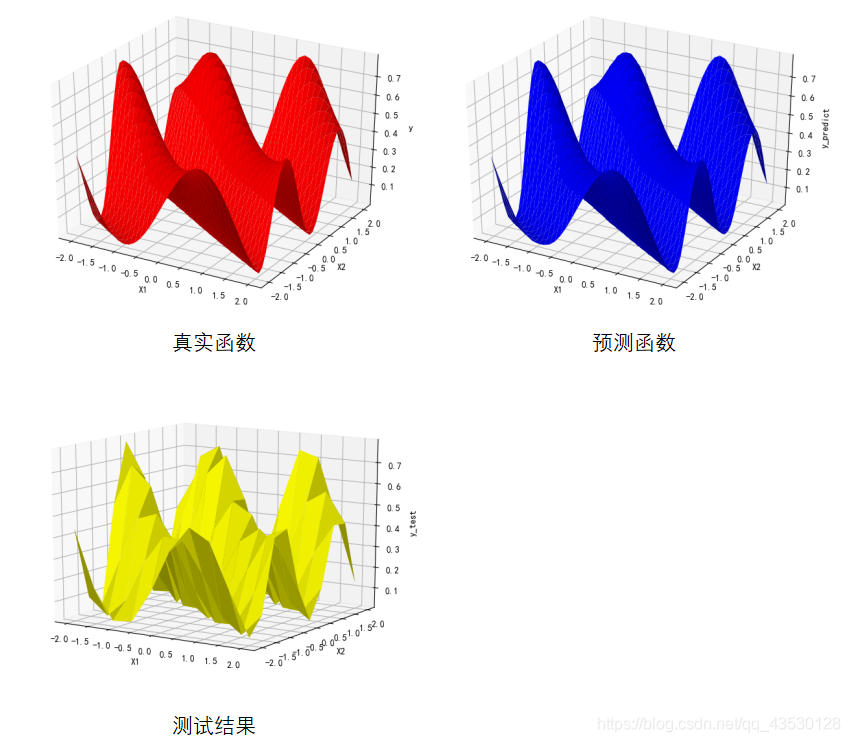 对于3232的训练集,需要几千次的迭代,即可使模型的RSSE值降到0.1以下,需要10000-32000次左右的迭代,即可使模型的RSSE值降到0.001以下;对于1010的测试集,需要30-90次的迭代即可使其RSSE值降到0.1以下,需要200-300次左右的迭代,即可使其的RSSE值降到0.001以下。 (2)抗噪测试 加入高斯白噪声:a = (np.random.random() - 0.5)/5
对于3232的训练集,需要几千次的迭代,即可使模型的RSSE值降到0.1以下,需要10000-32000次左右的迭代,即可使模型的RSSE值降到0.001以下;对于1010的测试集,需要30-90次的迭代即可使其RSSE值降到0.1以下,需要200-300次左右的迭代,即可使其的RSSE值降到0.001以下。 (2)抗噪测试 加入高斯白噪声:a = (np.random.random() - 0.5)/5 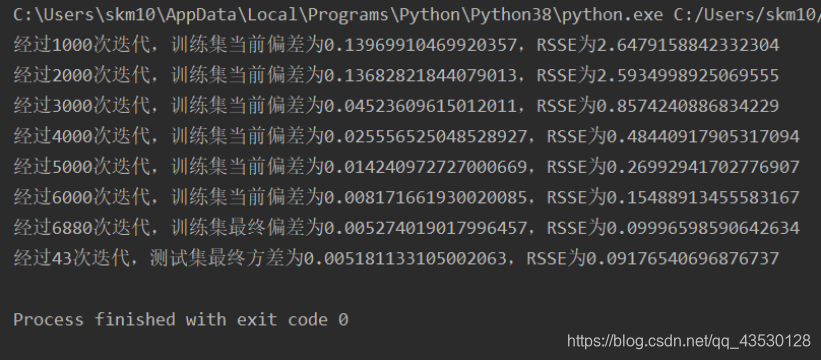
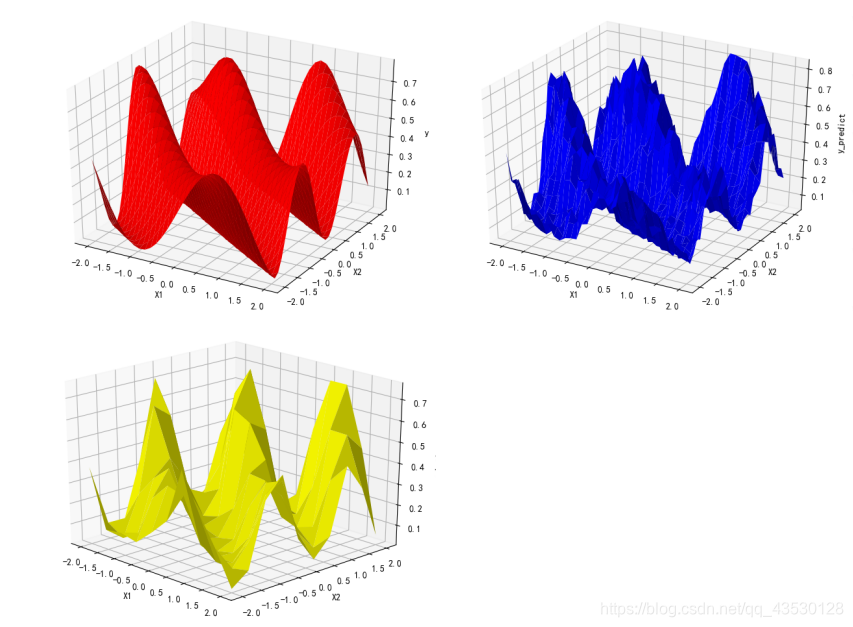 加入野值: b = (np.random.randint(0, 9) - 0.5)/ 9 post = np.random.randint(0, inpit_n_row - 1) y[post] += b
加入野值: b = (np.random.randint(0, 9) - 0.5)/ 9 post = np.random.randint(0, inpit_n_row - 1) y[post] += b 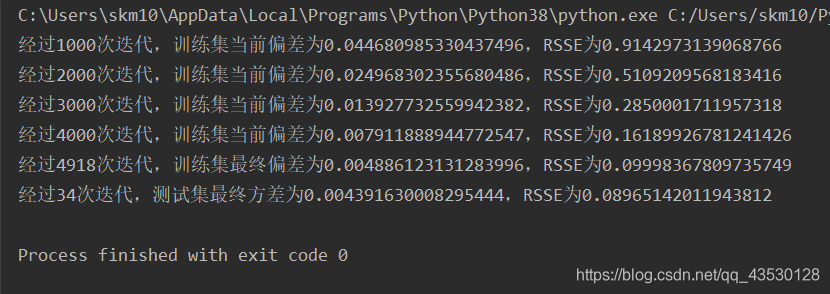
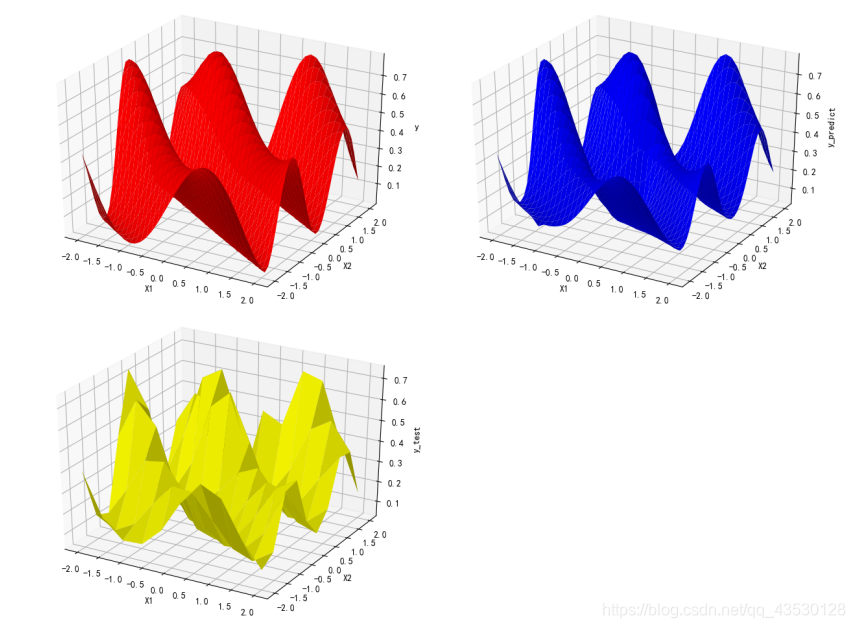 由此可见,模型的抗噪能力良好。
由此可见,模型的抗噪能力良好。【本文地址】