|
原创文章,转载请说明来自:《老饼讲解-BP神经网络》
目录
一. 归一化与反归一化
二. 例子实讲
三. 完整代码例子
四.网络表达式的反归一化
为了方便网络训练得更优秀,一般会先将输入输出数据归一化,再进行训练。训练完后,在用网络预测时,还需要将网络的预测值反归一化。
本文讲述神经网络的归一化和反归一化
一. 归一化与反归一化
训练前,为避免各个输入变量的数量级差异过大,影响求解算法的效果,一般会先将数据归一化到[-1,1]的区间。
PASS: 归一化的好处不仅仅是为了避免数量级的影响。详细可以看文章 《 神经网络为什么要归一化》
(1) 训练前数据的归一化公式

(2) 使用时将 y 反归一化
由于我们用的是归一化后的数据进行训练的。所以网络是针对归一化后的数据的。
因此,我们在使用训练好的网络时作预测时,输入输出都要做数据转换,需要:
(1) 预测时将输入归一化
(2) 将输出反归一化
输出的反归一函数:

二. 例子实讲
1.训练前数据进行归一化
设我们原始数据如下:
x15-238x24216y052-5
可知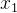 的最大值为8,最小值为-2,则归一化后的值如下: 的最大值为8,最小值为-2,则归一化后的值如下:
原始数据:x15-238归一化后:(x1-(-1)) / (8-(-2))-10.4-101
同样处理 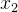 和 y,得到归一化后的数据如下: 和 y,得到归一化后的数据如下:
归一化后的数据x10.4-101x20.2-0.6-11y010.4-1
2. 训练后使用时反归一化
例如,要预测 x1 = 2, x2 = 3, 操作如下:
(1) 先将 x1,x2 归一化再输入网络
在做归一化时候我们知道 : x1 的最大值为8,最小值为 -2,x2的最大值为6,最小值为1,
那么x1,x2归一化后的值为:

预测时输入网络的值为: sim(net,[-0.2,-0.2])
(2)假设上面的网络输出是0.5,但这是针对归一化数据的,要获得真实的预测值,我们需要反归一化。
我们在归一化时,知道: y的最大值为5,最小值为-5,
则反归一后的 y:
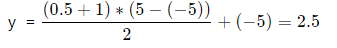
三. 完整代码例子
x1 = linspace(-3,3,100); % 在[-3,3]之间线性生成100个数据
x2 = linspace(-2,1.5,100); % 在[-2,1.5]之间线性生成100个数据
y = sin(x1)+0.2*x2.*x2; % 生成y
inputData = [x1;x2]; % 将x1,x2作为输入数据
outputData = y; % 将y作为输出数据
%归一化处理:
inputMax = max(inputData,[],2); % 输入的最大值
inputMin = min(inputData,[],2); % 输入的最小值
outputMax = max(outputData,[],2); % 输出的最大值
outputMin = min(outputData,[],2); % 输出的最小值
[varNum,sampleNum] = size(inputData);
inputDataNorm = inputData; % 初始化inputDataNorm
outputDataNorm = outputData; % 初始化outputDataNorm
%进行归一化
for i = 1 : sampleNum
inputDataNorm(:,i) = 2*(inputData(:,i)-inputMin)./(inputMax-inputMin)-1;
outputDataNorm(:,i) = 2*(outputData(:,i)-outputMin)./(outputMax-outputMin)-1;
end
%使用用输入输出数据(inputDataNorm、outputDataNorm)建立网络,隐节点个数设为3.其中输入层到隐层、隐层到输出层的节点分别为tansig和purelin,使用trainlm方法训练。
net = newff(inputDataNorm,outputDataNorm,3,{'tansig','purelin'},'trainlm');
%设置一些常用参数
net.trainparam.goal = 0.0001; % 训练目标:均方误差低于0.0001
net.trainparam.show = 400; % 每训练400次展示一次结果
net.trainparam.epochs = 15000; % 最大训练次数:15000.
[net,tr] = train(net,inputDataNorm,outputDataNorm);%调用matlab神经网络工具箱自带的train函数训练网络
figure;
%训练数据的拟合效果
simoutNorm = sim(net,inputDataNorm);
%反归一化:
simout=(simoutNorm+1).*(outputMax-outputMin)/2+outputMin;
title('神经网络预测结果')
hold on
t=1:length(simout);
plot(t,outputData,t,simout,'r')%画图,对比原来的y和网络预测的y
四.网络表达式的反归一化
神经网络归一化后,训练得到的模型系数都是对应归一化数据的。要想得到对应原始数据的模型系数,则需要对模型系数反归一化,具体见《网络表达式的反归一化》
相关文章
《BP神经网络梯度推导》
《BP神经网络提取的数学表达式》
《一个BP的完整建模流程》
|