| 人工神经网络 | 您所在的位置:网站首页 › 神经网络bp算法实现方法 › 人工神经网络 |
人工神经网络
|
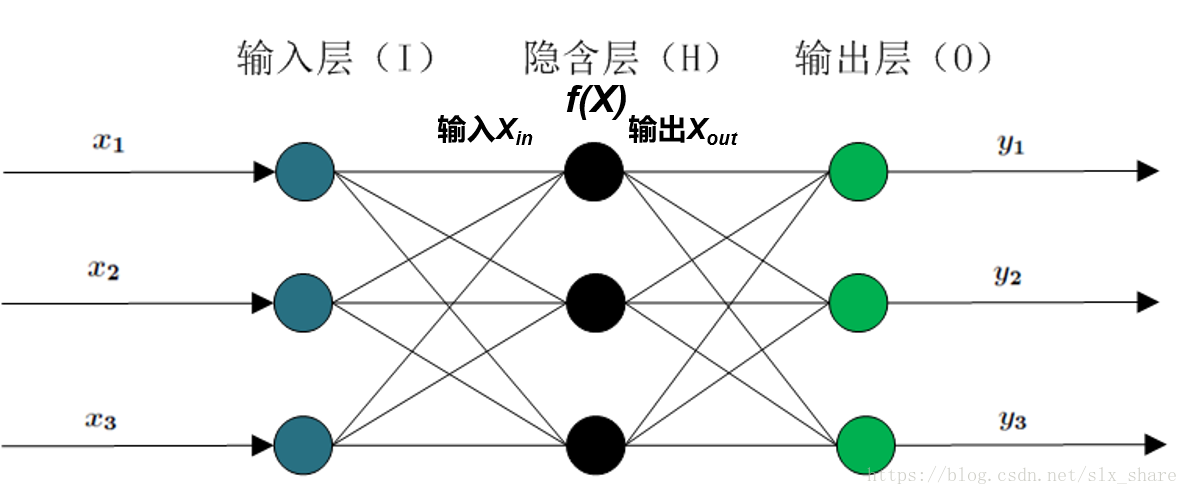
人工神经网络是模拟生物神经系统的。神经元之间是通过轴突、树突互相连接的,神经元收到刺激时,神经脉冲在神经元之间传播,同时反复的脉冲刺激,使得神经元之间的联系加强。受此启发,人工神经网络中神经元之间的联系(权值)也是通过反复的数据信息"刺激"而得到调整的。而反向传播(back propagation)算法就是用来调整权值的。 核心思想训练误差逐层反向传播,每层神经元与下层神经元间权重通过误差最速梯度下降的方法调整。 算法简介 人工神经网络简介通常人工神经网络分为输入层、隐藏层和输出层。隐藏层和输出层都有相应的激励函数(模拟神经脉冲的激励方式)。隐藏层可以为多层,但实际上不超过三层为好。如图: 训练数据包含的信息逐层从输入层传播到输出层的方式是以感知机为基础的。即 X h i d d e n _ i n = W i n p u t _ h i d d e n X i n p u t X h i d d e n _ o u t = f h i d d e n ( X h i d d e n _ i n ) X o u t p u t _ i n = W h i d d e n _ o u t p u t X h i d d e n _ o u t X o u t p u t _ o u t = f o u t p u t ( X o u t p u t _ i n ) X_{hidden\_in} = W_{input\_hidden}X_{input}\\X_{hidden\_out}=f_{hidden}(X_{hidden\_in})\\X_{output\_in} = W_{hidden\_output}X_{hidden\_out}\\X_{output\_out=f_{output}}(X_{output\_in}) Xhidden_in=Winput_hiddenXinputXhidden_out=fhidden(Xhidden_in)Xoutput_in=Whidden_outputXhidden_outXoutput_out=foutput(Xoutput_in) 误差反向传播与前向传播正好相反,训练误差都是从输出层开始反向传播到每个隐藏层。有了每一层的误差就好办了,训练的目的就是减小误差,即最小化期望风险,通常采用平方误差损失函数
E
=
1
2
(
y
p
r
e
d
−
y
t
r
u
e
)
2
E = \frac{1}{2}(y_{pred}-y_{true})^2
E=21(ypred−ytrue)2,采用最速梯度下降法更新权值。 根据链式法则计算每层权值调整梯度: -------------------------------------------------------------------------------------- 举例如下: 输出层梯度: ∂ E ∂ X o u t p u t _ o u t = G o u t = X o u t p u t _ o u t − y t r u e \frac{\partial E}{\partial X_{output\_out}}=G_{out} = X_{output\_out}-y_{true} ∂Xoutput_out∂E=Gout=Xoutput_out−ytrue即输出层的误差。 隐藏层到输出层权值梯度: G h i d d e n _ o u t = X h i d d e n _ o u t δ h i d d e n _ o u t p u t δ h i d d e n _ o u t p u t = − G o u t ∗ f o u t p u t ′ ( X o u t p u t _ i n ) 其 中 , ∂ X o u t p u t _ o u t ∂ X o u t p u t _ i n = f o u t p u t ′ ( X o u t p u t _ i n ) G_{hidden\_out}=X_{hidden\_out}\delta_{hidden\_output}\\ \delta_{hidden\_output} = - G_{out} *f_{output}^{'}(X_{output\_in}) \\ 其中,\frac{\partial X_{output\_out}}{\partial X_{output\_in}} = f_{output}^{'}(X_{output\_in}) Ghidden_out=Xhidden_outδhidden_outputδhidden_output=−Gout∗foutput′(Xoutput_in)其中,∂Xoutput_in∂Xoutput_out=foutput′(Xoutput_in) 输入层到隐藏层权值梯度: G i n p u t _ h i d d e n = X i n p u t δ i n p u t _ h i d d e n δ i n p u t _ h i d d e n = δ h i d d e n _ o u t p u t W h i d d e n _ o u t p u t ∗ f h i d d e n ′ ( X h i d d e n _ i n ) 其 中 , ∂ X o u t p u t _ i n ∂ X h i d d e n _ o u t = W h i d d e n _ o u t p u t , ∂ X h i d d e n _ o u t ∂ X h i d d e n _ i n = f h i d d e n ′ ( X h i d d e n _ i n ) G_{input\_hidden}=X_{input}\delta_{input\_hidden}\\\delta_{input\_hidden} = \delta_{hidden\_output} W_{hidden\_output}*f_{hidden}^{'}(X_{hidden\_in}) \\ 其中,\frac{\partial X_{output\_in}}{\partial X_{hidden\_out}}=W_{hidden\_output},\frac{\partial X_{hidden\_out}}{\partial X_{hidden\_in}} = f_{hidden}^{'}(X_{hidden\_in}) Ginput_hidden=Xinputδinput_hiddenδinput_hidden=δhidden_outputWhidden_output∗fhidden′(Xhidden_in)其中,∂Xhidden_out∂Xoutput_in=Whidden_output,∂Xhidden_in∂Xhidden_out=fhidden′(Xhidden_in)这里, δ h i d d e n _ o u t p u t W h i d d e n _ o u t p u t \delta_{hidden\_output} W_{hidden\_output} δhidden_outputWhidden_output相当于反向传播到隐藏层的误差。 隐藏层到输出层权值更新: Δ W h i d d e n _ o u t p u t = η G h i d d e n _ o u t + α Δ W h i d d e n _ o u t p u t p r e v i o u s \Delta W_{hidden\_output}=\eta G_{hidden\_out} + \alpha\Delta W_{hidden\_output}^{previous} ΔWhidden_output=ηGhidden_out+αΔWhidden_outputprevious 输入层到隐藏层权值更新: Δ W i n p u t _ h i d d e n = η G i n p u t _ h i d d e n + α Δ W i n p u t _ h i d d e n p r e v i o u s \Delta W_{input\_hidden}=\eta G_{input\_hidden}+\alpha\Delta W_{input\_hidden}^{previous} ΔWinput_hidden=ηGinput_hidden+αΔWinput_hiddenprevious 注:*表示对应元素相称,其他为矩阵乘法, f f f为激励函数, α \alpha α为动量项前系数。 η \eta η为学习率 算法流程 Input: 训练数据集X_data和y_data, 神经网络必要参数,阈值epsilon,最大迭代次数maxstepOutput: 神经网络权值WStep1: 初始化权值矩阵W,阈值bStep2: 迭代训练直到误差小于阈值epsilon或达到最大迭代次数maxstep。训练步骤包括前向传播和误差反向传播。 代码 """ BP神经网络 """ import numpy as np import math # 激励函数及相应导数,后续可添加 def sigmoid(x): return 1.0 / (1 + np.exp(-x)) def diff_sigmoid(x): fval = sigmoid(x) return fval * (1 - fval) def linear(x): return x def diff_linear(x): return np.ones_like(x) class BP: def __init__(self, n_hidden=None, f_hidden='sigmoid', f_output='sigmoid', epsilon=1e-3, maxstep=1000, eta=0.1, alpha=0.0): self.n_input = None # 输入层神经元数目 self.n_hidden = n_hidden # 隐藏层神经元数目 self.n_output = None self.f_hidden = f_hidden self.f_output = f_output self.epsilon = epsilon self.maxstep = maxstep self.eta = eta # 学习率 self.alpha = alpha # 动量因子 self.wih = None # 输入层到隐藏层权值矩阵 self.who = None # 隐藏层到输出层权值矩阵 self.bih = None # 输入层到隐藏层阈值 self.bho = None # 隐藏层到输出层阈值 self.N = None def init_param(self, X_data, y_data): # 初始化 if len(X_data.shape) == 1: # 若输入数据为一维数组,则进行转置为n维数组 X_data = np.transpose([X_data]) self.N = X_data.shape[0] # normalizer = np.linalg.norm(X_data, axis=0) # X_data = X_data / normalizer if len(y_data.shape) == 1: y_data = np.transpose([y_data]) self.n_input = X_data.shape[1] self.n_output = y_data.shape[1] if self.n_hidden is None: self.n_hidden = int(math.ceil(math.sqrt(self.n_input + self.n_output)) + 2) self.wih = np.random.rand(self.n_input, self.n_hidden) # i*h self.who = np.random.rand(self.n_hidden, self.n_output) # h*o self.bih = np.random.rand(self.n_hidden) # h self.bho = np.random.rand(self.n_output) # o return X_data, y_data def inspirit(self, name): # 获取相应的激励函数 if name == 'sigmoid': return sigmoid elif name == 'linear': return linear else: raise ValueError('the function is not supported now') def diff_inspirit(self, name): # 获取相应的激励函数的导数 if name == 'sigmoid': return diff_sigmoid elif name == 'linear': return diff_linear else: raise ValueError('the function is not supported now') def forward(self, X_data): # 前向传播 x_hidden_in = X_data @ self.wih + self.bih # n*h x_hidden_out = self.inspirit(self.f_hidden)(x_hidden_in) # n*h x_output_in = x_hidden_out @ self.who + self.bho # n*o x_output_out = self.inspirit(self.f_output)(x_output_in) # n*o return x_output_out, x_output_in, x_hidden_out, x_hidden_in def fit(self, X_data, y_data): # 训练主函数 X_data, y_data = self.init_param(X_data, y_data) step = 0 # 初始化动量项 delta_wih = np.zeros_like(self.wih) delta_who = np.zeros_like(self.who) delta_bih = np.zeros_like(self.bih) delta_bho = np.zeros_like(self.bho) while step |
 常用的激励函数有sigmoid和linear函数。如果使用神经网络来做分类的工作,那么输出层激励函数通常采用sigmoid, 若做回归工作,就采用linear函数。输入层和输出层神经元数目由训练数据集而定,而隐藏层神经元数目的设定带有很大的经验性,对经验公式
n
i
n
p
u
t
+
n
o
u
t
p
u
t
+
2
\sqrt {n_{input}+n_{output}} + 2
ninput+noutput
+2(
n
i
n
p
u
t
,
n
o
u
t
p
u
t
n_{input},n_{output}
ninput,noutput为输入层、输出层神经元数目)向上取整的数值可作为隐藏层神经元数目。
常用的激励函数有sigmoid和linear函数。如果使用神经网络来做分类的工作,那么输出层激励函数通常采用sigmoid, 若做回归工作,就采用linear函数。输入层和输出层神经元数目由训练数据集而定,而隐藏层神经元数目的设定带有很大的经验性,对经验公式
n
i
n
p
u
t
+
n
o
u
t
p
u
t
+
2
\sqrt {n_{input}+n_{output}} + 2
ninput+noutput
+2(
n
i
n
p
u
t
,
n
o
u
t
p
u
t
n_{input},n_{output}
ninput,noutput为输入层、输出层神经元数目)向上取整的数值可作为隐藏层神经元数目。 ∂
E
∂
W
i
n
p
u
t
_
h
i
d
d
e
n
=
∂
E
∂
X
o
u
t
p
u
t
_
o
u
t
∂
X
o
u
t
p
u
t
_
o
u
t
∂
X
o
u
t
p
u
t
_
i
n
∂
X
o
u
t
p
u
t
_
i
n
∂
X
h
i
d
d
e
n
_
o
u
t
∂
X
h
i
d
d
e
n
_
o
u
t
∂
X
h
i
d
d
e
n
_
i
n
∂
X
h
i
d
d
e
n
_
i
n
∂
W
i
n
p
u
t
_
h
i
d
d
e
n
\frac{\partial E}{\partial W_{input\_hidden}} = \frac{\partial E}{\partial X_{output\_out}}\frac{\partial X_{output\_out}}{\partial X_{output\_in}}\frac{\partial X_{output\_in}}{\partial X_{hidden\_out}}\frac{\partial X_{hidden\_out}}{\partial X_{hidden\_in}}\frac{\partial X_{hidden\_in}}{\partial W_{input\_hidden}}
∂Winput_hidden∂E=∂Xoutput_out∂E∂Xoutput_in∂Xoutput_out∂Xhidden_out∂Xoutput_in∂Xhidden_in∂Xhidden_out∂Winput_hidden∂Xhidden_in --------------------------------------------------------------------------------------
∂
E
∂
W
i
n
p
u
t
_
h
i
d
d
e
n
=
∂
E
∂
X
o
u
t
p
u
t
_
o
u
t
∂
X
o
u
t
p
u
t
_
o
u
t
∂
X
o
u
t
p
u
t
_
i
n
∂
X
o
u
t
p
u
t
_
i
n
∂
X
h
i
d
d
e
n
_
o
u
t
∂
X
h
i
d
d
e
n
_
o
u
t
∂
X
h
i
d
d
e
n
_
i
n
∂
X
h
i
d
d
e
n
_
i
n
∂
W
i
n
p
u
t
_
h
i
d
d
e
n
\frac{\partial E}{\partial W_{input\_hidden}} = \frac{\partial E}{\partial X_{output\_out}}\frac{\partial X_{output\_out}}{\partial X_{output\_in}}\frac{\partial X_{output\_in}}{\partial X_{hidden\_out}}\frac{\partial X_{hidden\_out}}{\partial X_{hidden\_in}}\frac{\partial X_{hidden\_in}}{\partial W_{input\_hidden}}
∂Winput_hidden∂E=∂Xoutput_out∂E∂Xoutput_in∂Xoutput_out∂Xhidden_out∂Xoutput_in∂Xhidden_in∂Xhidden_out∂Winput_hidden∂Xhidden_in --------------------------------------------------------------------------------------【本文地址】