| 基于爬虫+词云图+Kmeans聚类+LDA主题分析+社会网络语义分析对大唐不夜城用户评论进行分析 | 您所在的位置:网站首页 › 社会网络大数据分析报告怎么写 › 基于爬虫+词云图+Kmeans聚类+LDA主题分析+社会网络语义分析对大唐不夜城用户评论进行分析 |
基于爬虫+词云图+Kmeans聚类+LDA主题分析+社会网络语义分析对大唐不夜城用户评论进行分析
|
🤵♂️ 个人主页:@艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+
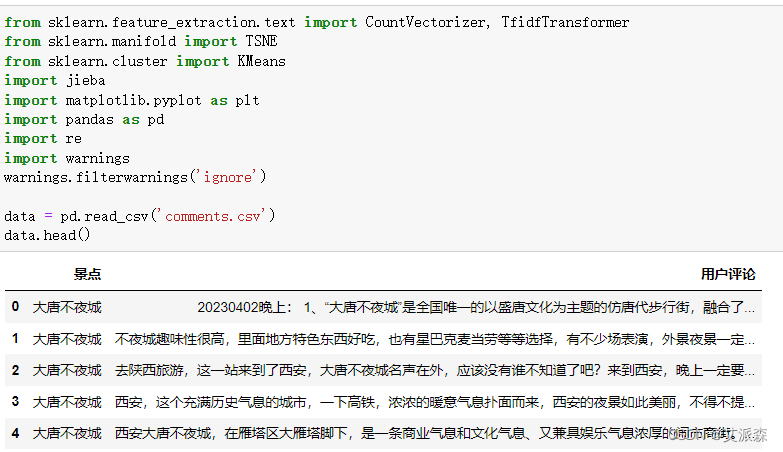
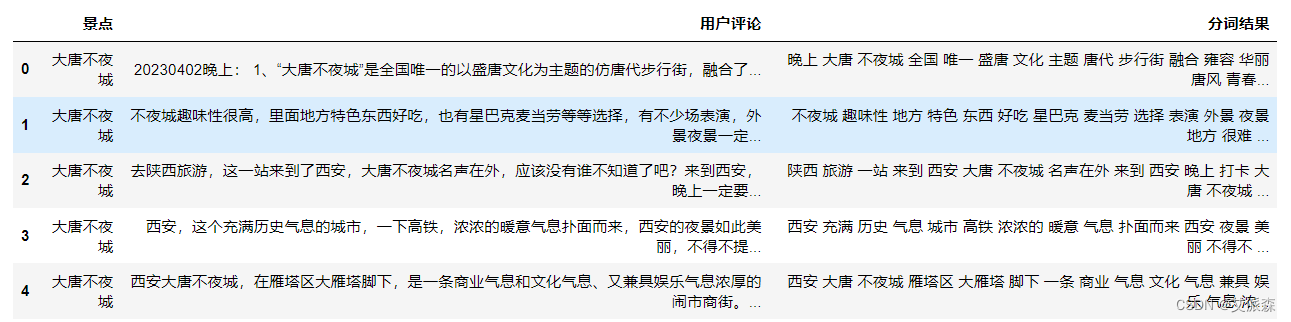
目录 一、项目简介 二、实验过程 2.1获取数据 2.2情感分析 2.3TF-IDF+Kmeans聚类分析 2.4LDA主题分析 2.5社会语义网络分析 三、总结 一、项目简介 本项目是基于携程网中关于大唐不夜城评论的文本分析,项目中用到了Python爬虫、词频分析、词云图分析、kmeans聚类、LDA主题分析、情感分析、社会网络语义分析等。 二、实验过程实验环境 Anaconda Python3.9 2.1获取数据数据目标是获取携程网中关于大唐不夜城景点的评论文本数据
由于该网站抓包不是很方便,于是我果断选择使用selenium自动化工具来爬取数据。该网站也不需要登录,直接可以访问这个页面并且可跳转下一页,最后我们使用CSV文件进行存储。 先导入第三方库 from time import sleep from selenium.webdriver.chrome.service import Service from selenium.webdriver import Chrome,ChromeOptions from selenium.webdriver.common.by import By import warnings import csv import random #忽略警告 warnings.filterwarnings("ignore")创建我们的浏览器并准备好用来存储评论数据的csv文件 # 创建一个驱动 service = Service('./chromedriver.exe') options = ChromeOptions() options.add_experimental_option('excludeSwitches', ['enable-automation','enable-logging']) options.add_experimental_option('useAutomationExtension', False) # 创建一个浏览器 driver = Chrome(service=service,options=options) driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": """ Object.defineProperty(navigator, 'webdriver', { get: () => false }) """ }) with open('comments.csv','a',encoding='utf-8',newline='')as f: csvwriter = csv.writer(f) csvwriter.writerow(('景点','用户评论')) main()接下来就主要编写我们的main()函数,该函数主要就是访问页面获取评论标签元素,一页获取完点击下一页,并用创建的csv文件进行存储。 def main(): driver.get('https://you.ctrip.com/sight/xian7/130441.html') sleep(2) for i in range(109): comment_list = driver.find_elements(By.XPATH,'//*[@id="commentModule"]/div[5]/div/div[2]/div[2]') for item in comment_list: try: comment = item.find_element(By.XPATH,'.').text comment = comment.strip() comment = comment.replace('\n','') csvwriter.writerow(('大唐不夜城',comment)) f.flush() print(comment) except: pass driver.find_element(By.CSS_SELECTOR,'li.ant-pagination-next>span').click() print(f'=====================第{i+1}页爬取完毕!=========================') sleep(random.random()*5)评论一共有109页,于是我们爬取了109页,大概也就1000条评论数据,爬虫运行截图如下:
数据已经准确就绪,下来我们将开始一一分析。 2.2情感分析首先导入我们刚爬取的评论文本数据
使用snownlp情感分析模块进行情感打分
经过了上面的打分操作,现在已经有了每句话都情感分值及其情感类别。 接下来对情感分值和类别进行可视化展示
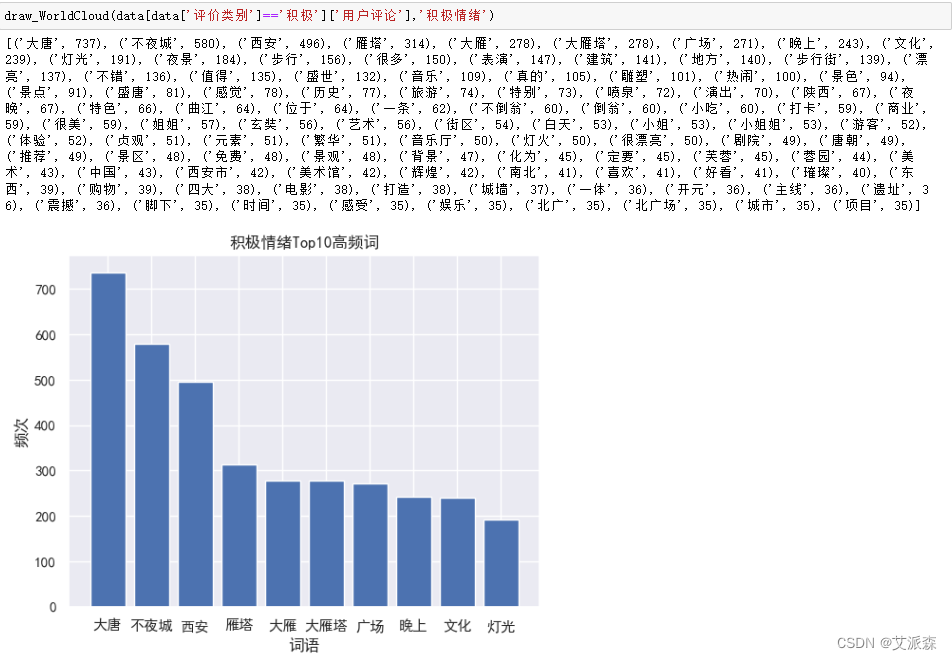
从结果看出评论主要都是积极评论占比88%,只有极少数的中性和消极评论,说明该景点真的很值得去! 接着我们编写一个画词云图的函数,该函数中的功能包括文本预处理、文本分词、去除停用词、词频统计、画出top10词频条形图、画出词云图。
画出积极评论的词云图,调用上面的函数,运行结果如下:
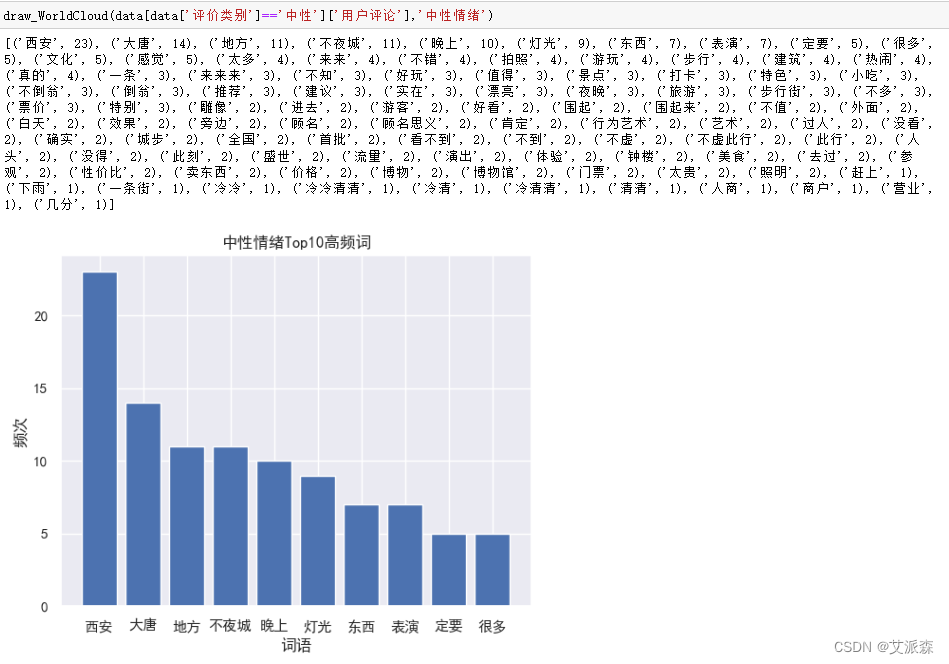
画出中性评论的词云图,调用上面的函数,运行结果如下:
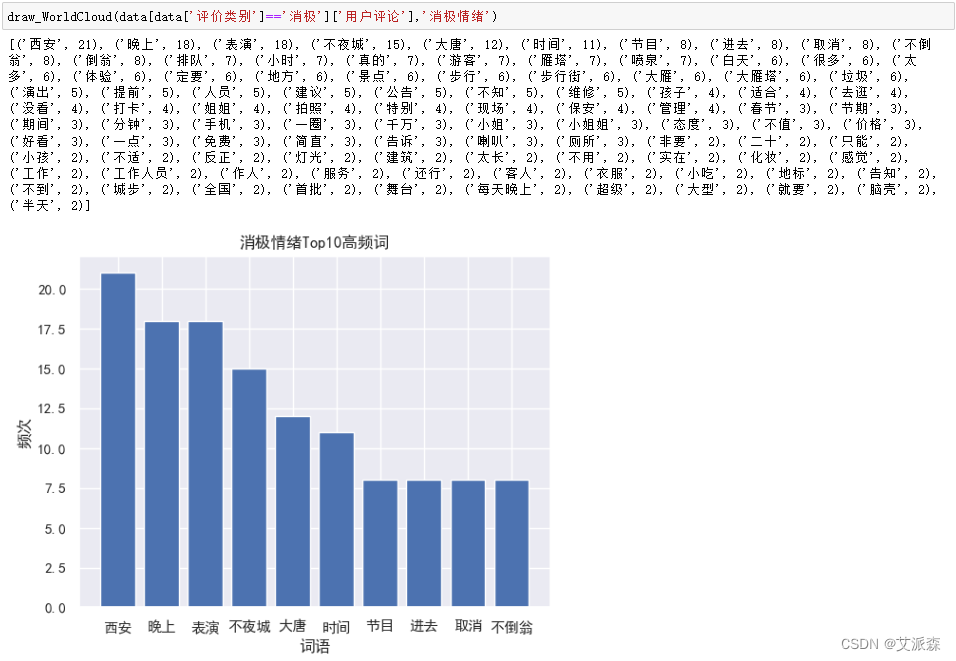
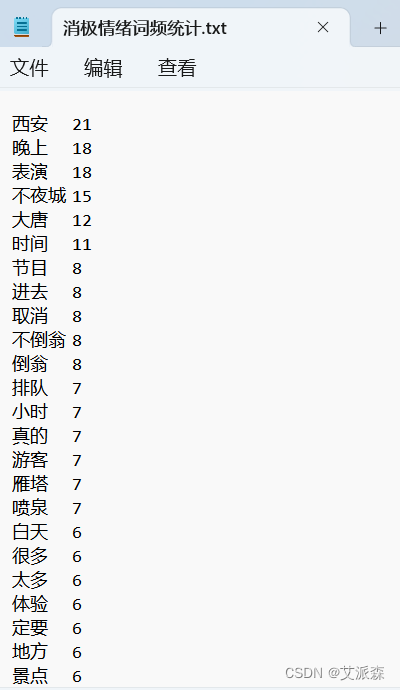
画出消极评论的词云图,调用上面的函数,运行结果如下:
前面我们分别对积极、中性、消极评论进行了词云图分析,我们发现在消极评论中,最突出的问题就是人多拥挤,谁叫它是免费的景点呢,哈哈哈。 2.3TF-IDF+Kmeans聚类分析首先还是导入用到的第三方库以及数据
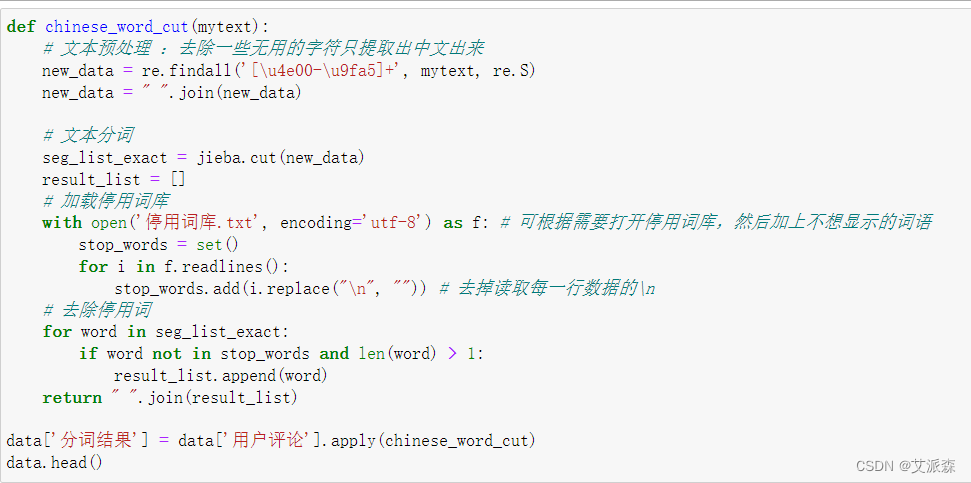
编写一个中文分词的函数
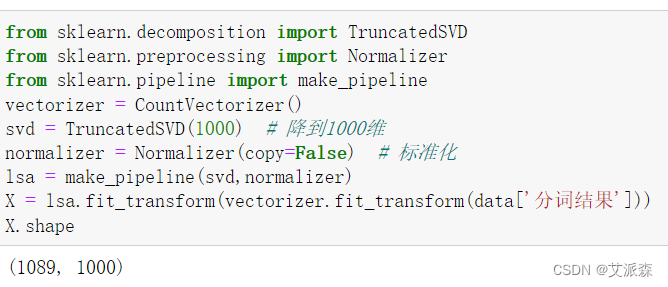
对分词结果进行词向量化并降维到1000维同时进行标准化操作
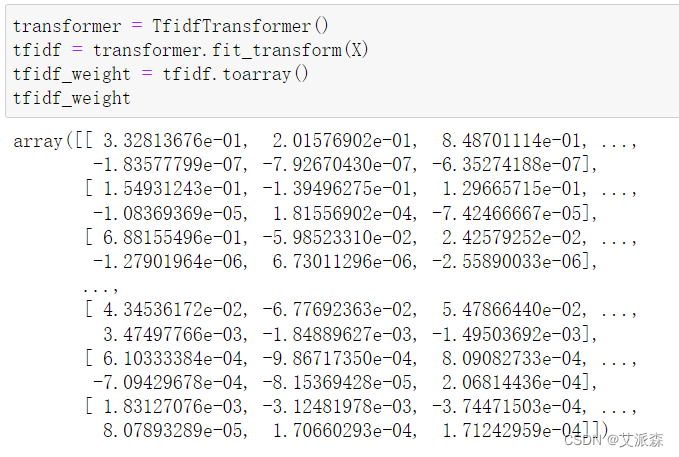
使用TF-IDF提权关键词并获取权重
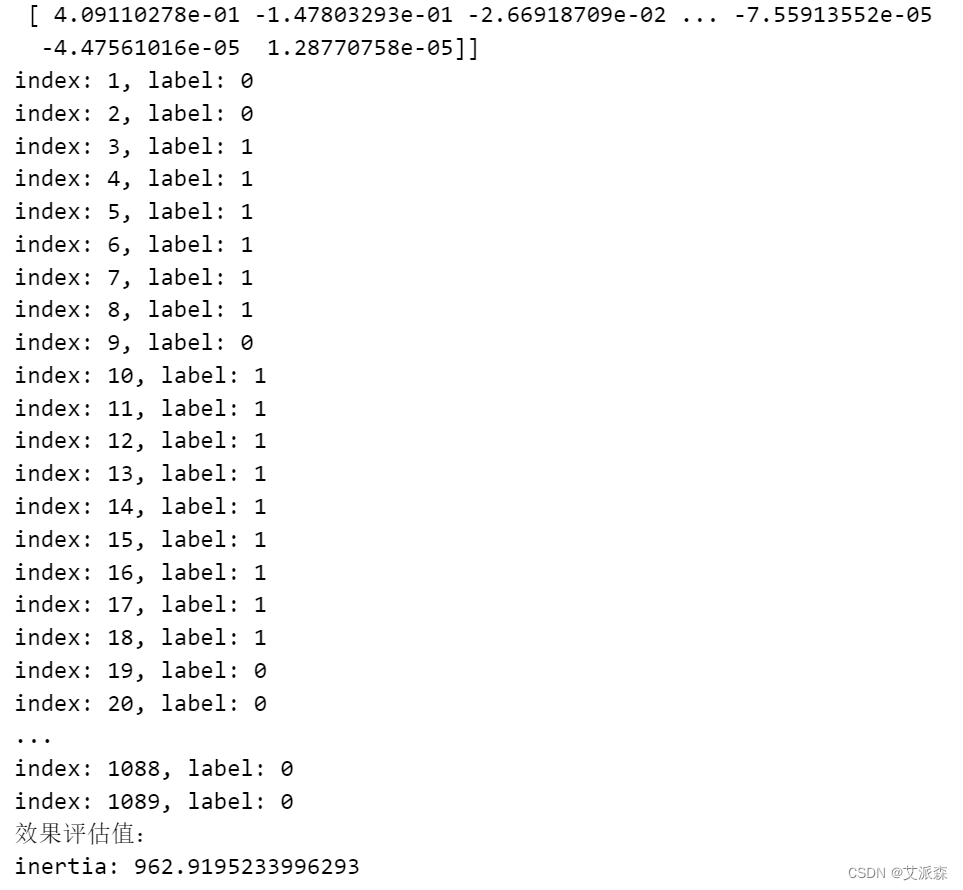
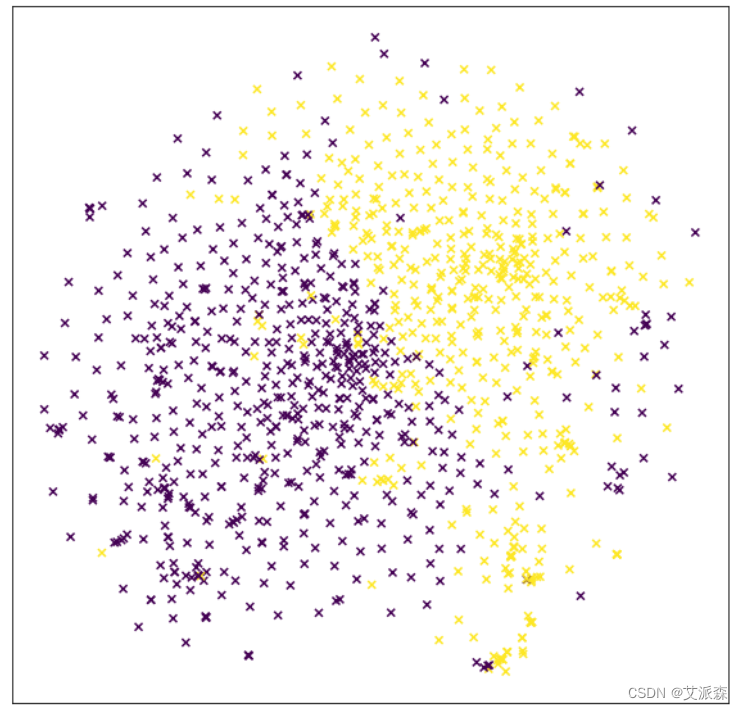
使用Kmeans进行聚类,关于K的确定,我是试了几个数字,发现还是2最合适。
最后将聚类结果进行可视化
首先还是导入我们的数据
在中文分词之前,我们先删除重复数据并且将评论长度小于10的进行剔除,从结果发现,我们剔除了40条评论。
中文分词
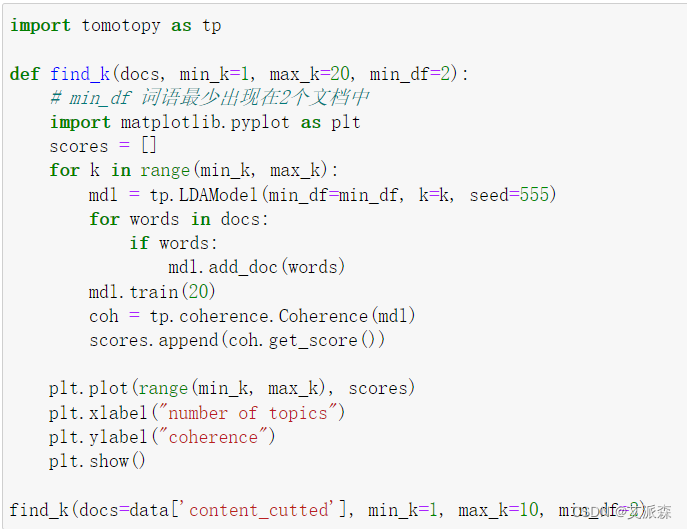
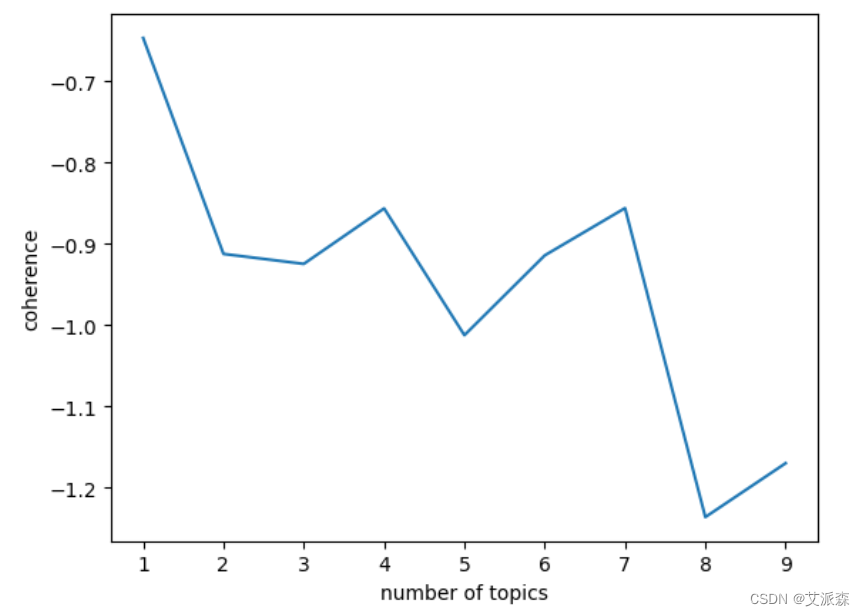
确定最佳主题个数K值
从图可看出,8是最低的点,但是8个主题明显太多,会出现过拟合,所以还剩下3和5。最后经过主题可视化我们最终确定了3是最佳的K值。
可以使用summary查看模型信息
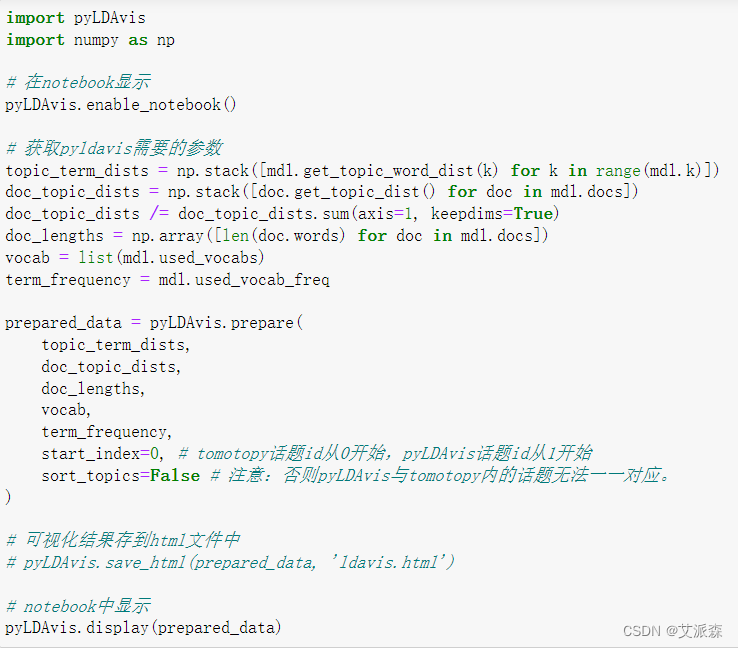
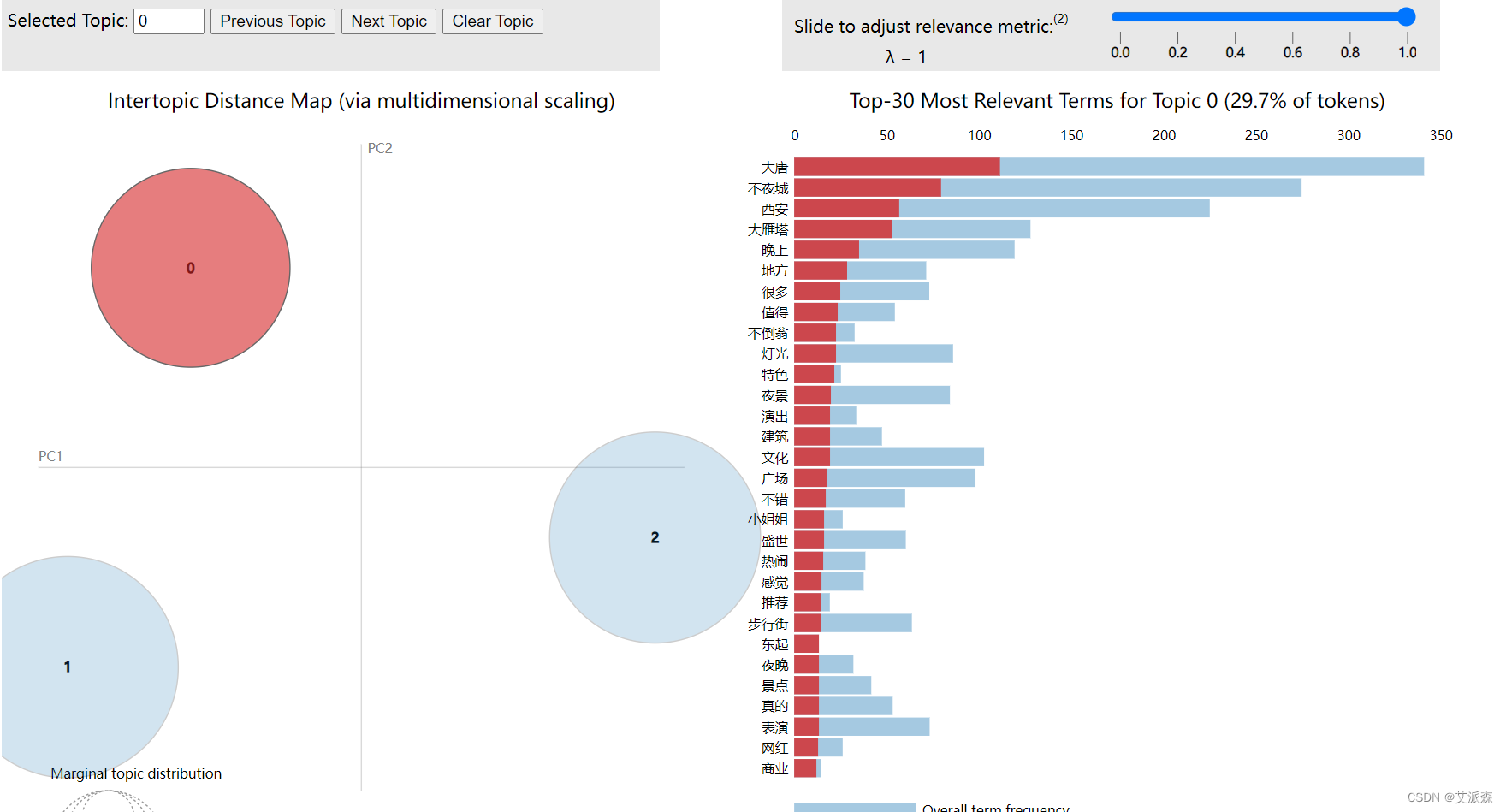
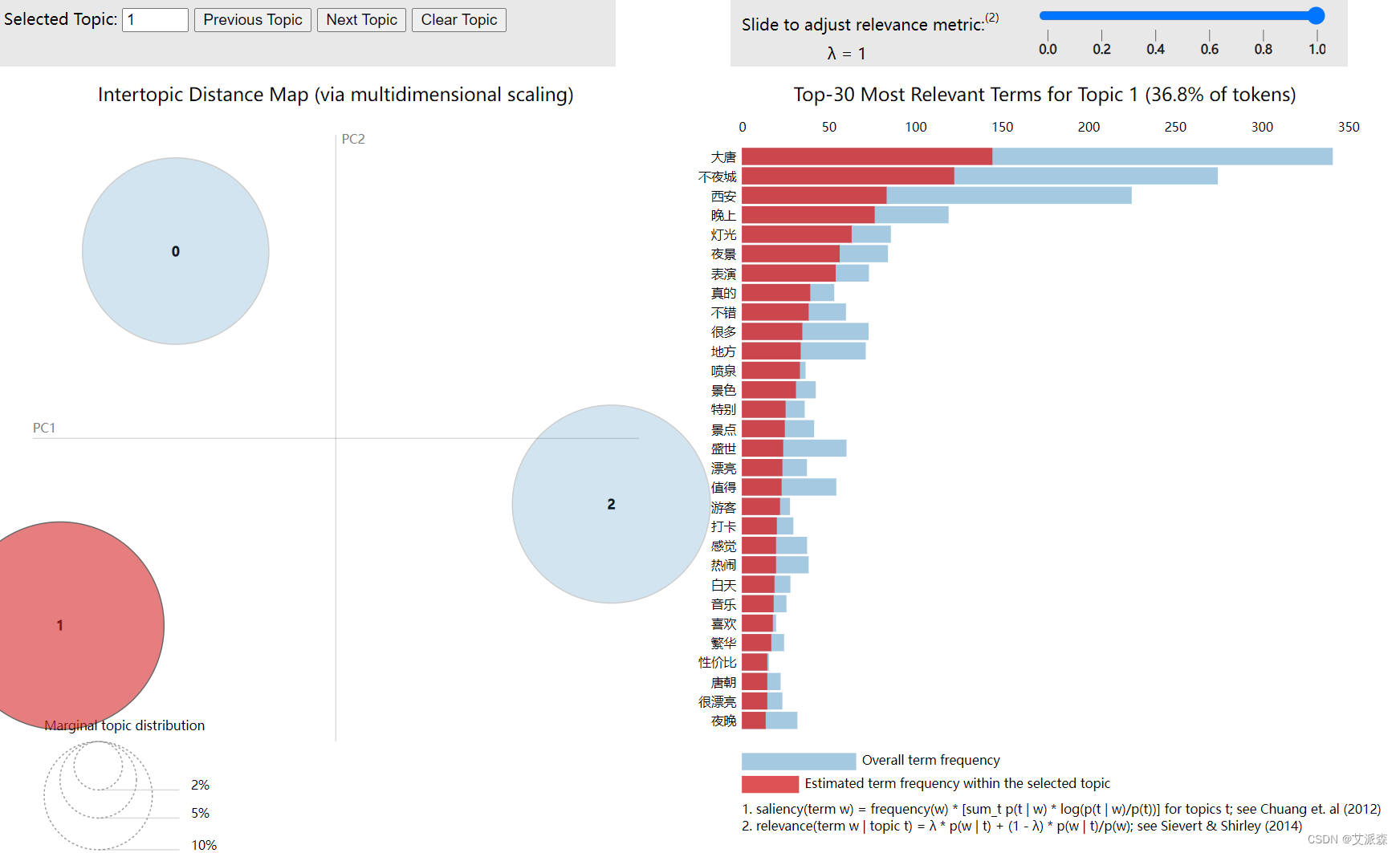
Lda主题可视化
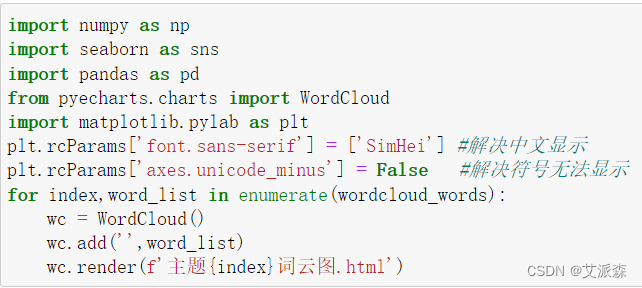
最后我们也可以将每个主题的关键词进行词云图展示
运行完上面的代码会生成3个html页面 主题0词云图
主题1词云图
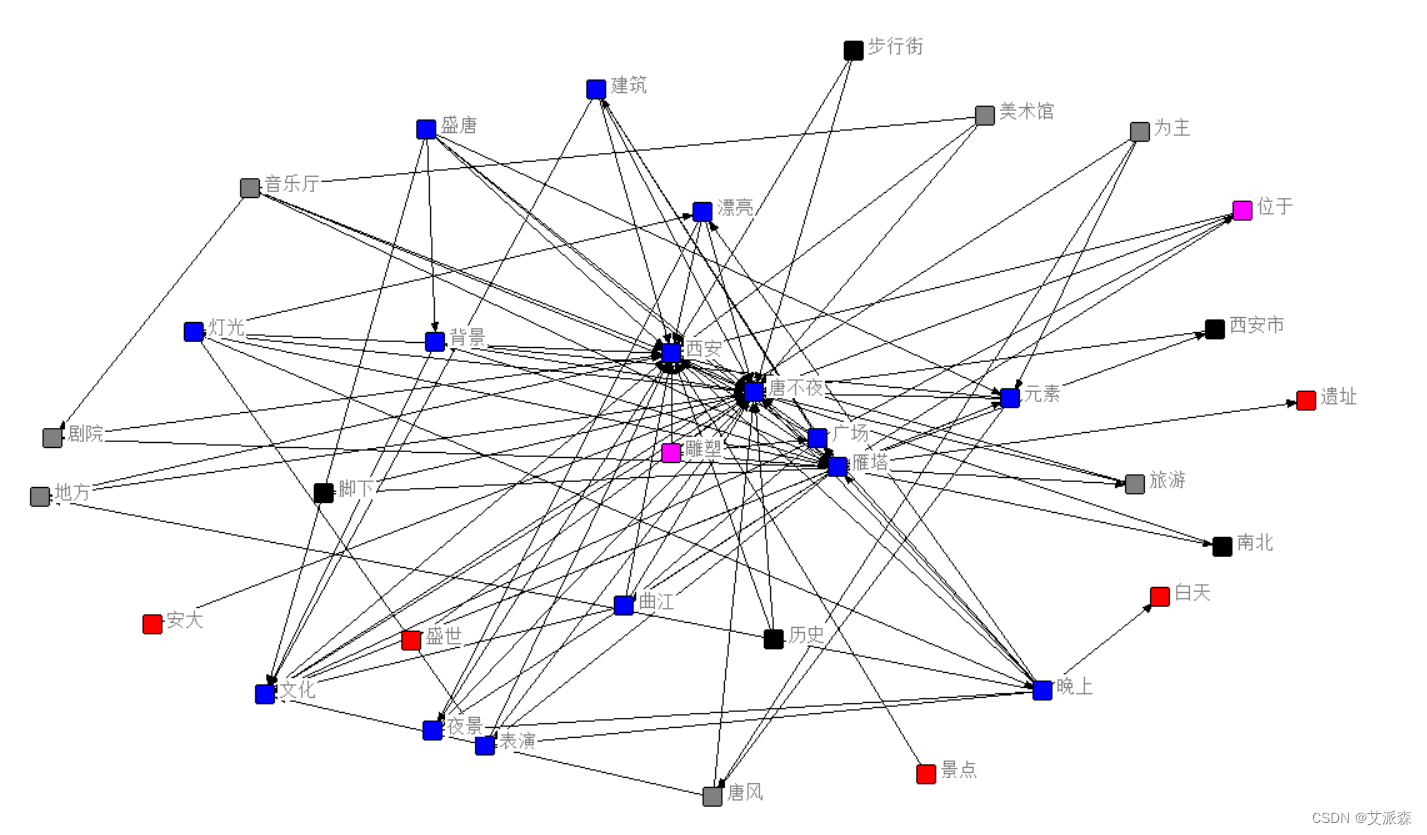
主题2词云图 这里我们主要使用到的工具是ROSTCM6,关于软件的安装及使用可参考我的博文 ROSTCM6软件下载及语义网络分析详细操作教程(附网盘链接)_艾派森的博客-CSDN博客
本次实验我们使用了爬虫、词云图、情感分析、LDA主题分析、TF-IDF+Kmeans、社会网络语义分析等对大唐不夜城的评论进行了分析。关于博文中的源码大家可以关注派森小木屋公众号进入粉丝群领取,如对文章有疑惑,请评论区留言。
|





























【本文地址】