| AVX指令集加速矩阵乘法 | 您所在的位置:网站首页 › 矩阵乘法方法 › AVX指令集加速矩阵乘法 |
AVX指令集加速矩阵乘法
|
AVX简介
SIMD
SIMD(Single Instruction Multiple Data,单指令多数据流),是一种实现空间上的并行性的技术。这种技术使用一个控制器控制多个处理单元,同时对一组数据中的每一个数据执行相同的操作。在 SIMD 指令执行期间,任意时刻都只有一个进程在运行,即 SIMD 没有并发性,仅仅只是同时进行计算。 在 Intel 的 x86 微架构处理器中,SIMD 指令集有 MMX、SSE、SSE2、SSE3、SSSE3、SSE4.1、SSE4.2、AVX、AVX2、AVX512。 AVXAVX 是 SSE 架构的延伸,将 SSE 的 XMM 128bit 寄存器升级成了 YMM 256bit 寄存器,同时浮点运算命令扩展至 256 位,运算效率提升了一倍。另外,AVX 还添加了三操作数指令,以减少在编码时先复制再运算的动作。 AVX2 将大多数整数运算命令扩展至 256 位,同时支持 FMA(Fused Multiply-Accumulate,融合乘法累加)运算,可以在提高运算效率的同时减少运算时的精度损失。 AVX512 将 AVX 指令进一步扩展至 512 位。 AVX指令介绍参考该网站:Crunching Numbers with AVX and AVX2 - CodeProject 基于AVX的矩阵乘法 算法思想
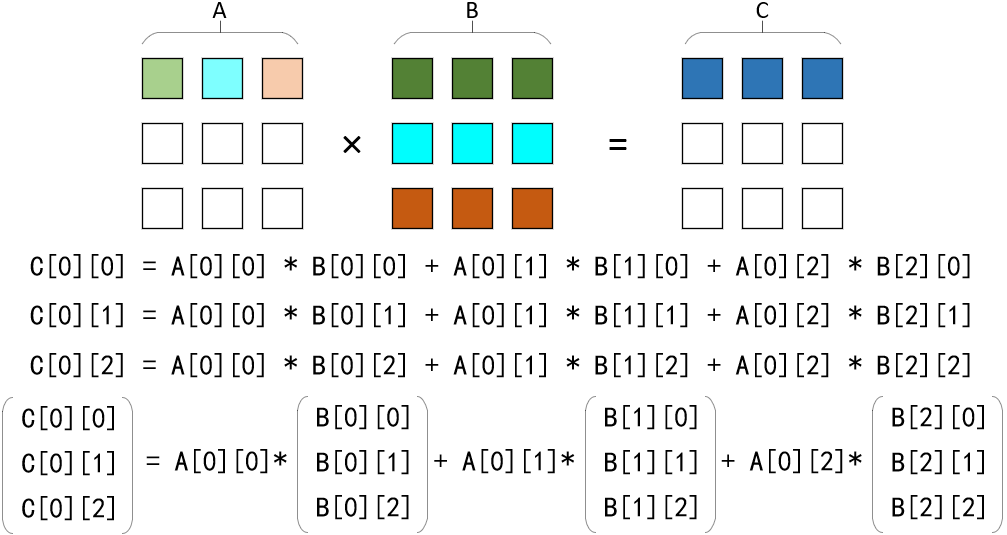
结合上图,首先需要将矩阵 C 初始化为 0 矩阵。为了充分利用 AVX 单指令多数据的计算优势,需要以向量为基本运算单元,将矩阵 A 第 i 行第 j 列的元素与矩阵 B 第 j 行的向量相乘,结果向量与矩阵 C 第 i 行的向量累加。当矩阵 A 第 i 行的所有元素均与矩阵 B 每一行的向量相乘并累加至矩阵 C 第 i 行的向量后,矩阵 C 第 i 行的计算结束。 假设矩阵的元素为 float 类型(32位)的浮点数,由于 AVX 采用 256 位寄存器存储向量,所以一个向量可以存储 8 个元素。当矩阵的列数不为 8 的整数倍时,即一行的元素个数不为 8 的整数倍时,最后一个向量的后几位需要设置为 0。若采用兼容未对齐数据的方法则需要解决内存冲突的问题。 代码在具体实现时,矩阵 A 第 i 行第 j 列的数据 A[i][j] 会被复制成长度为 8 的向量 vecA,矩阵 B 每一行的向量 vecB 则从指定内存地址读入。由于矩阵的列数可以不是 8 的整数倍(对于元素为float类型的矩阵),所以数据可以是未对齐的,因此采用 loadu 从内存装入矩阵数据。 对于向量的相乘和累加,因为两个 n 位数字相乘的结果最大可以占 2n 位,因此当两个 float 类型的浮点数 a 与 b 相乘时,其结果是最接近 a*b 的 float 数值 round(a*b)。在本算法中,两个浮点数相乘后还要累加到 C 矩阵中,相比于普通的相乘后累加 round(a*b)+c,FMA运算可以实现 round(a*b+c)。因此这种方式拥有更高的精确性。 这里我并没有将最后一个向量的后几位设置为 0,所以存在一个问题:假如此时矩阵 B 为 7*6,当 loadu 读入矩阵 B 第二行的数据时,第二行只有 6 个 float 类型的 32 位浮点数,不足以构成 256 位的向量,因此指令会继续读入第三行的前两个数,计算完成后,第三行的前两个数也被保存至矩阵 C。接着,指令读入第三行和第四行前两个数,计算完成后保存。不难发现,从第二行开始到最后一行,每行的前两个数都被计算了两次。并且对于第一次计算来说,后两个数的计算过程不符合算法的原理,是错误数据。解决方法很简单,在矩阵 C 各行开始计算之前,重新初始化该行的元素值为 0,以消除第一次错误计算的影响。 #include #include #include #include #define MATRIX_SIZE 8192#define NUM_THREAD 4float matA[MATRIX_SIZE][MATRIX_SIZE];float matB[MATRIX_SIZE][MATRIX_SIZE];float matC[MATRIX_SIZE][MATRIX_SIZE];int step = 0;void* multiplicationAVX(void* args) {__m256 vecA, vecB, vecC;int thread = step++;for (int i = thread * MATRIX_SIZE / NUM_THREAD;i < (thread + 1) * MATRIX_SIZE / NUM_THREAD; i++) {for (int j = 0; j < MATRIX_SIZE; j++) {matC[i][j] = 0.0f;}for (int j = 0; j < MATRIX_SIZE; j++) {vecA = _mm256_set1_ps(matA[i][j]);for (int k = 0; k < MATRIX_SIZE; k += 8) {vecB = _mm256_loadu_ps(&matB[j][k]);vecC = _mm256_loadu_ps(&matC[i][k]);vecC = _mm256_fmadd_ps(vecA, vecB, vecC);_mm256_storeu_ps(&matC[i][k], vecC);}}}return 0;}void* multiplicationNormal(void* args) {int thread = step++;for (int i = thread * MATRIX_SIZE / NUM_THREAD;i < (thread + 1) * MATRIX_SIZE / NUM_THREAD; i++) {for (int j = 0; j < MATRIX_SIZE; j++) {for (int k = 0; k < MATRIX_SIZE; k++) {matC[i][j] += matA[i][k] * matB[k][j];}}}return 0;}void createMatrix() {for (int i = 0; i < MATRIX_SIZE; i++) {for (int j = 0; j < MATRIX_SIZE; j++) {matA[i][j] = i + j * 2;matB[i][j] = i * 2 + j;matC[i][j] = 0.0f;}}}void printMatrix() {if (MATRIX_SIZE printf("\n");for (int j = 0; j < MATRIX_SIZE; j++) {printf("%f ", matA[i][j]);}}printf("\n\n");printf("Matriz B");for (int i = 0; i < MATRIX_SIZE; i++) {printf("\n");for (int j = 0; j < MATRIX_SIZE; j++) {printf("%f ", matB[i][j]);}}printf("\n\n");printf("Multiplying matrix A with B");for (int i = 0; i < MATRIX_SIZE; i++) {printf("\n");for (int j = 0; j < MATRIX_SIZE; j++) {printf("%f ", matC[i][j]);}}}}int main() {pthread_t threads[NUM_THREAD];clock_t start, end;createMatrix();start = clock();for (int i = 0; i < NUM_THREAD; i++) {// pthread_create(&threads[i], NULL, multiplicationNormal, NULL);pthread_create(&threads[i], NULL, multiplicationAVX, NULL);}for (int i = 0; i < NUM_THREAD; i++) {pthread_join(threads[i], NULL);}end = clock();printMatrix();printf("\n\n使用的线程数 -> %d\n", NUM_THREAD);printf("\n矩阵大小 -> %d\n", MATRIX_SIZE);printf("\n程序运行时间(毫秒) -> %f\n\n", (float)(end - start) * 1000 / CLOCKS_PER_SEC);}
版权声明:本文由 iiYK 原创,允许转载,转载时请注明文章出处 AVX指令集加速矩阵乘法 – iiYK
|
【本文地址】