| 如何使用python爬虫selenium爬取知网信息以及对数据进行本地化储存和mysql数据库储存 | 您所在的位置:网站首页 › 知网下载有时间限制吗 › 如何使用python爬虫selenium爬取知网信息以及对数据进行本地化储存和mysql数据库储存 |
如何使用python爬虫selenium爬取知网信息以及对数据进行本地化储存和mysql数据库储存
|
一、selenium
1.selenium介绍
selenium的官网(selenium中文网 | selenium安装、selenium使用、selenium中文、selenium下载)给出了详细定义: Selenium 是web自动化测试工具集,包括IDE、Grid、RC(selenium 1.0)、WebDriver(selenium 2.0)等。 Selenium IDE 是firefox浏览器的一个插件。提供简单的脚本录制、编辑与回放功能。 Selenium Grid 是用来对测试脚步做分布式处理。现在已经集成到selenium server 中了。 RC和WebDriver 更多应该把它看成一套规范,在这套规范里定义客户端脚步与浏览器交互的协议。以及元素定位与操作的接口。 而在python爬虫过程中,为了规避一些网站的反爬机制,我们会选择更智能更灵活的selenium和palywright等工具,这些原本应用于web自动化测试的工具能够很好模拟人工操作,让一些被javascript隐藏的网页信息也能被我们获取。 2.selenium安装windows系统需要用win+R打开cmd窗口,输入 pip install selenium按下回车键等待安装完成即可
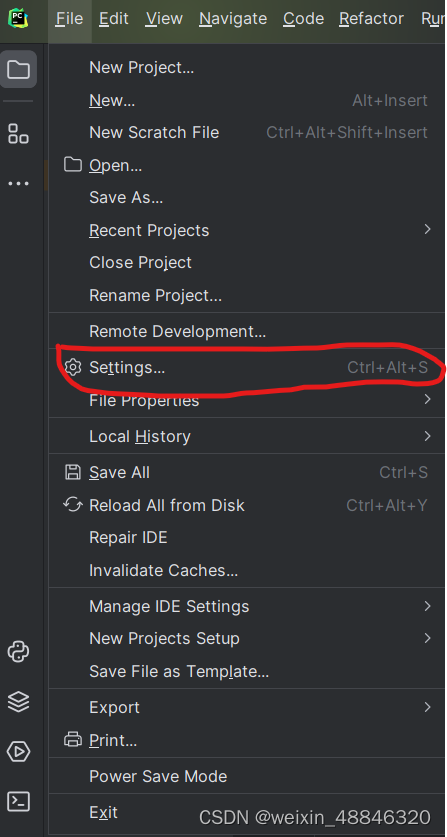
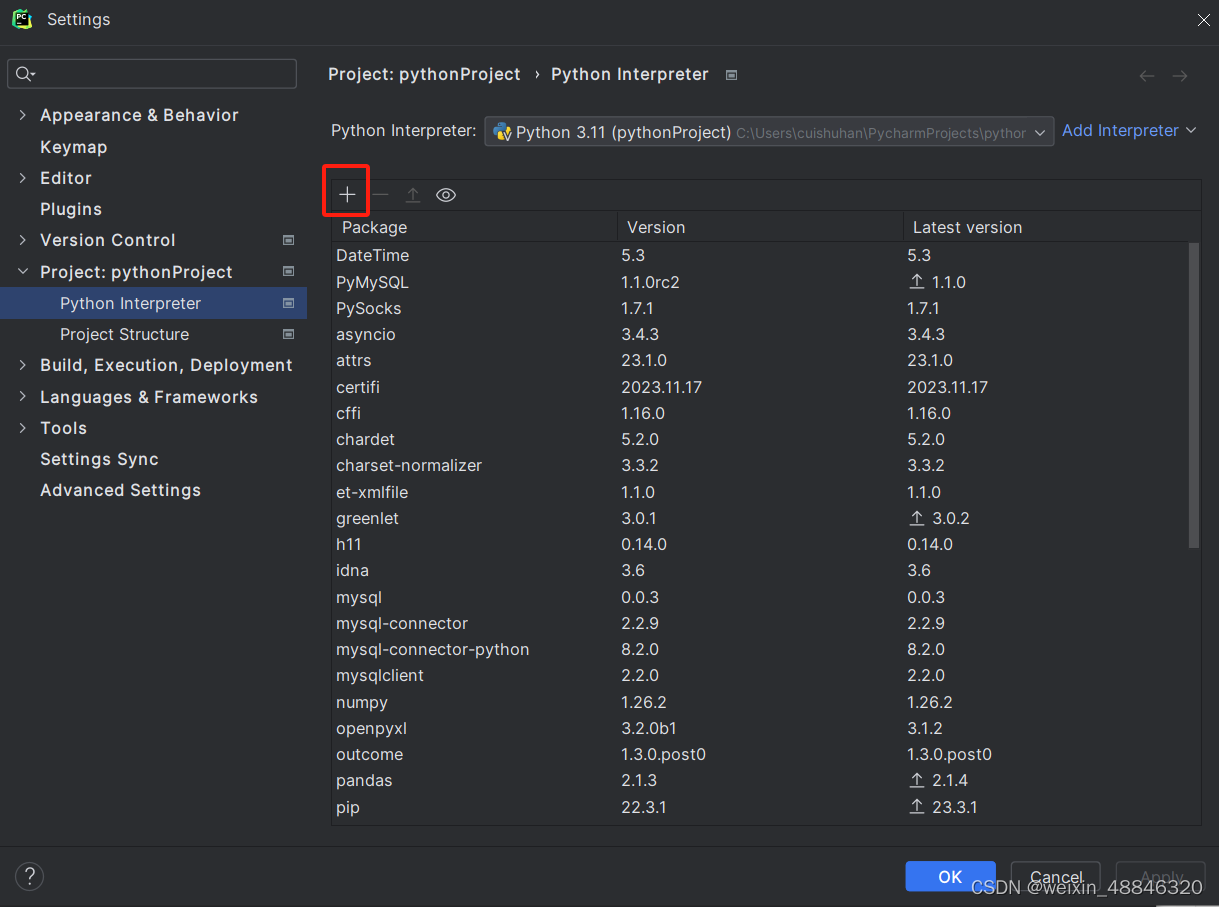
我们安装selenium之后还需要在pycharm里面进行添加
点击file里面的settings 点击+号
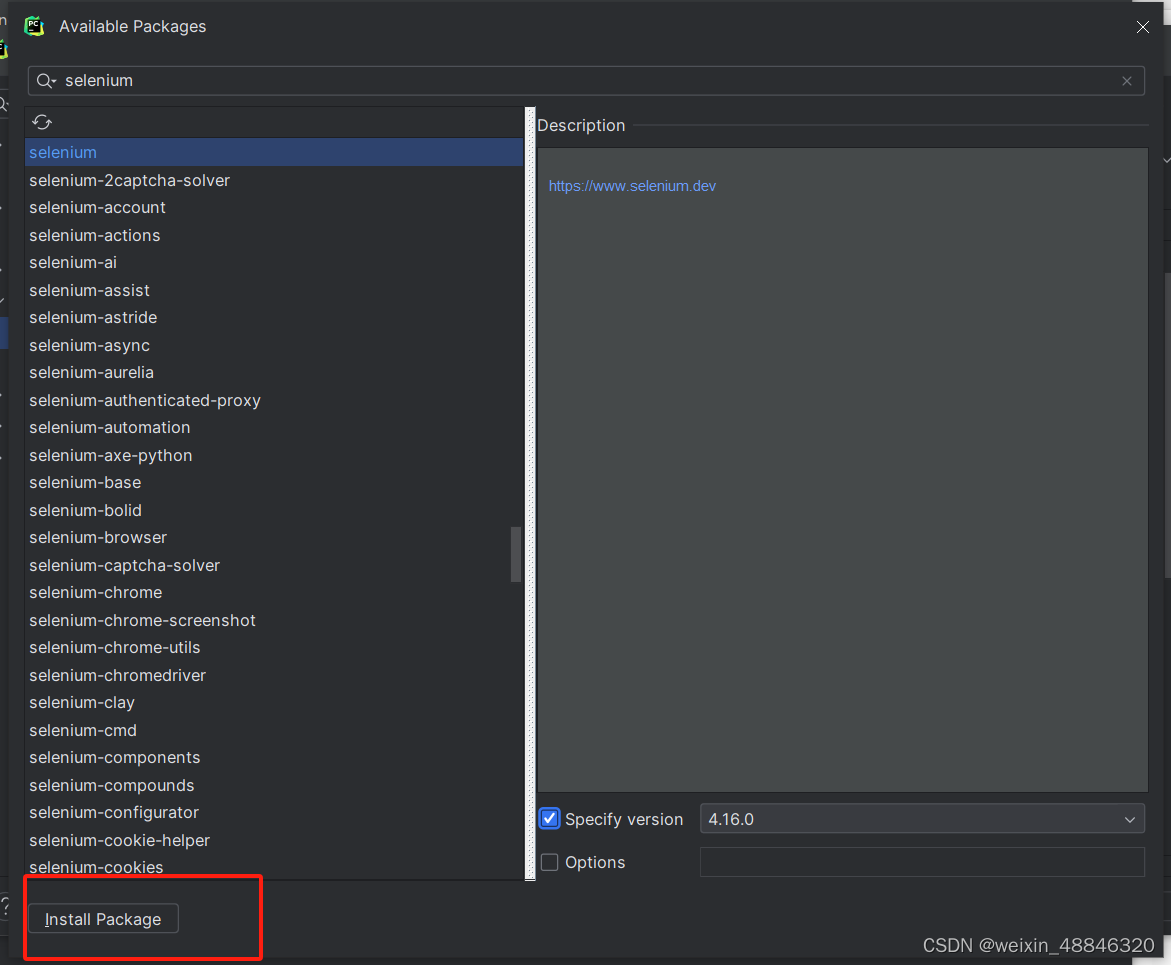
搜索selenium勾选版本然后点击install package等待提示安装完成即可 二、爬虫书写 1.爬虫运行前提及注意事项此爬虫默认ip登陆可以访问知网,适合高校学子,个人账户需添加登录账号和密码,但鉴于知网的反爬机制,不建议个人爬取,容易被封号。 另外,运行selenium需要安装webdrive才能打开浏览器,不同的浏览器webdrive不同,我这里用的是IE浏览器,NuGet Gallery | Selenium.WebDriver.IEDriver 4.14.0,具体版本和安装方式可以自行搜索。 2.知网页面及爬虫逻辑知网作为大学文献阅读的必备网站之一,可以给我们提供大量文献帮助,但人手检索文献一篇一篇地复制下载没办法宏观地查看一个领域的学科发展脉络等,所以我们可能需要一些爬虫工具来进行辅助。 我们先看知网的初始页面
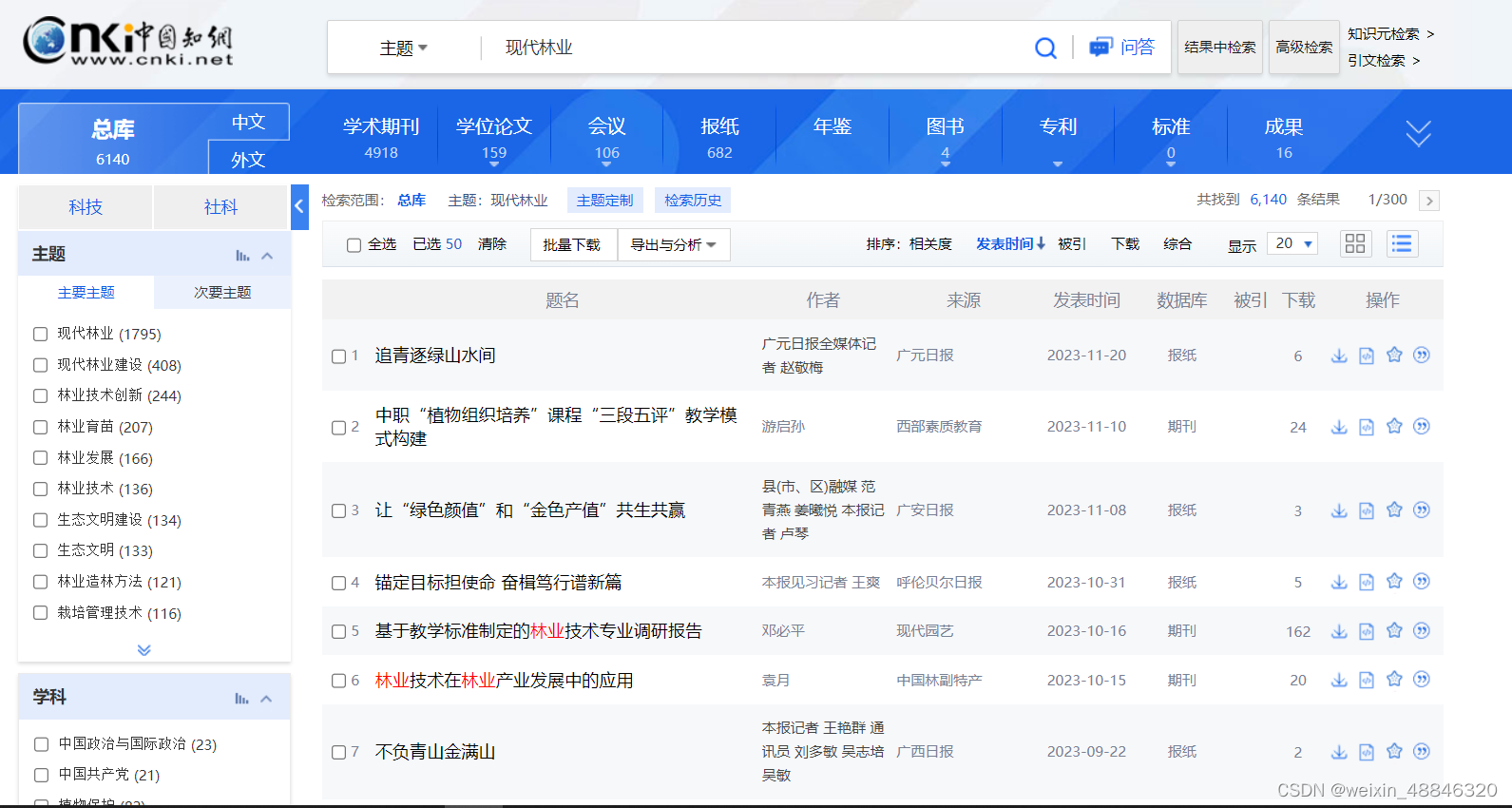
我们需要在搜索栏里面输入想要检索的内容,然后点击搜索键,默认的是初级搜索+主题检索,当然你可以改到高级搜索或其他检索方式。
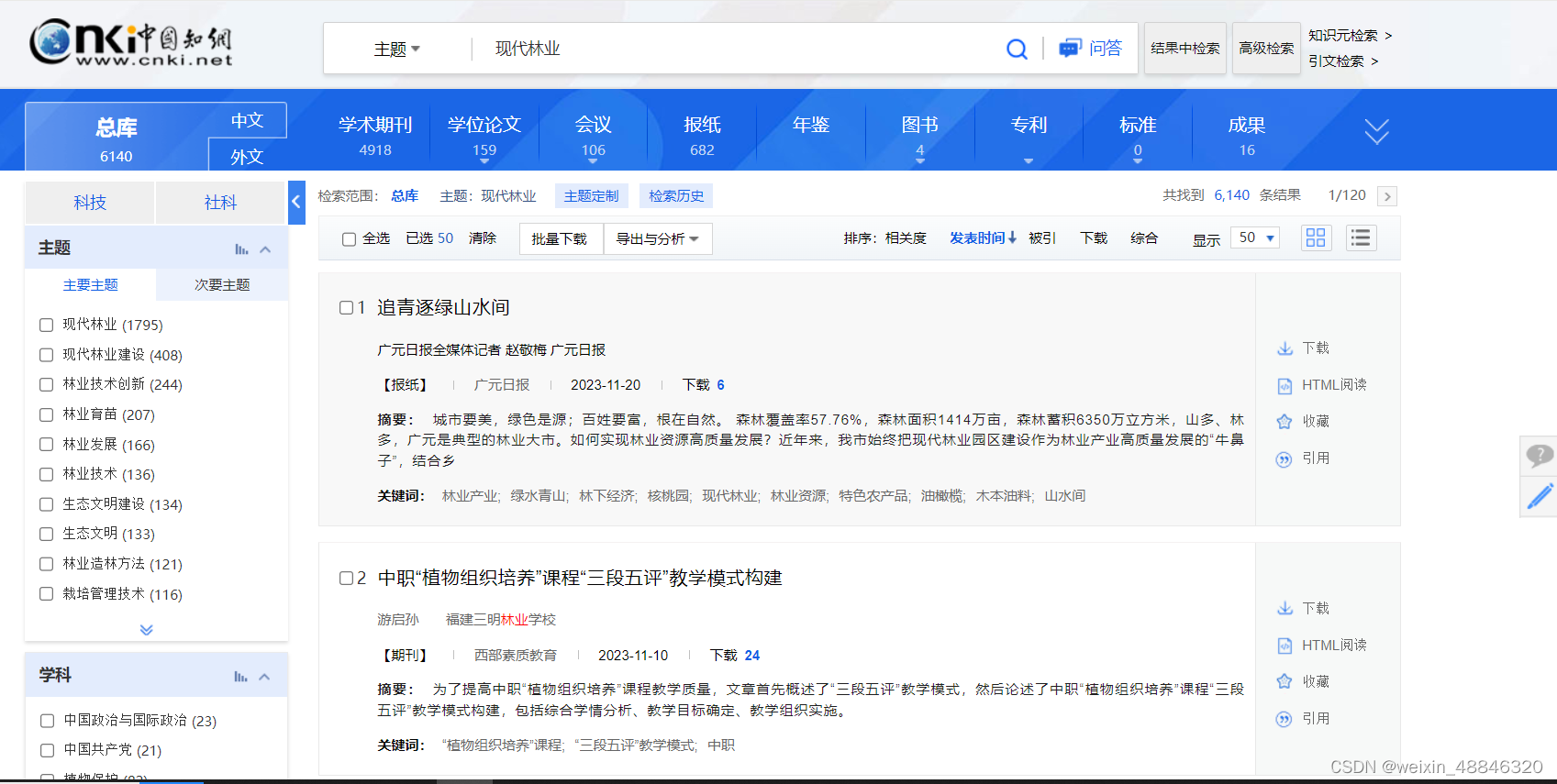
我这里输入的内容是“现代林业”,检索之后默认界面里面按中文、发表时间倒序、“题名作者来源发表时间数据库被引下载”、每页20条显示,这样的检索结果爬不全我想要的内容,我需要对其进行修改,我要点击详情,并让显示改到最大的每页50篇。
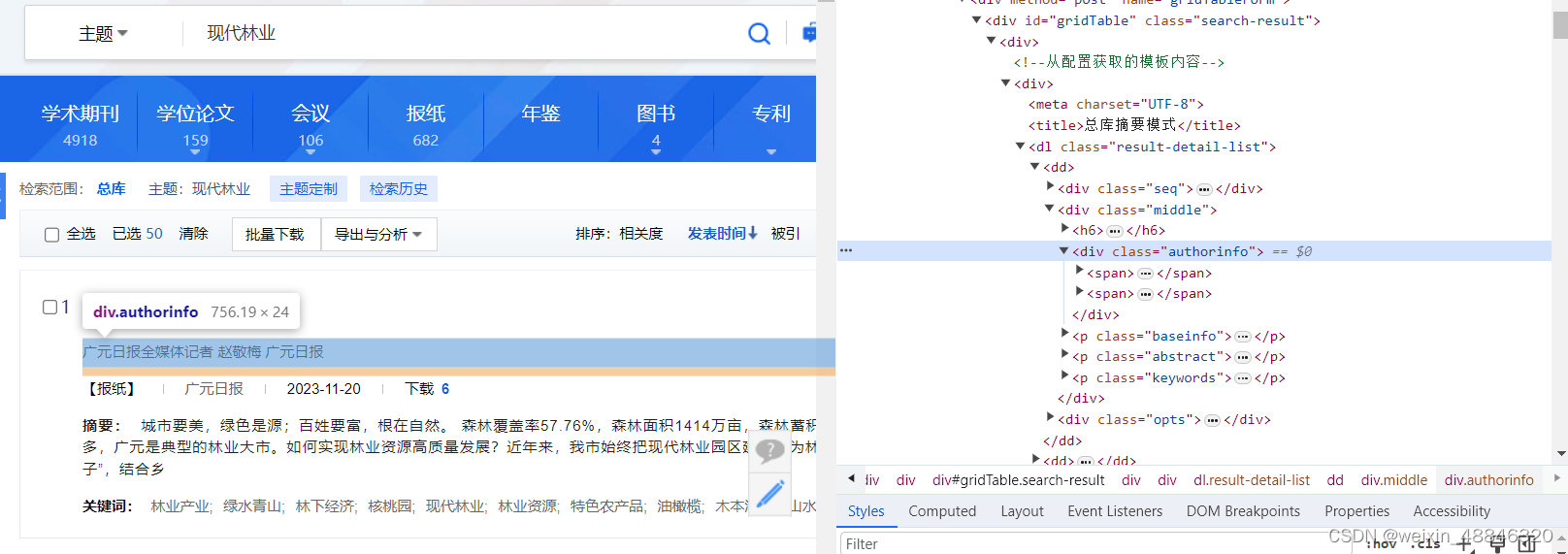
此时我想要的关键词和摘要都出现了但这时我发现这里单位和作者位于一个div里面,仅用span包裹,且有的没有作者或者单位或者多个作者或者单位,这个页面的信息储存十分混乱,不太利于我爬取数据后进行处理。
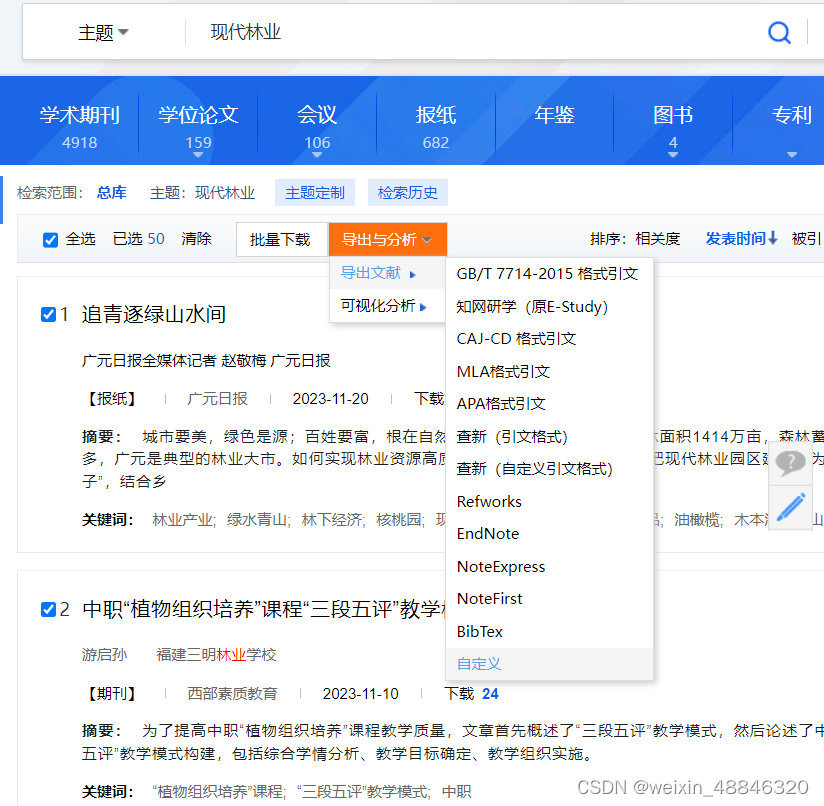
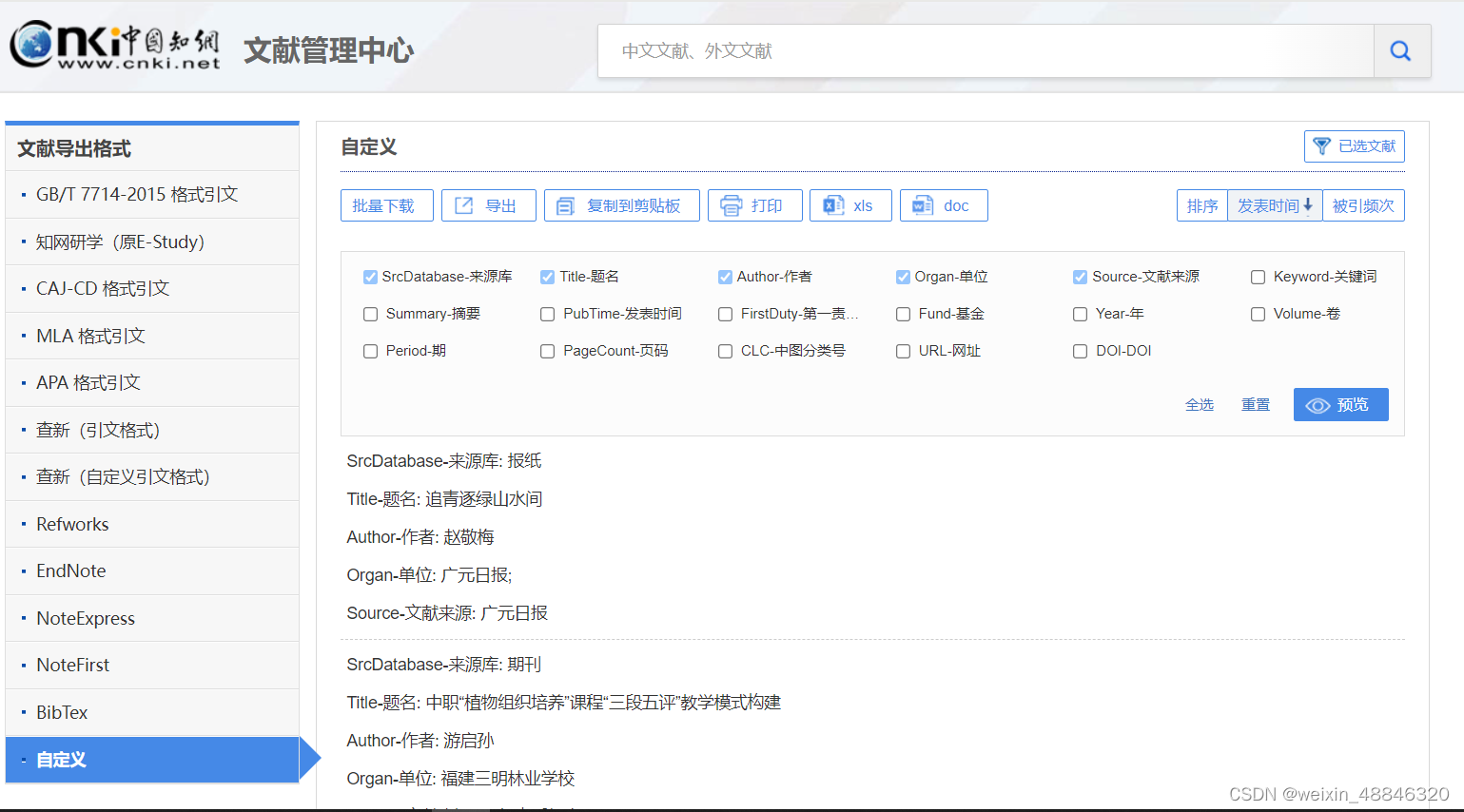
这时我又发现有一个全选-导出与分析-自定义的选项
这个页面里面数据的储存就十分有规律且对作者和单位进行了分割,我还可以自定义想导出的内容
于是就这么愉快的决定了! 3.爬虫函数首先需要导入,这些是包含数据储存需要的内容,储存的方式不同可能用不到一些内容,如果你要本地建表储存,就不需要pymysql,如果你mysql储存就不需要csv import time from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from selenium.webdriver.common.action_chains import ActionChains import csv import random import pymysql设置驱动环境,设置driver,定义爬取网站,我们可以适当设置不加载图片,减少加载时长。 # get直接返回,不再等待界面加载完成 desired_capabilities = DesiredCapabilities.EDGE desired_capabilities["pageLoadStrategy"] = "none" # 设置 Edge 驱动器的环境 options = webdriver.EdgeOptions() #设置 Edge 不加载图片,提高速度 options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 创建一个 Edge 驱动器 driver = webdriver.Edge(options=options) #选择网址 driver.get("https://www.cnki.net")模拟在输入框输入搜索内容并点击 #定义并输入主题,主题词可以换成别的 theme='现代林业' WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, '''//*[@id="txt_SearchText"]'''))).send_keys(theme) # 点击搜索 WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div/div[1]/input[2]"))).click() time.sleep(3)默认是主题检索,也可以通过下面的代码换到其他方式检索,比如全文检索 # 点击主题按钮 WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div/div[1]/div"))).click() time.sleep(1) # 选择内容检索,这里面我以全文检索举例,li[5]代表的是点击“全文” WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div/div[1]/div/div[2]/ul/li[5]"))).click() time.sleep(3) # 点击搜索 WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div/div[1]/input[2]"))).click() time.sleep(5)对应的 li[n]列表如下
调整一页里面50页,点击详情,看一眼一共多少论文多少页 #控制显示数量为50 WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "//*[@id='perPageDiv']/div[@class='sort-default']"))).click() WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "//*[@id='perPageDiv']/ul/li[@data-val='50']"))).click() time.sleep(5) # 点击查看详情 WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[2]/ul[2]/li[1]"))).click() time.sleep(3) # 获取总文献数和页数 res_unm = WebDriverWait(driver, 200).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[1]/em"))).text # 去除千分位里的逗号 res_unm = int(res_unm.replace(",", '')) page_unm = int(res_unm / 20) + 1 papers_need=res_unm print(papers_need) print(page_unm)爬取的主函数如下,具体看注释解释吧 def crawl(driver, papers_need, theme): # 赋值序号, 控制爬取的文章数量 count = 1 expect_count=0 # 当爬取数量小于需求时,循环网页页码 while count 1: driver.close() driver.switch_to.window(n2[0]) #回到页面并清除全选 #// *[ @ id = "briefBox"] / div[1] / div / div[2] / div[1] / a WebDriverWait(driver, 300).until(EC.presence_of_element_located( (By.XPATH, "//*[@id='briefBox']/div[1]/div/div[2]/div[1]/a"))).click() WebDriverWait(driver, 300).until(EC.presence_of_element_located((By.XPATH,"/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a[@class='pagesnums']"))).click() count += 1 if count == papers_need: break到了这一步基本就完成了,别忘了最关键的一步,运行函数 crawl(driver,papers_need,theme) 4.报错补救方法(待优化)我运行的时候前2000条基本不会报错,不过因为网络问题和知网有时候会断连等一些问题,2000条左右会爬取失败断连,还没想到更好的补救方法,不过有个好处是我的爬虫方法让50条文章的信息都在一个页面,且一整页信息导出后爬取,爬不出来报错的断点都是50的倍数,页数也是整数。我目前的方法是写了另一个文件,根据报错前最后打印的那条信息记录一下断点是哪里,用第二个爬虫文件翻页到那一页然后从断点出继续爬取。 import time from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from selenium.webdriver.common.action_chains import ActionChains import random # get直接返回,不再等待界面加载完成 desired_capabilities = DesiredCapabilities.EDGE desired_capabilities["pageLoadStrategy"] = "none" # 设置 Edge 驱动器的环境 options = webdriver.EdgeOptions() #设置 Edge 不加载图片,提高速度 options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 创建一个 Edge 驱动器 driver = webdriver.Edge(options=options) #选择网址 driver.get("https://www.cnki.net") #定义并输入主题 theme='现代林业' WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, '''//*[@id="txt_SearchText"]'''))).send_keys(theme) # 点击搜索 WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div/div[1]/input[2]"))).click() time.sleep(5) #/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[2]/div[2]/div/div/div[@class='sort-default'] #//*[@id="perPageDiv"]/div #//*[@id="perPageDiv"]/ul/li[3] # 点击查看详情 WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[2]/ul[2]/li[1]"))).click() time.sleep(5) WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "//*[@id='perPageDiv']/div[@class='sort-default']"))).click() WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "//*[@id='perPageDiv']/ul/li[@data-val='50']"))).click() time.sleep(5) # 获取总文献数和页数 res_unm = WebDriverWait(driver, 300).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[1]/em"))).text # 去除千分位里的逗号 res_unm = int(res_unm.replace(",", '')) page_unm = int(res_unm / 50) + 1 papers_need=res_unm print(papers_need) print(page_unm) def crawl(driver, papers_need, theme): # 赋值序号, 控制爬取的文章数量 #此处count是断点值+1 count = 5951 expect_count=0 # 当爬取数量小于需求时,循环网页页码 while count 1: driver.close() driver.switch_to.window(n2[0]) #回到页面并清除全选 #// *[ @ id = "briefBox"] / div[1] / div / div[2] / div[1] / a WebDriverWait(driver, 300).until(EC.presence_of_element_located( (By.XPATH, "//*[@id='briefBox']/div[1]/div/div[2]/div[1]/a"))).click() WebDriverWait(driver, 300).until(EC.presence_of_element_located((By.XPATH,"/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a[@class='pagesnums']"))).click() count += 1 if count == papers_need: break #这里的逻辑是知网文献第一页是1-9,断点一般在9页之后,所以我直接点第九页跳到第九页 #/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/div[9] time.sleep(5) wait = WebDriverWait(driver, 300) click_element = wait.until(EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/div[9]"))) click_element.click() time.sleep(5) n=1 #这里的逻辑是知网文献点到第九页之后,如果当前页面为t,显示可以点击跳转的最大页面数是t+4,这里面n是点击数,相当于点到9+4*n页 while n |


【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |