| 爬虫遇到空白页 | 您所在的位置:网站首页 › 百度百科爬虫空白 › 爬虫遇到空白页 |
爬虫遇到空白页
|
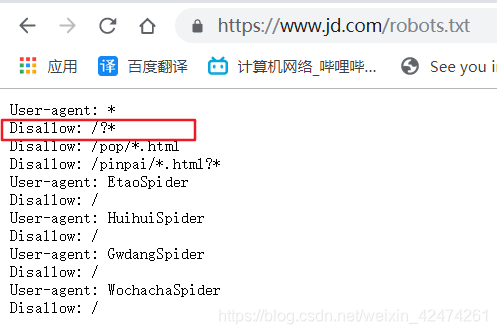
大约在两个月前,京东动态加载的评论数据还是可以正常访问的,可是有人在我关于京东评论爬虫教程中评论之后我才发现,评论数据页面没法正常查看了。 其实在京东的robots协议中就包含了禁止访问含"?"的url,如下图所示 首先,在确定url没错的情况下,首先想到的肯定是有反爬虫机制。 常见的反爬:要求有登陆状态(例如淘宝)、访问频次检测等 常用的策略:构造cookie、更换浏览器、使用代理ip、selenium模拟点击等 通过抓包分析后发现,这种反爬叫做网页referer,它能够记录你访问新网页前网站的网址,Chrome刷新网页,按F12在network中查看Referer上一个网页地址 这里以python代码为例,讨论应对Referer反爬虫 import requests url = "https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv16247&productId=100000177760&score=0&sortType=5&page=6&pageSize=10&isShadowSku=0&rid=0&fold=1" headers = { 'Accept': '*/*', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36', 'Referer':"https://item.jd.com/100000177760.html#comment"} r = requests.get(url,headers=headers) print(r.text)结果如下 |
 但之前一直没有什么反爬机制,导致我们这些小白们都拿京东来练手,这其实也影响了其网站的正常运作。因此建议在使用爬虫时注意访问不要太频繁。
但之前一直没有什么反爬机制,导致我们这些小白们都拿京东来练手,这其实也影响了其网站的正常运作。因此建议在使用爬虫时注意访问不要太频繁。 用这种方式可以查看到直接用动态生成的url访问京东评论页的referer并不是合理的,因此被识别出来,返回了空白页(当然也有可能是其他反爬虫)。
用这种方式可以查看到直接用动态生成的url访问京东评论页的referer并不是合理的,因此被识别出来,返回了空白页(当然也有可能是其他反爬虫)。 通过这样的方式,就可以绕开Referer反爬机制,其他的反反爬虫方法也大多数都是通过构造请求头headers来实现,快去试一试吧!
通过这样的方式,就可以绕开Referer反爬机制,其他的反反爬虫方法也大多数都是通过构造请求头headers来实现,快去试一试吧!【本文地址】
公司简介
联系我们