| 大数据实战项目 | 您所在的位置:网站首页 › 用户行为模型分析案例 › 大数据实战项目 |
大数据实战项目
|
一、实验目的
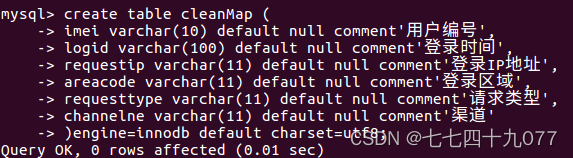
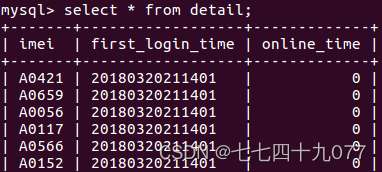
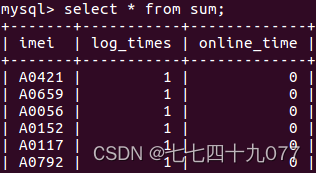
1. 掌握关系数据库的原理、MySQL数据库的安装和使用方法; 2. 掌握IntelliJ IDEA编写Scala程序的方法; 3. 掌握编写Spark程序的方法; 4. 掌握使用Spring框架进行网页开发的方法; 5. 掌握通过网页进行数据可视化的方法。 二、实验内容相关数据集、源码链接:高校大数据实训课程系列案例之电信用户行为分析_厦门大学数据库实验室 1. 把电信用户行为数据集加载到HDFS中; 2. 使用Scala或Python语言编写Spark程序对HDFS中的数据进行用户行为分析,并把结果写入到MySQL数据库; 3. 使用Spring MVC框架开发网页应用,对MySQL数据库中的数据进行可视化分析; 4. 在网页中以图表形式对分析结果进行可视化呈现。 三、实验要求1. 实验完成度。 按要求独立完成实验准备、程序调试、实验报告撰写。 2. 实验内容。代码功能完善、可正常运行,测试数据正确,分析正确,结论正确。 3. 实验报告。内容齐全,符合要求,包括代码的规范性、注释的完整性、算法和模型的优化程度等。 4. 总结。对实验过程遇到的问题能初步独立分析,解决后能总结问题原因及解决方法,有心得体会。 四、实验过程、详细步骤 3.1本地数据集上传到HDFS 3.1.1 数据集下载本案例采用一个电信行业用户数据demo.txt。 3.1.2 把数据集上传到HDFS# 进入Hadoop安装目录 ~$ cd /usr/local/hadoop # 启动Hadoop的HDFS组件 /usr/local/hadoop$ ./sbin/start-dfs.sh # 查看HDFS的相关进程是否正常启动 /usr/local/hadoop$ jps 4034 NameNode 9958 NailgunRunner 9110 RemoteMavenServer 11711 Jps # 查看HDFS文件系统目录下的内容 /usr/local/hadoop$ ./bin/hdfs dfs -ls / # 在HDFS的根目录下创建input_spark目录 /usr/local/hadoop$ ./bin/hdfs dfs -mkdir /input_spark # 查看目录是否要创建成功 /usr/local/hadoop$ ./bin/hdfs dfs -ls / drwxr-xr-x - hadoop supergroup 0 2023-06-02 12:46 /input_spark # 把本地数据集上传到HDFS中 /usr/local/hadoop$ ./bin/hdfs dfs -put ~/Downloads/demo.txt /input_spark # 查看该目录的信息 /usr/local/hadoop$ ./bin/hdfs dfs -ls /input_spark # 查看HDFS文件中的数据 /usr/local/hadoop$ ./bin/hdfs dfs -cat /input_spark/demo.txt 3.2 在MySQL中创建数据库 3.2.1启动进入MySQL Shell环境# 启动MySQL服务 /usr/local/hadoop$ service mysql start # 进入MySQL /usr/local/hadoop$ sudo mysql -u root -p 3.2.2创建一个数据库create database spark_web; # 进入数据库spark_web use spark_web 3.2.3创建一个数据库汇总表 create table sum ( imei varchar(10) default null comment'用户编号', log_times int(2) default null comment'登陆次数', online_time int(10) default null comment'在线时长(秒)' ) engine=innodb default charset=utf8;
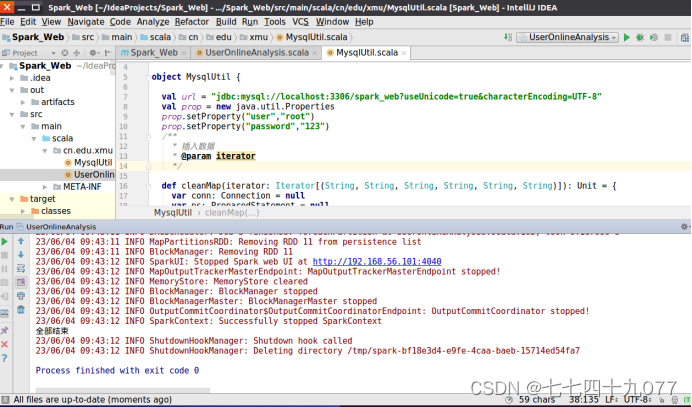
/usr/local/hadoop$ cd ~/下载 ~/下载$ unzip mysql-connector-java-5.1.40.zip ~/下载$ cp ./mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/spark/jars 3.3 开发Spark程序分析用户行为 3.3.1 新建项目Spark_Web项目Spark_Web的目录结构如下。
生成jar包的途径是“~/IdeaProjects/Spark_Web/out/artifacts/Spark_Web_jar/Spark_Web.jar”
# 启动MySQL $ service mysql start $ mysql -u root -p
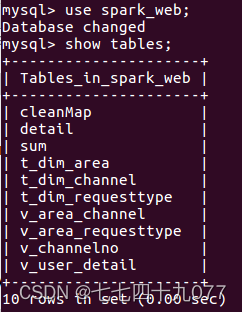
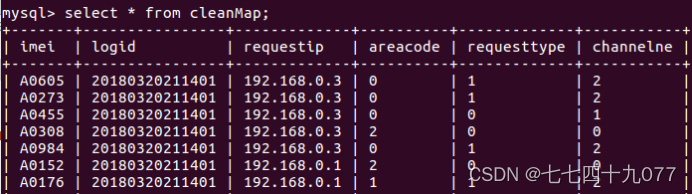
执行结束后,在MySQL Shell交互式执行环境中,执行如下SQL命令语句。 show database; use spark_web; show tables; select * from detail; select * from sum; select * from cleanMap;
项目Spark_Web的目录结构如下。
进人Tomcat安装目录(即“/usr/local/tomcat"), 再进入conf子目录,打开“server.xml" 文件,修改配置文件。
然后,保存“server.xml”文件,在Linux终端中继续执行如下Shell命令,重新启动Tomcat 服务器: $ cd /usr/local/tomcat $./bin/shutdown.sh $./bin/startup.sh 前面已经生成的SpringMVC.war 文件的路径是 “~/ldeaProjects/SpringMVC/out/artifacts/SpringMVcSpringMVC.war”。把“SpringMVC.war”文件复制到 Tomcat 的安装目录的“webapps”目录下(即“usr/local/tomcat/webapps”目录)。如图6-47所示,当把“SpringMVC.war”文件复制到webapps目录下的时候,Tomcat 会自动在该目录下生成文件夹 SpringMVC。实际上,如果后面要修改网页程序,当把 webapps目录下的“SpringMVC.war”文件删除时,Tomcat也会自动删除SpringMVC目录。
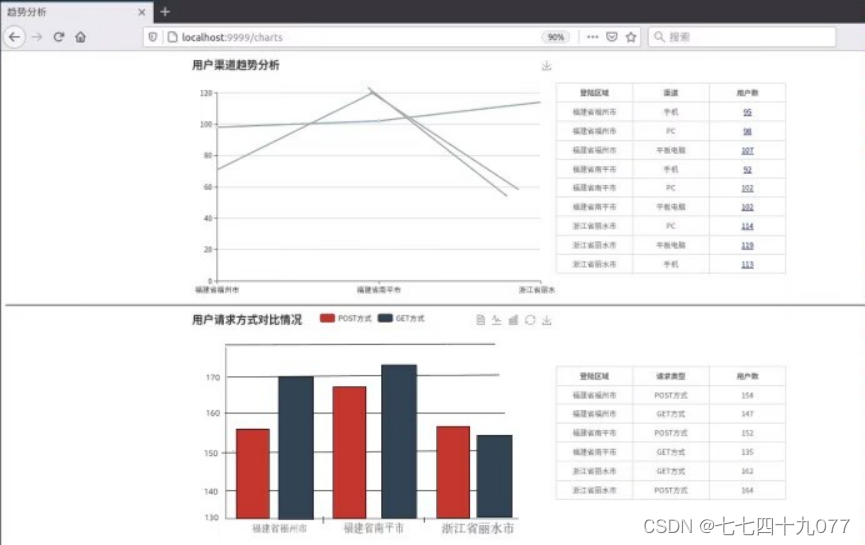
打开Linux系统的浏览器,在浏览器输人地址“http:/localhost:9999/charts”。就可以看到最终的数据图表了。
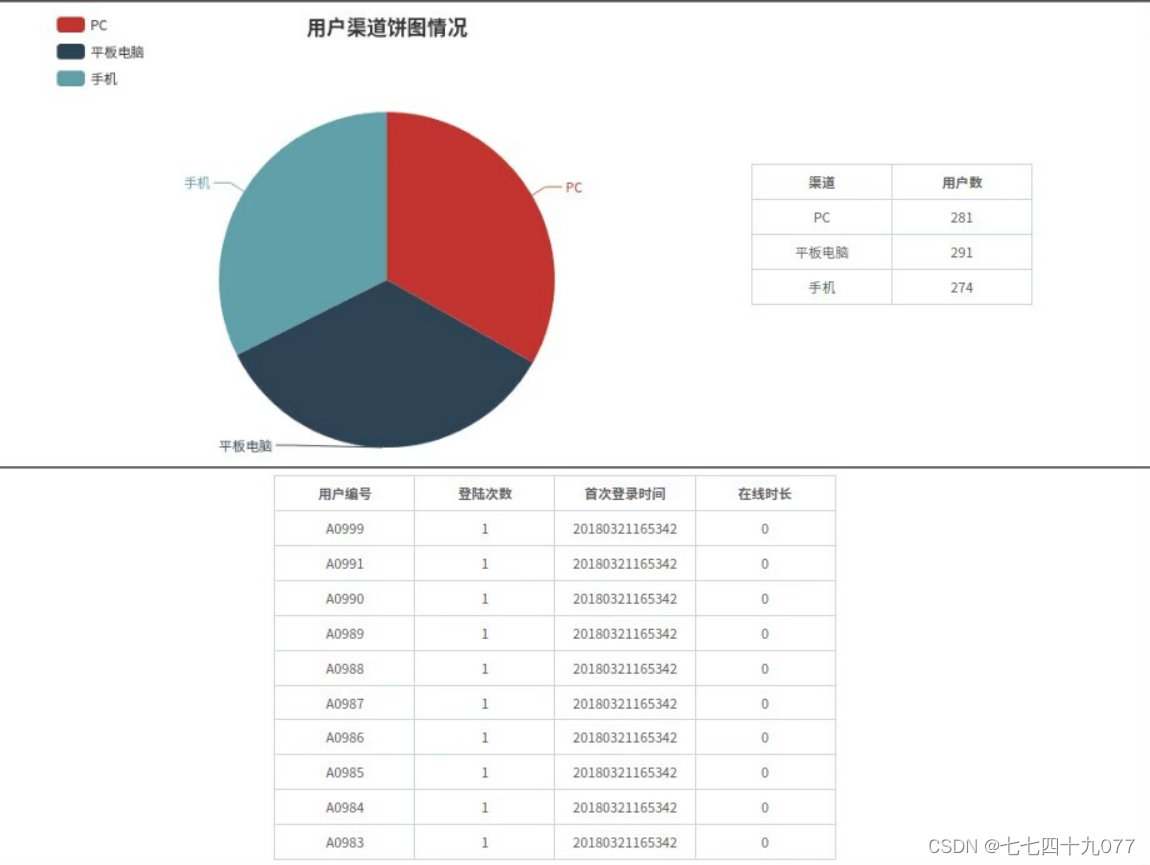
在“用户渠道趋势分析”可视化图表的右侧,可以单击“用户数”这一列中的数字,会出现一个新的页面显示具体用户信息。
本章首先简要介绍了本案例的数据分析整体过程;然后描述了数据集的特性,并讨论了把本地数据集加载到 HDFS 中的方法;接下来,通过SQL 语句,在MySQL 数据库中创建了相应的数据库、表和视图,用于存储Spark程序的数据分析结果;再然后,详细介绍了使用Scala语言编写Spark程序分析用户行为的细节过程;最后,使用Spring、 Spring MVC、MyBatis框架和可视化图表库ECharts编写网页应用程序,在网页中以图表形式对分析结果进行可视化呈现。 四、实验结果(运行结果截图)实验结果如上述!!! 五、总结与思考(列出遇到的问题和解决办法,列出没有解决的问题,可以是个人相关知识点总结,要求300字以上) 总结通过本次实验掌握的相关知识点与心得体会,及实验过程中得到的各方面收获(知识面拓展、实践动手能力、数据认识、交流互动……)。 Spring框架中的单例Bean是线程安全的么?Spring中的Bean默认是单例模式的,框架并没有对bean进行多线程的封装处理。 如果Bean是有状态的 那就需要开发人员自己来进行线程安全的保证,最简单的办法就是改变bean的作用域 把 "singleton"改为’‘protopyte’ 这样每次请求Bean就相当于是 new Bean() 这样就可以保证线程的安全了。 · 有状态就是有数据存储功能 · 无状态就是不会保存数据 controller、service和dao层本身并不是线程安全的,只是如果只是调用里面的方法,而且多线程调用一个实例的方法,会在内存中复制变量,这是自己的线程的工作内存,是安全的。 Dao会操作数据库Connection,Connection是带有状态的,比如说数据库事务,Spring的事务管理器使用Threadlocal为不同线程维护了一套独立的connection副本,保证线程之间不会互相影响(Spring是如何保证事务获取同一个Connection的?) 不要在bean中声明任何有状态的实例变量或类变量,如果必须如此,那么就使用ThreadLocal把变量变为线程私有的,如果bean的实例变量或类变量需要在多个线程之间共享,那么就只能使用synchronized、lock、CAS等这些实现线程同步的方法了。 Spring容器初始化流程?
(1)将xml或者注解等配置信息读取到内存中 (2)在内存中这些配置文件会当作Resource对象 (3)之后会将Resource对象解析成BeanDefination实例 (4)最后将BeanDefination注册到容器中 DefaultListableBeanFactory :存储容器中所有已经注册的BeanDefination的载体 Spring 中的 bean 生命周期? Spring中Bean的生命周期主要在创建和销毁两个时期。
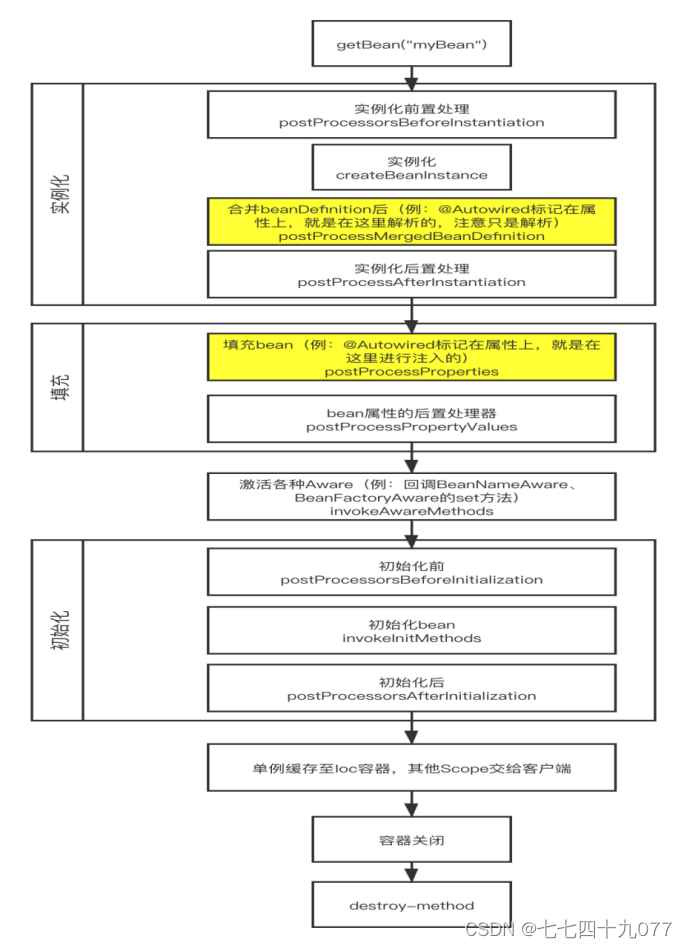
创建过程: (1)实例化bean对象,以及设置bean属性 (2)如果通过Aware接口声明了依赖关系,则会注入Bean对容器基础设施层面的依赖,Aware接口是为了感知到自身的一些属性。 (3)紧接着会调用BeanPostProcess的前置初始化方法postProcessBeforeInitialization,主要作用是在Spring完成实例化之后,初始化之前,对Spring容器实例化的Bean添加自定义的处理逻辑。有点类似于AOP。 (4) 如果实现了BeanFactoryPostProcessor接口的afterPropertiesSet方法,做一些属性被设定后的自定义的事情。 (5) 调用Bean自身定义的init方法,去做一些初始化相关的工作。 (6) 调用BeanPostProcess的后置初始化方法,postProcessAfterInitialization去做一些bean初始化之后的自定义工作。 (7) 完成以上创建之后就可以在应用里使用这个Bean了。 **销毁过程:**当Bean不再用到,便要销毁 (1)若实现了DisposableBean接口,则会调用destroy方法; (2)若配置了destry-method属性,则会调用其配置的销毁方法; 大致分为五个阶段: ·创建前准备 实例化 依赖注入 容器缓存 实例销毁 注意区分: 实例化:是对象创建的过程。比如使用构造方法new对象,为对象在内存中分配空间。 初始化:是为对象中的属性赋值的过程。 |









【本文地址】