| 教育平台的线上课程用户行为数据分析报告 | 您所在的位置:网站首页 › 用户行为模型分析报告 › 教育平台的线上课程用户行为数据分析报告 |
教育平台的线上课程用户行为数据分析报告
|
一、项目背景
近年来,随着各项高新技术的发展,在线上进行学习资源的共享有着欣欣向荣的发展趋势。尤其是在前几年新冠肺炎疫情的冲击下,学生返校进行线下上课愈加困难。在这样的种种契机下,琳琅满目的线上教育平台纷纷出现在世面上。随着教育平台的增加,通过数据分析挖掘消费者的潜在需求、消费偏好成为平台商业过程中的重要环节。 如何利用教育平台的用户信息,掌握用户课程偏好成为了线上教育的热点话题。因此,利用数据分析技术对教育平台的线上信息和用户学习信息进行研究具有重大意义。 本项目目的如下: 探寻用户行为规律,寻找高价值用户。分析商品,寻找高贡献商品。分析产品途径。 二、使用“人货场”拆解方式建立指标体系建立指标体系如下: 1.【人】基于RFM模型分类用户群,对不同人群给出不同运营策略。 2.【货】分类别找出最受欢迎的商品以及最大交易额的商品。 3.【场】从空间以及时间角度统计用户人数。 四、数据预处理 1.缺失值处理缺失情况说明: 我们将缺失数据分成三类,分别为空值与0与一些无意义的符号。对于不同的类别,我们将采取不一样的措施。 1、针对数值为 0 的情况,需要回归到原始数据中去判断该数据为 0 时是否具有实际意义。如果没有就将其作为缺失值做删除处理 2、针对数据为空值的情况,如果该特征数据缺失情况低于 10%,则结合该 特征的重要性进行综合判断。如果字段重要性较低,则考虑直接删除,如果字段重要性较高,则进行插值法或者采用数据均值进行填补 3、针对数据为特殊符号的情况,需要结合原始数据判断该数据为缺失值还是异常值。如果是缺失值则如 1 操作进行处理。如果为异常值,则进行异常值处理,具体异常值处理过程将在下文中进行阐述。 login表: select * from login where user_id is null or user_id = ' ' or login_time is null or login_time = ' ' or login_ place is null or login place = ' ';结果: 我们发现price有0的数据,但结合实际意义我们可以知道,这是代表免费课程的意思。 另外我们还发现数据有空值: select * from study_information where user_id is null or user_id = ' ' or course_id is null or course_id = ' ' or course_join_time is null or course_join_time = ' ' or learn_process is null or learn_process = ' ' or price is null or price = ' ';结果
再逐个检查哪一个字段缺失,我们通过计算price缺失的数据条数,发现和总缺失数据条数一样,最终发现是price缺少。 select count(*) from ( select * from study_information where user_id is null or user_id = ' ' or course_id is null or course_id = ' ' or course_join_time is null or course_join_time ' ' or learn_process is null or learn_process = ' ' or price is null or price = '' ) a where price is null;结果:
而针对空值部分的数据则考虑采取以下措施:对于其余用户出现过的课程,则采用均值代替,对于之前从未出现过程的课程而言,则做删除处理。处理过程如下: 首先课程价格为空的是两个课程:51和96,我们再去搜索是否有别的人选过这两个课并且有price。 select course_id from study_information where price is null group by course_id;
结果:
我们发现没有其他选过这个课的人并且有price信息,因为这两个课程占比不大,所以我们删除这些空值行: DELETE from study_ information where price iS null;|Users表: select * from users where user_ id is null or user_id = ' '; select * from users where school is null or school = ' ';我们发现user_id和school字段有空值,因为user_id比较重要,所以删除这些空值行。而school不太重要我们不做处理。 2.异常值处理:我们发现users表recently_logged数据有问题 select count (*) from users where recently_ logged = '--'结果:
对于这些数据,我们将其分为两类,一类是在study_information出现过的用户,我们用最近的加入课程时间代替最近登陆时间。另一类是在study_information没出现过的用户,我们用它们的注册时间代替最近登陆时间。 update users join (select user_ id, max(course_join_time) as new from study_information group by user_ id) s on users.user_id = s.user_id set users.recently_logged = s.new where users.recently_logged = '--'; update users set recently_logged = register_time where recently_logged = '--'; 3.重复值处理Login: select * from login group by user_id, login_time, login_place having count(*) > 1;结果:
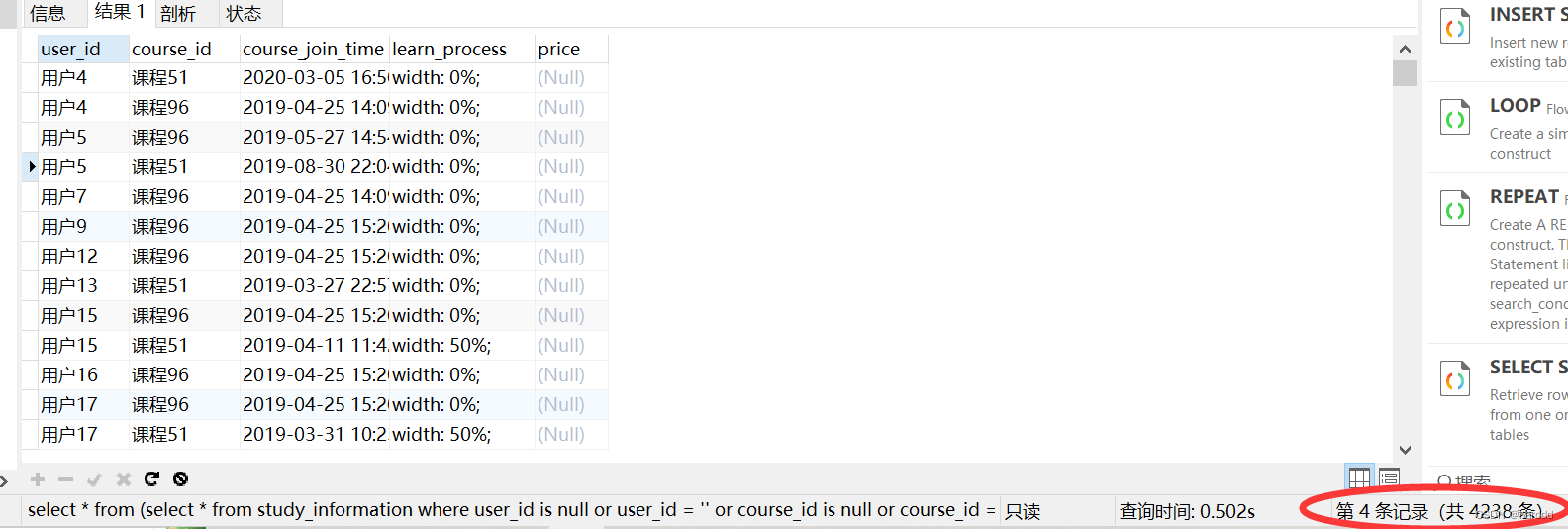
Study_information: select * from study_information group by user_id, course_id, course_join_time, learn_process, price having count(*) > 1;结果:
Users select * from users group by user_id, register_time, recently_logged, number_of_classes_out, number_of_classes_join, 1earn_time, school having count(*) >= 1;
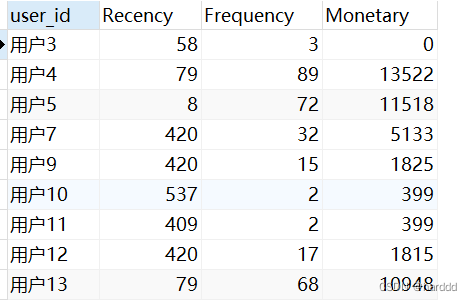
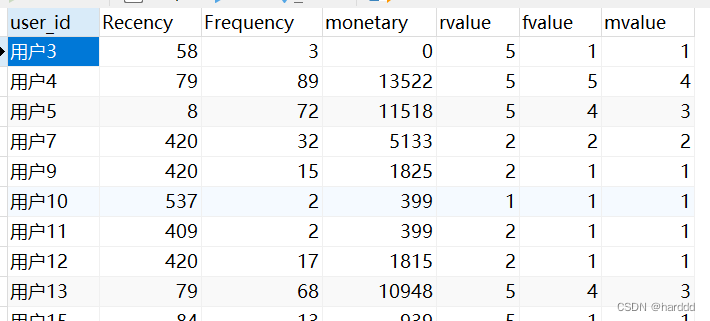
有一部分重复数据,我们对所有数据加入一个id字段,我们删除了重复数据保留id最小的。 delete from users where users.id in (select id from (select *, rank() over(partition by user_id, register_time, recently_ 1ogged, number_of_classes_out, number_of_ classes_join, learn_time, school order by id asc) as r from users) s where r > 1); 五、‘人货场’模型建立 1.用户指标体系我们用最近一次加入课程时间距离表被发出的日期的日期差作为Recency,最近一年加课次数作为Frequency,加入课程的总价格作为Monetary。以这个为基础将用户分为八类:重要价值用户、重要发展用户、重要保持用户、重要挽留用户、一般价值用户、一般发展用户、一般保持用户、一般挽留用户。 'rfm'用户分类 RecencyFrequencyMonetary用户分类高高高重要价值用户 高低高重要发展用户低高高重要保持用户低低高重要挽留用户高高低一般价值用户高低低一般发展用户低高低一般保持用户低低低一般挽留用户我们首先计算出每个用户的Recency、Frequency、Monetary,并用视图保存。 select `study_information`.`user_id` AS `user_id`, (to_days('2020-06-18') - to_days(max(`study_information`.`course_join_time`))) AS `Recency`, sum(if((cast(`study_information`.`course_join_time` as date) >= ((2019 - 6) - 18)),1,0)) AS `Frequency`, sum(`study_information`.`price`) AS `Monetary` from `study_information` group by `study_information`.`user_id`
再然后我们计算出R、F、M三者最大最小值,将最小值与最大值之间区间分为五段、对不同段赋分1-5分,其中要注意R是越小分值越高,其余两者则是越大分值越高。对每个用户算出Rvalue、Fvalue、Mvalue。 select min(`rfm`.`Recency`) AS `minr`,max(`rfm`.`Recency`) AS `maxr` min(`rfm`.`Frequency`) AS `minf`, max(`rfm`.`Frequency`) AS `maxf`, min(`rfm`.`Monetary`) AS `minm`,max(`rfm`.`Monetary`) AS `maxm` from `rfm`
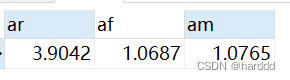
我们再计算出Rvalue、Fvalue、Mvalue的平均值。 select avg(`rfmvalues`.`rvalue`) AS `ar`, avg(`rfmvalues`.`fvalue`) AS `af`, avg(`rfmvalues`.`mvalue`) AS `am` from `rfmvalues`
对于高于平均值的我们认为是高,低于的则是低,我们对用户进行分类。 select `rfmvalues`.`user_id` AS `user_id`, `rfmvalues`.`Recency` AS `Recency`, `rfmvalues`.`Frequency` AS `Frequency`, `rfmvalues`.`monetary` AS `Monetary`, `rfmvalues`.`rvalue` AS `rvalue`, `rfmvalues`.`fvalue` AS `fvalue`, `rfmvalues`.`mvalue` AS `mvalue`, (case when ((`rfmvalues`.`rvalue` > `a`.`ar`) and (`rfmvalues`.`fvalue` > `a`.`af`) and (`rfmvalues`.`mvalue` > `a`.`am`)) then '重要价值用户' when ((`rfmvalues`.`rvalue` > `a`.`ar`) and (`rfmvalues`.`fvalue` `a`.`am`)) then '重要发展用户' when ((`rfmvalues`.`rvalue` `a`.`af`) and (`rfmvalues`.`mvalue` > `a`.`am`)) then '重要保持用户' when ((`rfmvalues`.`rvalue` `a`.`ar`) and (`rfmvalues`.`fvalue` > `a`.`af`) and (`rfmvalues`.`mvalue` `a`.`ar`) and (`rfmvalues`.`fvalue` |

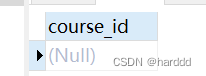
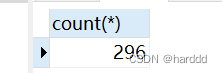

 Login表和Study_information均没有重复数据。
Login表和Study_information均没有重复数据。
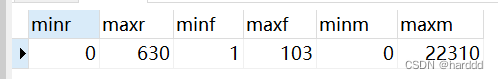
【本文地址】