| 手把手教你:基于TensorFlow的语音识别系统 | 您所在的位置:网站首页 › 用Java实现语言识别 › 手把手教你:基于TensorFlow的语音识别系统 |
手把手教你:基于TensorFlow的语音识别系统
|
系列文章
第十章、手把手教你:基于Django的用户画像可视化系统第九章、手把手教你:个人信贷违约预测模型第八章、手把手教你:基于LSTM的股票预测系统
目录
系列文章一、项目简介二、语音数据集介绍1.不同人的声音2.每人不同单词的发音3.声音波形
三、代码功能介绍1.依赖环境及项目目录2.数据读取与预处理(data_create.py)3.语音数据分帧及mfcc处理(data_create.py)4.模型构建(model.py)5.模型训练(model_train.py)6.模型评估(model_test.py)7.模型训练可视化8.模型预测(func_test.py)
四、代码下载地址
一、项目简介
本文主要介绍如何使用python搭建一个:基于TensorFlow的语音识别系统。 本文主要分为3部分: 1、项目数据集介绍。2、项目功能及相关代码展示。3、项目完整下载地址。博主也参考过语音识别系统相关模型的文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个可视化系统即可。 也正是因为我发现网上大多的帖子只是针对原理进行介绍,功能实现的相对很少。 如果您有以上想法,那就找对地方了! 不多废话,直接进入正题! 二、语音数据集介绍本项目采用的是不同英文单词,不同人的语言发音的电信号采样数据。 1.不同人的声音 三个不同人的声音:
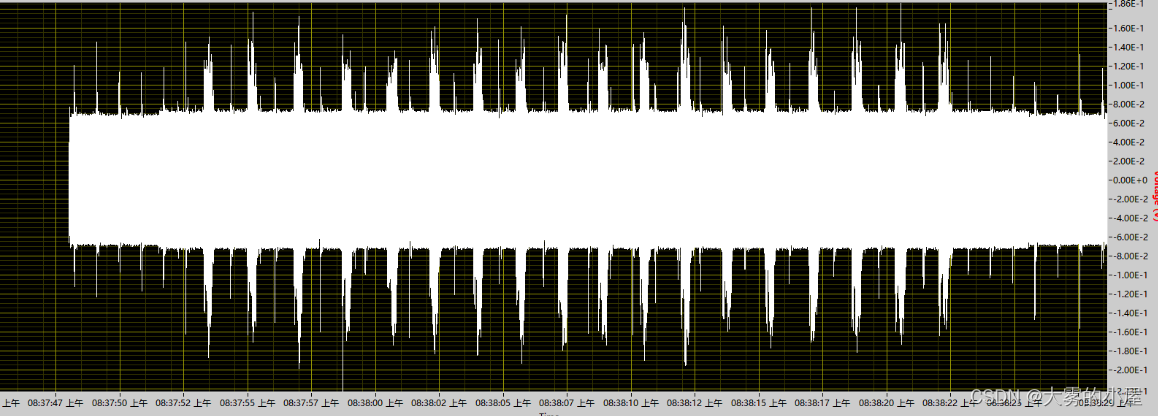 单词“WELCOME”: 单词“WELCOME”: 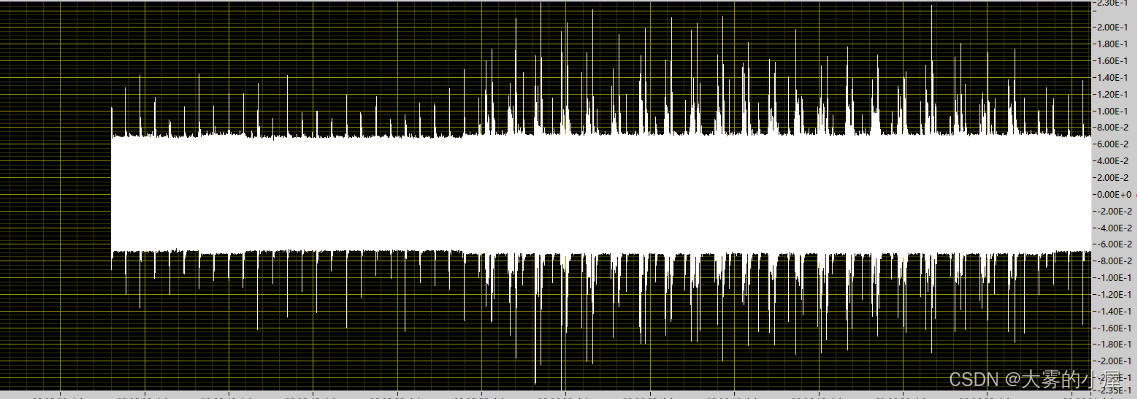 三、代码功能介绍
三、代码功能介绍
项目思路是: 1.将不同单词的发音文件分类。 2.将音频文件进行分帧。 3.实现mfcc编码。 4.构建训练及测试数据。 5.送入模型进行分类训练。 6.验证训练结果 1.依赖环境及项目目录1.TensorFlow-GPU,版本:2.0及以上 2. librosa 3. sklearn 项目目录如下: 戳我: 完整代码下载
2.数据读取与预处理(data_create.py) 戳我: 完整代码下载
2.数据读取与预处理(data_create.py)
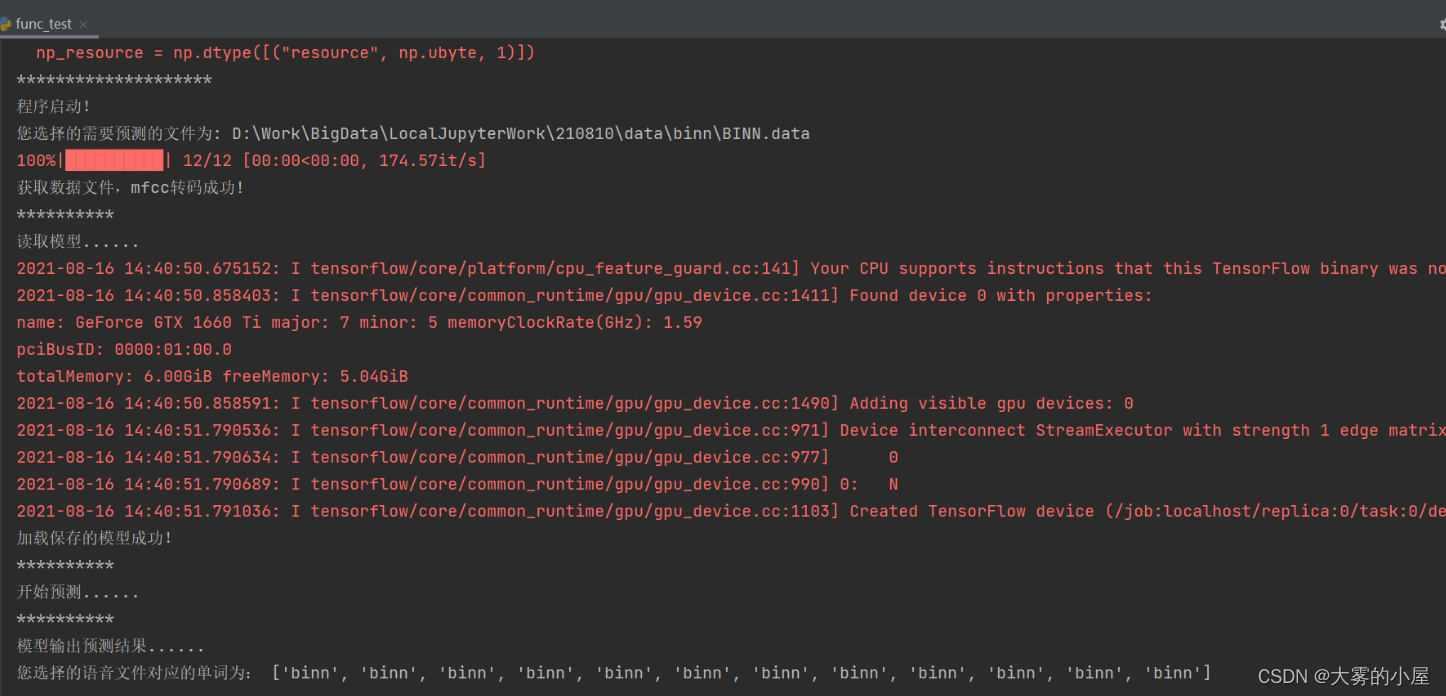
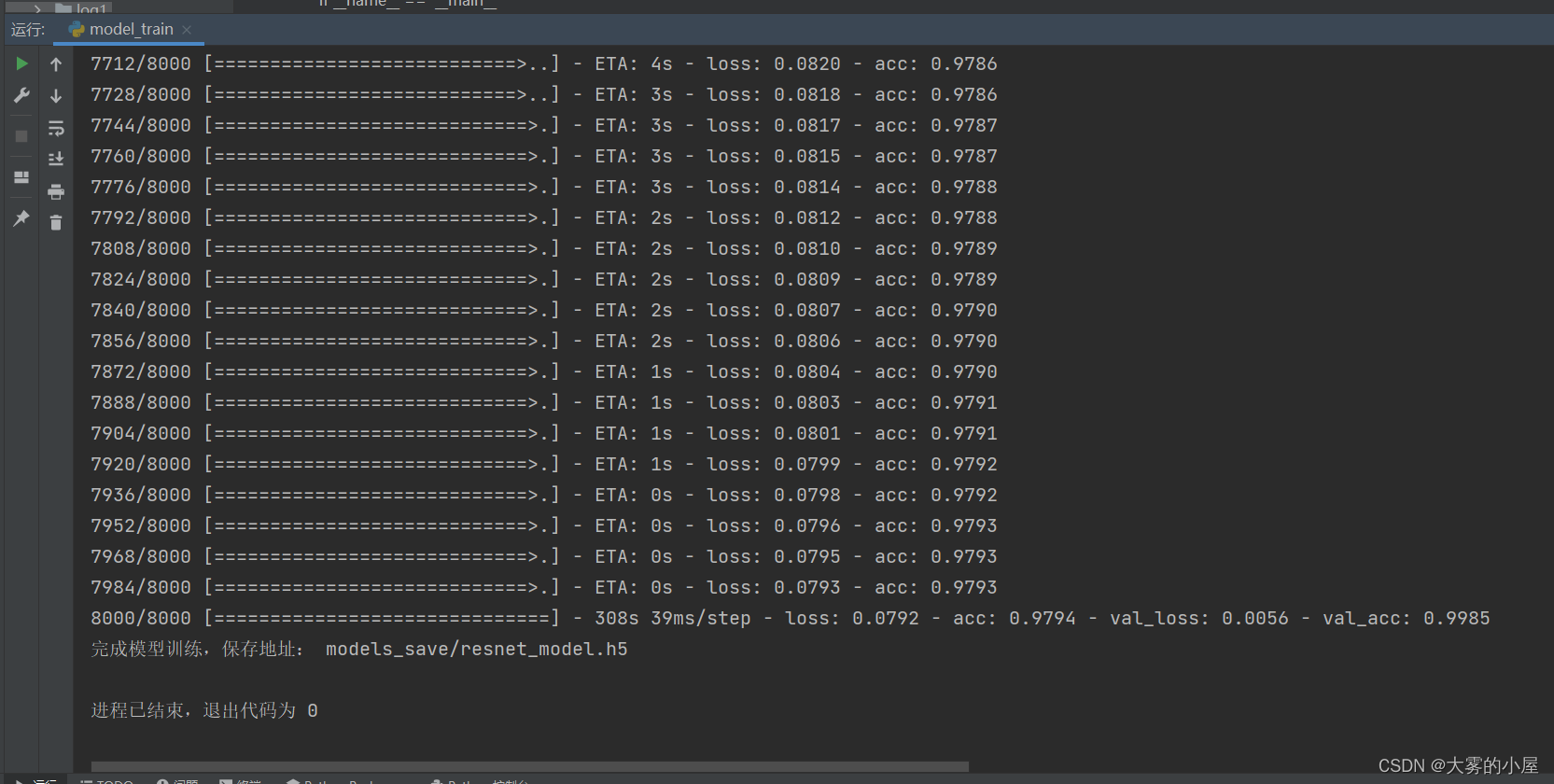
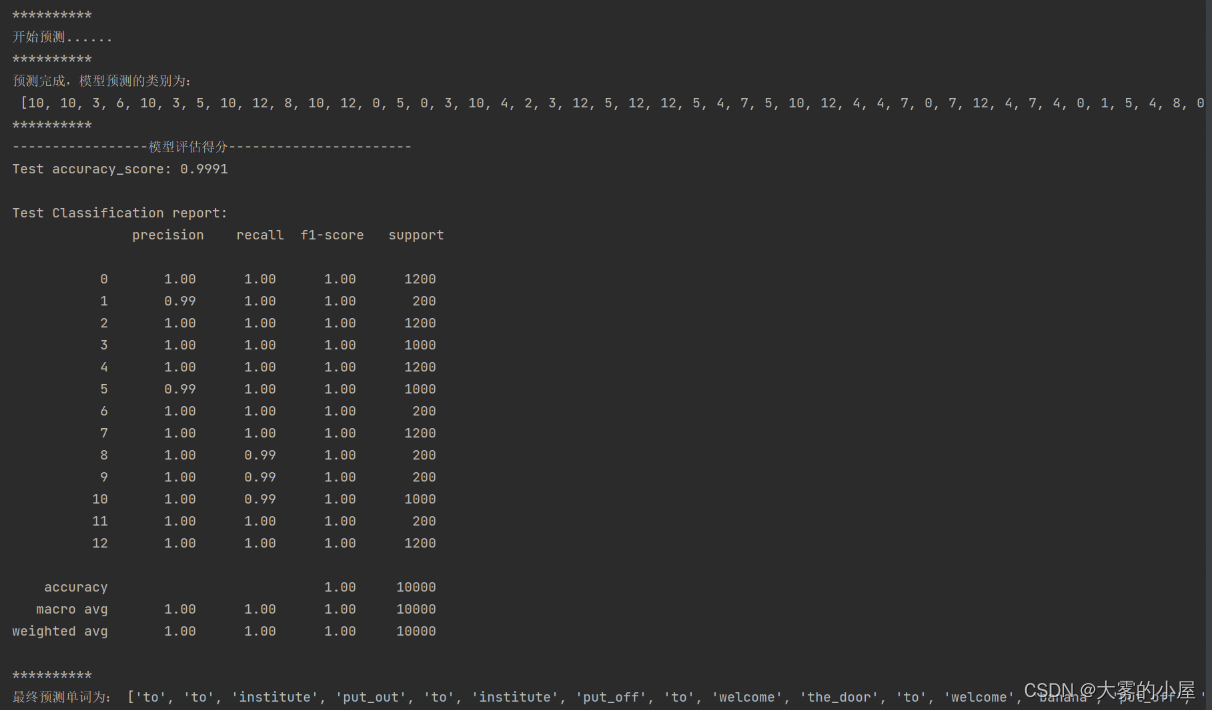
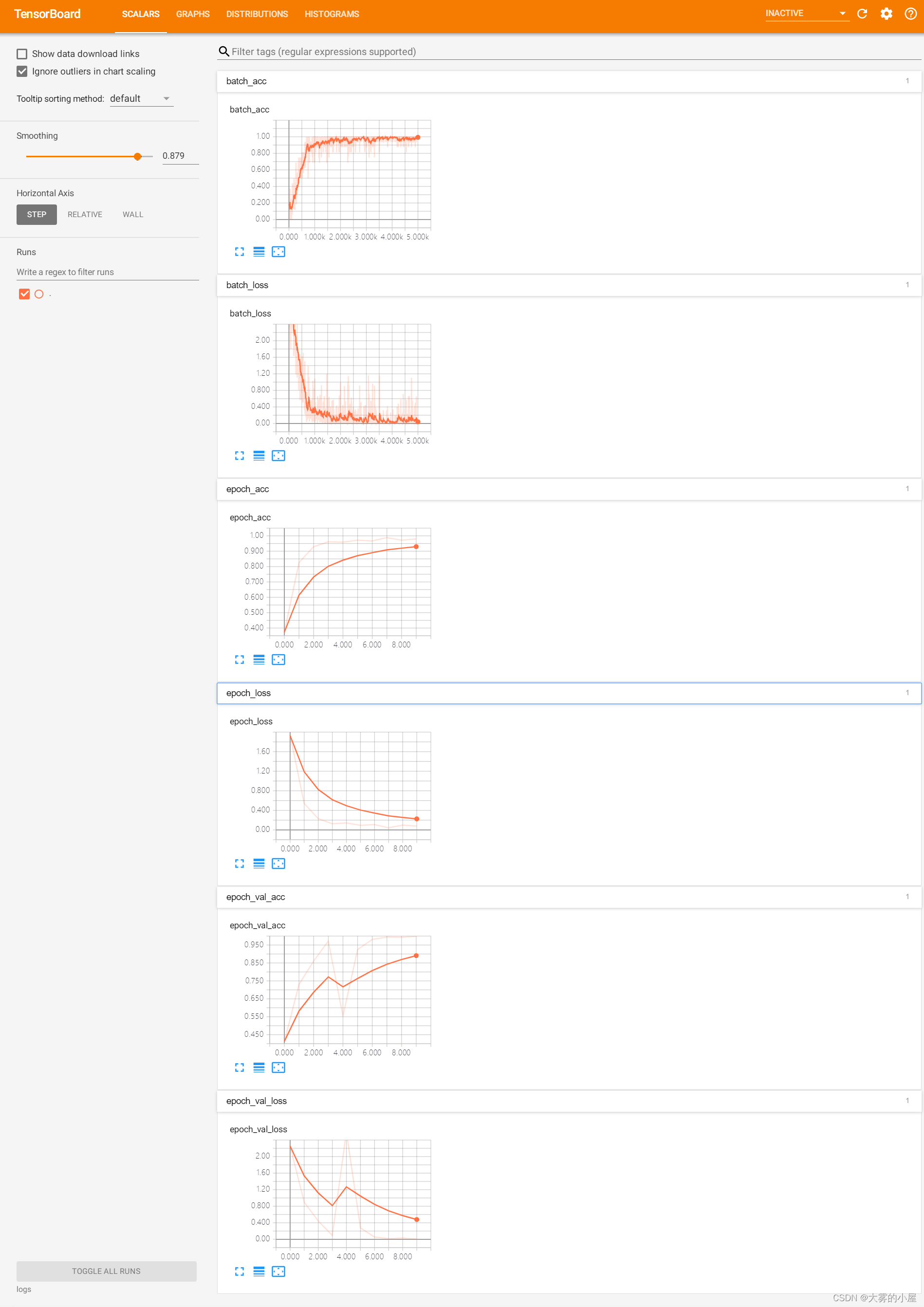
语音数据文件为.data 的时序数据。 def get_voice_vec(path): """ 读取文件 :param path: :return: """ with open(path, 'r') as f: # 读取每行数据 readData = f.readlines() # 删除无用数据 readData_d = readData[9:] voice_list = [] # 将音频数据填入list for e in readData_d: # 分离数据 e_s = e.replace('\n', '').split('\t') voice = e_s[2] voice_list.append(float(voice)) return_list = voice_list return return_list 3.语音数据分帧及mfcc处理(data_create.py)使用librosa对语音数据文件进行分帧和mfcc处理 def vec_label(in_vec, in_label, cut_length=20000, sap_num=50): """ 数据截取,生成训练数据 :return: """ print("读取的数据文件数量:", len(in_vec)) print("开始处理数据分割......") # 最终训练数据 train_data = [] train_label = [] for org_vec, org_label in tqdm(zip(in_vec, in_label)): head_vec = org_vec[:cut_length] end_vec = org_vec[len(org_vec) - cut_length:] # 截取前后2w无声音数据 cuted_vec = org_vec[20000:len(org_vec) - 20000] ''' # 添加无语音块 train_data.append(head_vec) train_label.append("-1") train_data.append(end_vec) train_label.append("-1") # 语音数据分割采样 cut_time = int(len(cuted_vec) / cut_length) for i in range(0, cut_time): cut_vec = cuted_vec[i * cut_length: (i + 1) * cut_length] train_data.append(cut_vec) train_label.append(org_label) ''' for i in range(0, sap_num): # 生成起始位置 start_index = int(random.uniform(0, len(cuted_vec) - cut_length)) # 语音数据分割采样 cut_vec = cuted_vec[start_index:start_index + cut_length] train_data.append(cut_vec) train_label.append(org_label) print("完成数据分割和采样!") train_label = change_label(train_label, "train_data/label_class.npy") print("完成分类类别编码!") # 打乱训练数据 train_data = np.asarray(train_data, np.float64) train_label = np.asarray(train_label, np.int64) print("完成numpy数组转换!") # mfcc编码 train_data = extract_features(train_data) print("完成mfcc编码!") train_data, train_label = random_data(train_data, train_label) print("完成数据打乱!") return train_data, train_label 4.模型构建(model.py)使用TensorFlow对模型进行构建,本文构建的是基于残差模块的cnn网络。 def __init__(self, input_shape=(512, 512, 3), classes=2): self.input_shape = input_shape self.classes = classes # 恒等模块——identity_block def identity_block(self, X, f, filters, stage, block): """ 三层的恒等残差块 param : X -- 输入的张量,维度为(m, n_H_prev, n_W_prev, n_C_prev) f -- 整数,指定主路径的中间 CONV 窗口的形状 filters -- python整数列表,定义主路径的CONV层中的过滤器数目 stage -- 整数,用于命名层,取决于它们在网络中的位置 block --字符串/字符,用于命名层,取决于它们在网络中的位置 return: X -- 三层的恒等残差块的输出,维度为:(n_H, n_W, n_C) """ # 定义基本的名字 conv_name_base = "res" + str(stage) + block + "_branch" bn_name_base = "bn" + str(stage) + block + "_branch" # 过滤器 F1, F2, F3 = filters # 保存输入值,后将输入值返回主路径 X_shortcut = X # 主路径第一部分 X = layers.Conv2D(filters=F1, kernel_size=(1, 1), strides=(1, 1), padding="valid", name=conv_name_base + "2a", kernel_initializer=keras.initializers.glorot_uniform(seed=0))(X) X = layers.BatchNormalization(axis=3, name=bn_name_base + "2a")(X) X = layers.Activation("relu")(X) # 主路径第二部分 X = layers.Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding="same", name=conv_name_base + "2b", kernel_initializer=keras.initializers.glorot_uniform(seed=0))(X) X = layers.BatchNormalization(axis=3, name=bn_name_base + "2b")(X) X = layers.Activation("relu")(X) # 主路径第三部分 X = layers.Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding="valid", name=conv_name_base + "2c", kernel_initializer=keras.initializers.glorot_uniform(seed=0))(X) X = layers.BatchNormalization(axis=3, name=bn_name_base + "2c")(X) # 主路径最后部分,为主路径添加shortcut并通过relu激活 X = layers.Add()([X, X_shortcut]) X = layers.Activation("relu")(X) return X # 卷积残差块——convolutional_block def convolutional_block(self, X, f, filters, stage, block, s=2): """ param : X -- 输入的张量,维度为(m, n_H_prev, n_W_prev, n_C_prev) f -- 整数,指定主路径的中间 CONV 窗口的形状(过滤器大小,ResNet中f=3) filters -- python整数列表,定义主路径的CONV层中过滤器的数目 stage -- 整数,用于命名层,取决于它们在网络中的位置 block --字符串/字符,用于命名层,取决于它们在网络中的位置 s -- 整数,指定使用的步幅 return: X -- 卷积残差块的输出,维度为:(n_H, n_W, n_C) """ # 定义基本名字 conv_name_base = "res" + str(stage) + block + "_branch" bn_name_base = "bn" + str(stage) + block + "_branch" # 过滤器 F1, F2, F3 = filters # 保存输入值,后将输入值返回主路径 X_shortcut = X # 主路径第一部分 X = layers.Conv2D(filters=F1, kernel_size=(1, 1), strides=(s, s), padding="valid", name=conv_name_base + "2a", kernel_initializer=keras.initializers.glorot_uniform(seed=0))(X) X = layers.BatchNormalization(axis=3, name=bn_name_base + "2a")(X) X = layers.Activation("relu")(X) # 主路径第二部分 X = layers.Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding="same", name=conv_name_base + "2b", kernel_initializer=keras.initializers.glorot_uniform(seed=0))(X) X = layers.BatchNormalization(axis=3, name=bn_name_base + "2b")(X) X = layers.Activation("relu")(X) # 主路径第三部分 X = layers.Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding="valid", name=conv_name_base + "2c", kernel_initializer=keras.initializers.glorot_uniform(seed=0))(X) X = layers.BatchNormalization(axis=3, name=bn_name_base + "2c")(X) # shortcut路径 X_shortcut = layers.Conv2D(filters=F3, kernel_size=(1, 1), strides=(s, s), padding="valid", name=conv_name_base + "1", kernel_initializer=keras.initializers.glorot_uniform(seed=0))(X_shortcut) X_shortcut = layers.BatchNormalization(axis=3, name=bn_name_base + "1")(X_shortcut) # 主路径最后部分,为主路径添加shortcut并通过relu激活 X = layers.Add()([X, X_shortcut]) X = layers.Activation("relu")(X) return X 5.模型训练(model_train.py)本次项目设置的同时输入语音数据:batch_size = 16。训练轮数:num_epochs = 10。初始化学习率参数:learning_rate = 1e-4。训练结果如下: 针对13个不同人的发音的单词进行训练后测试模型分类的准确率。
 四、代码下载地址
四、代码下载地址
由于项目代码量和数据集较大,感兴趣的同学可以直接下载代码,使用过程中如遇到任何问题可以在评论区进行评论,我都会一一解答。 代码下载: 【代码分享】手把手教你:基于TensorFlow的语音识别系统 |
【本文地址】
公司简介
联系我们