| 毕业设计 | 您所在的位置:网站首页 › 生产日期扫描 › 毕业设计 |
毕业设计
|
目录 前言 课题背景和意义 实现技术思路 一、预处理与识别 二、图像预处理 三、商品生产日期字符识别 实现效果图样例 最后 前言📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。 🚀对毕设有任何疑问都可以问学长哦! 选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277 大家好,这里是海浪学长毕设专题,本次分享的课题是 🎯基于机器视觉的生产日期字符识别研究-OpenCV 课题背景和意义 商品的标识技术是对标签进行编码和标记的技术手段,也是产品可追溯性的基础。标识技术关系到物流、食品和电子商务等多个行业,影响深远。伴随人们生活水平的提高,对于健康和安全的关注越来越多,每个行业对产品的品质和安全性的要求也越来越高。编码标识的不统一阻碍了各个行业的发展,包括对产品的溯源、电子商务及对产品标签标准化的要求,因此,国家商品生产日期标识规范体系的建立显得尤为必要。如今消费者对食品安全要求越来越高,这就对食品饮料行业在产品信息可追溯方面提出了更高的要求。在食品饮料包装上,我们可以看到经常印有生产日期、保质日期等信息,这类型印刷的一个明显特征是:大批量生产,对印刷要求非常高。保证生产日期等相关信息正确清晰地标注是食品生产过程中的一个重要环节。此类识别检测工作具有高度重复性,传统人工检测会给工厂增加巨大的人工成本和管理成本,检测效率低,速度慢,还无法保证100%的检验合格率。利用机器视觉技术进行OCR字符采集检测具有非常广阔的市场需求。 实现技术思路 采用的商品标签识别过程如图:
图像噪声处理 在收集、传输和处理图像的过程中,图像会产生一些不可避免的噪声,包含与图像无关和冗余滋扰信息。降低图像噪声不仅可以使图像更加清晰,而且可以突出图像的感兴趣区域,易于识别。
图像二值化 遍历像素点,通过选取合适的值,灰度值二分为255 或 0 ,白色为 255 ,黑色为 0 ,如式 所示。分类后图像变为黑白,分辨图像中的图形和文本,便于后续将文本信息提取出来
1)Otsu 算法 此算法是把背景和目标阈值的差距拉大,分裂性较强,所求的是类内方差 min ,和类间方差的 max ,首先遍历所有像素点,统计灰度级像素的个数,将图像灰度化,再次遍历计算出最大类间方差,程序略显复杂 ,效果图如图:
然后是该点的阈值 Txy (, ) ,其中 T 的大小可以根据k 来调节:
边缘检测 边缘检测是通过卷积或微分计算后得到的二值化图像。 1 ) Laplacian 算子边缘检测 拉普拉斯算子被分成 4 个和 8 个邻域,域是像素梯度需求邻域的 4 个相邻方向上的中央附近的方向和梯度。
计算梯度值的方向:
④ NMS(非极大值抑制) 留存边缘方向上具有极大值的像素,通过 NMS 找出其中的局部最大值,将其他位置的值取 0。 ⑤双阈值的边界选取 梯度大于任何边缘的最大阈值是真正的边缘,而低于最小阈值的边缘为非边缘,非边缘即舍去。
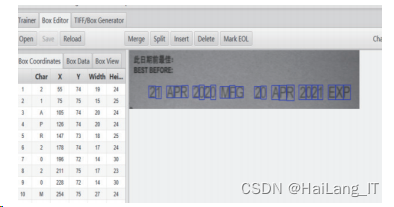
本文算法的选取 中值滤波是对光滑脉冲噪声表现良好,效果图像的边界顺滑清晰。与平均灰度法比较,Sauvola 使用二值化的图像,能解决产生照度不均的影响。拉普拉斯对噪声敏感,分辨边缘像素的位置表现优异,但易出现双像素边界,导致日期显示模糊不清晰;Canny 对比Laplacian 克制了噪声引起的非边缘,对于光照不均的图像也能有如图所示的效果,线条更流畅光滑,同时细化过的边缘比较清晰,易于后续的识别工作。 三、商品生产日期字符识别 识别目的 在车间生产中,生产日期是由操作工人设置喷印装 置并对生产日期进行喷印。生产日期的错误为后续的溯 源、仓储造成困难。为避免生产资料的浪费和后续工作 的开展,制作日期字符识别数据集并校验成果。 字符集的创建和测试 在 jTessBoxEditor 编辑器中点击 merge tiff ,打开拍摄到的商品生产日期图片,并为文件命名,以生成训练集的 tif 文件。
利用窗口上方的模块,对文件内字符进行框选,调整字体坐标,标准为一字一框,并对识别的字符进行修正,最后点击 save。 在输入命令后创建字体特征文件,之后开始对字符文件进行训练,并把生成的文件合并,即得到训练文件。
字符识别的正确率受前期图片处理的程度和字符库的影响,训练集中包含英文、中文和数字三种字符,为了验明三种字符的单独测试效果,从以下四个方向进行观察测试: 1 )中文字符正确率 2 )英文字符正确率 3 )数字字符正确率 4 )全部字符正确率 实现效果图样例生产日期字符识别:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。 毕设帮助,疑难解答,欢迎打扰! 最后 |

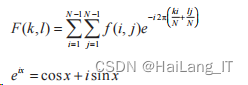


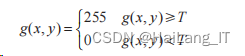




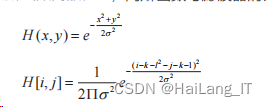
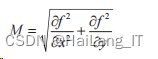





【本文地址】