| 二手汽车爬虫的三种实现方式 | 您所在的位置:网站首页 › 瓜子二手车送车业务 › 二手汽车爬虫的三种实现方式 |
二手汽车爬虫的三种实现方式
|
一、抓包json实现(瓜子二手车网)
1.思路
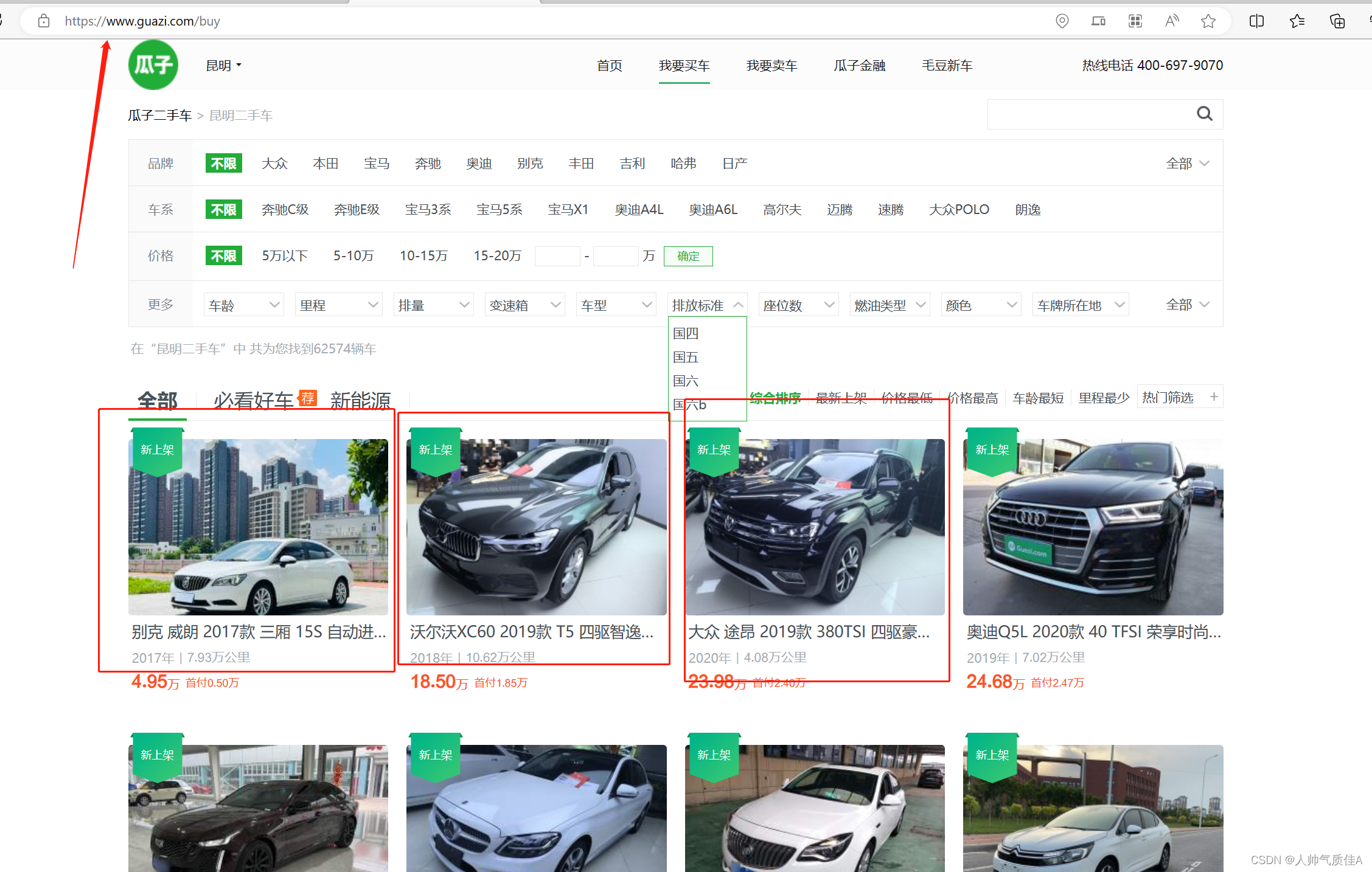
页面的数据是后端通过接口的形式传给前端,直接去抓后端数据包,发送请求并解析响应。 2.实现过程 2.1页面分析【昆明二手车】昆明二手车交易市场_昆明二手车报价_昆明二手车市场-昆明瓜子二手车 (guazi.com) 进入该页面,暂时称为列表页(汽车信息条数多,每一条汽车信息较少)
点击每一个红框,进入对应该车的详情页面 可以看到详情页里面汽车信息很多,满足要求,红框框住的clueid为每辆车对应的标识(就像每个人对应每一个身份证一样),因此,要从标题页进入详情页,就要找到每一辆汽车的clueid。 寻找方式一般为:右键——>检查——>网络——>Fetch/XHR——>刷新网页——>观察数据包响应 找到响应数据量较大的去寻找clueid,这里我找到之后截图如下:
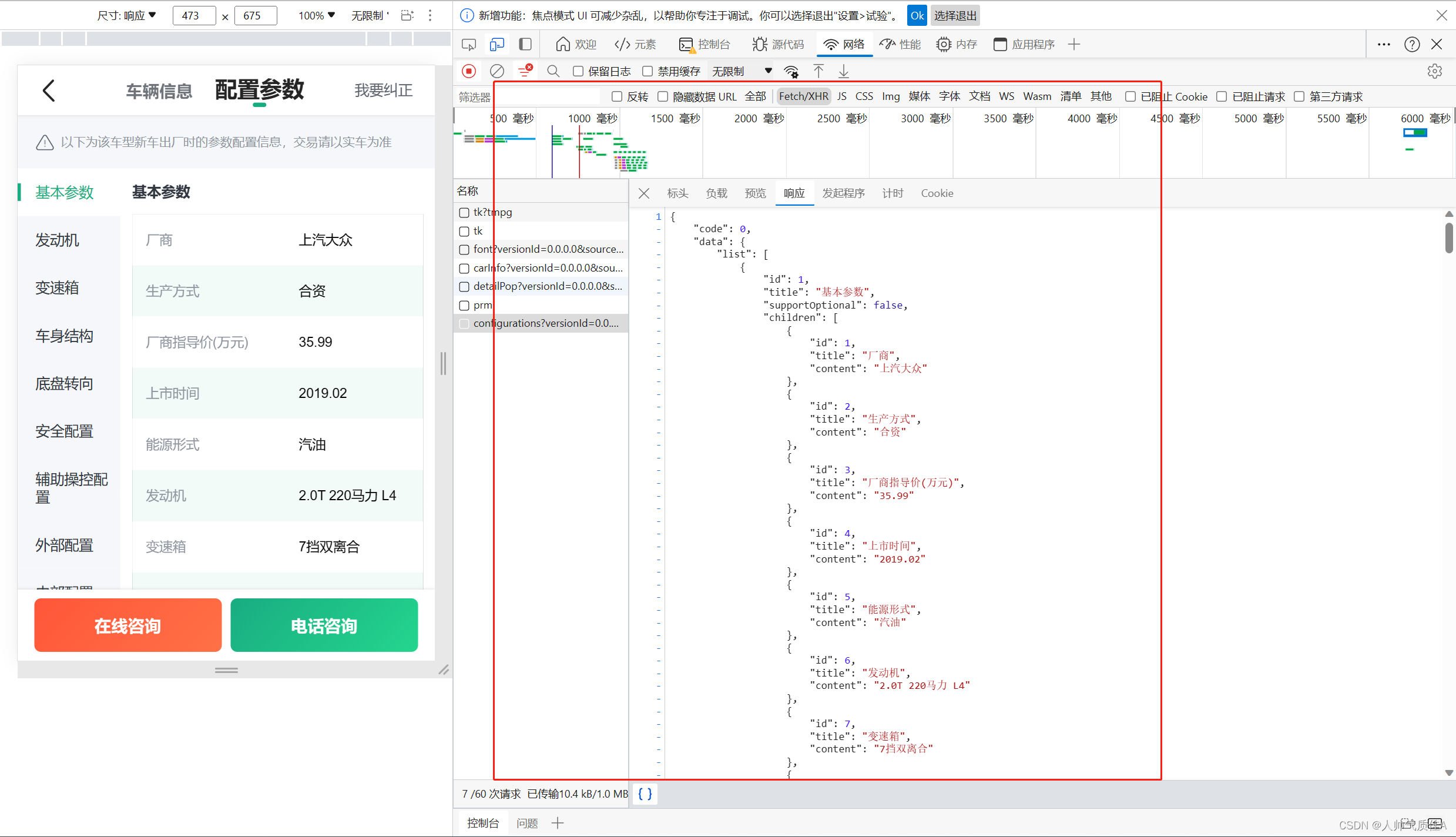
可以发现和上图所示详情页的clueid一样。并且这个数据包响应是列表形式,这个列表中就会有这个网页对应的20辆车的clueid。 下一步是对详情页提取需要的信息,还是抓取数据包,步骤如上(从右键检查到观察数据包响应)截图如下:
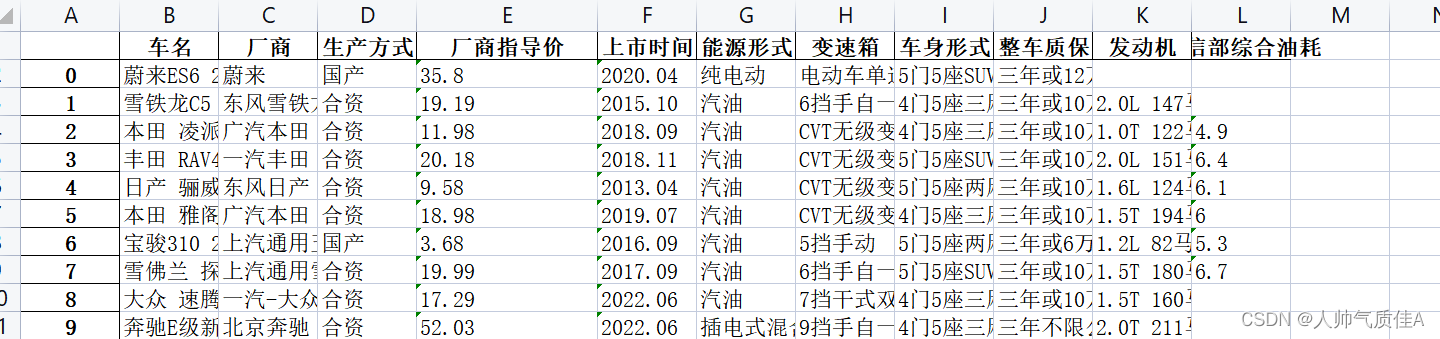
还是列表包着每一辆车的参数信息,因此只要观察这个接口的url和参数,发送请求,解析响应。 2.2代码 import requests import json import pandas as pd data = pd.DataFrame() import random n = 0先导入库,创建二维表。 for x in range(1,50): user_agent_list = [ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36", "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15", ] url = 'https://mapi.guazi.com/car-source/carList/pcList?versionId=0.0.0.0&sourceFrom=wap&deviceId=87684c24-3cc5-40cd-9450-5d73255ebeb7&osv=Windows+10&minor=&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=&tag=-1&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=&emission=&car_color=&guobie=&bright_spot_config=&seat=&fuel_type=&order=7&priceRange=0,-1&tag_types=&diff_city=&intention_options=&initialPriceRange=&monthlyPriceRange=&transfer_num=&car_year=&carid_qigangshu=&carid_jinqixingshi=&cheliangjibie=&page='+str(x)+'&pageSize=20&city_filter=225&city=225&guazi_city=225&qpres=&platfromSource=wap' headers = { "Accept-Encoding":"gzip, deflate, br", "Cookie":"uuid=87684c24-3cc5-40cd-9450-5d73255ebeb7; sessionid=489fbf96-cf12-44a3-f5d3-68239a666035; guazitrackersessioncadata=%7B%22ca_kw%22%3A%22-%22%7D; cainfo=%7B%22ca_s%22%3A%22seo_bing%22%2C%22ca_n%22%3A%22default%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22scode%22%3A%22-%22%2C%22guid%22%3A%2287684c24-3cc5-40cd-9450-5d73255ebeb7%22%7D" } headers['User-Agent'] = random.choice(user_agent_list) response = requests.get(url=url, headers=headers) print("-----------------------------------------------------------------") print("正在爬取第"+str(x)+"页") print("-----------------------------------------------------------------") for i in response.json()['data']['postList']: data.loc[n,'车名'] =str(i['title']) son_url = 'https://mapi.guazi.com/car-source/carRecord/pcConfigurations?versionId=0.0.0.0&sourceFrom=wap&deviceId=87684c24-3cc5-40cd-9450-5d73255ebeb7&osv=Windows+10&clueId='+str(i['clue_id'])+'&platfromSource=wap' son_response = requests.get(url=son_url, headers=headers) # print(son_response.json()['list']) for j in son_response.json()['data']['list']: if j['title']=='基本参数': for k in j['children']: if k['title']=='厂商': data.loc[n,'厂商'] = k['content'] elif k['title']=='生产方式': data.loc[n,'生产方式'] = k['content'] elif k['title']=='厂商指导价(万元)': data.loc[n,'厂商指导价'] = k['content'] elif k['title']=='上市时间': data.loc[n,'上市时间'] = k['content'] elif k['title']=='能源形式': data.loc[n,'能源形式'] = k['content'] elif k['title']=='发动机': data.loc[n,'发动机'] = k['content'] elif k['title']=='变速箱': data.loc[n,'变速箱'] = k['content'] elif k['title']=='工信部综合油耗(L/100km)': data.loc[n,'工信部综合油耗'] = k['content'] elif k['title']=='车身形式': data.loc[n,'车身形式'] = k['content'] elif k['title']=='整车质保(生产厂商)': try: data.loc[n,'整车质保'] = k['content'] except: data.loc[n, '整车质保']='' print(data.loc[n,]) n = n+1 data.to_excel("瓜子二手车.xlsx")第一个大循环1到50控制的是标题页面数量
如上所示的1到50。headers的设置用来模拟浏览器(这里是随机模拟的),防止反扒,保存信息以及设置响应编码等。 对每个标题页面请求后,对其响应设置json格式,然后一层一层循序渐进找到需要的clueid(在这里我还保存了车名),找到clueid又拼接成正确的详情页url,对详情页发送请求,并把响应同样设置为json格式。 最后就在循环中解析json中我们需要的数据,保存在DataFrame,n表示控制行数,循环结束执行+1操作 值得注意的是: 1.if else条件分支语句是根据响应数据本身的特征来写,目的是精准定位我们所需要的数据。 2.try except异常捕获语句是爬取过程中,有的车辆没有质保信息,抛出空异常。 3.代码中第一个for循环是拼接不同标题页面的url,第二个for循环是拼接详情页的url,第三个for循环是定位数据用的。 最后在循环体外导出为表格。
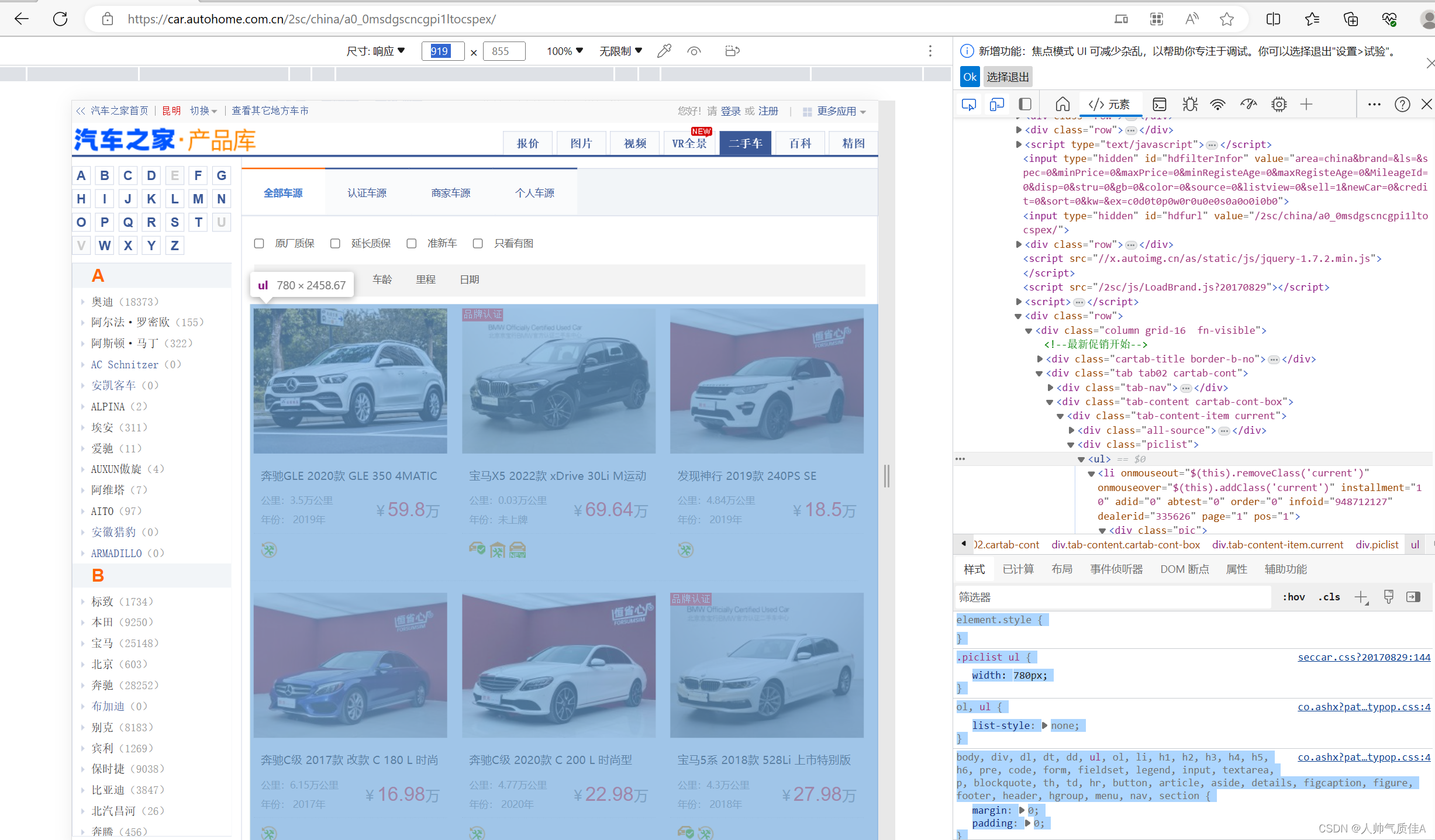
二、BeautifulSoup实现(二手之家网) 1.思路 抓包方式找不到的情况下,数据是通过html、css、javascript写在了网页上,此时就需要去网页定位数据,通过html的标签关系以及css的选择方式抓取数据。 2.实现过程 2.1页面分析全国二手车_二手车之家 (autohome.com.cn)
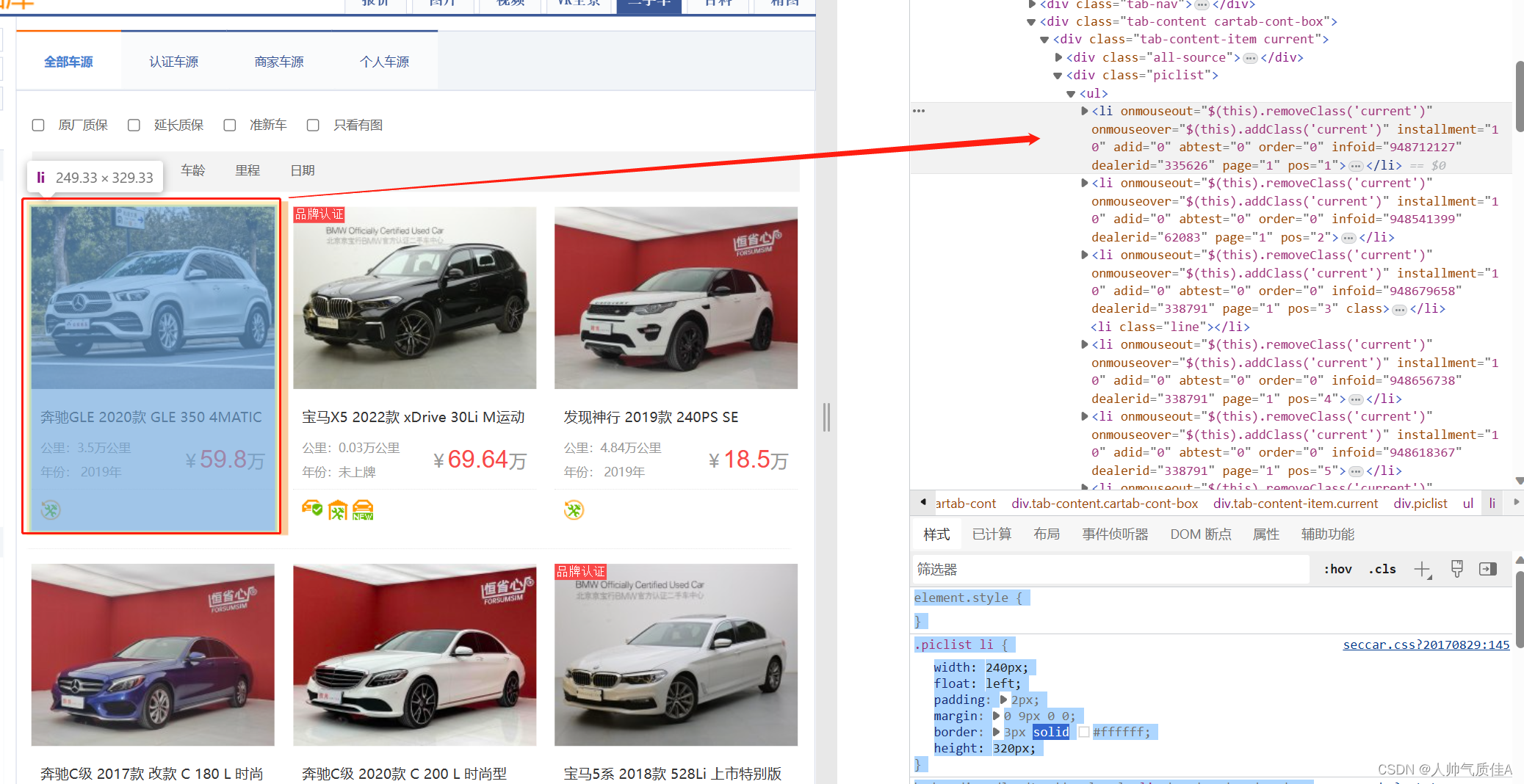
右键——>检查——>元素——元素最左边的框框——>去网页框数据——>查看对应的html、css代码 很明显,根据前端经验,这里的每一辆车对应一个盒子,对应右边的一个ul儿子li标签
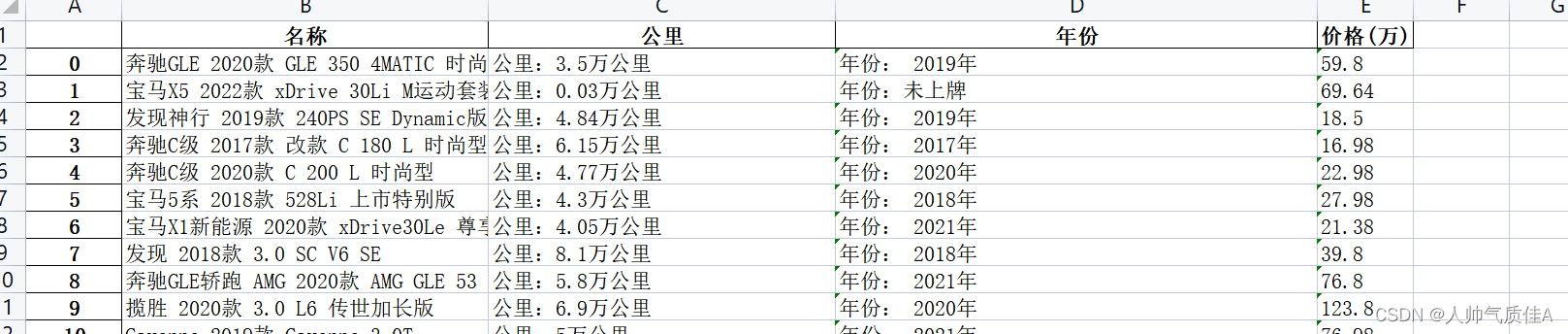
因此,对该网页发送请求,定位到每一个li标签,从li标签里面解析出车名、年份、里程、价格。 2.2代码 import requests from bs4 import BeautifulSoup headers = { "User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.203" } n=0 import pandas as pd data = pd.DataFrame() for i in range(1,40): url = "https://car.autohome.com.cn/2sc/china/a0_0msdgscncgpi1ltocsp"+str(i)+"ex/" resp = requests.get(url, headers=headers) html = resp.text soup = BeautifulSoup(html, 'html.parser') gain = soup.find("div",class_='piclist').find("ul").find_all("li") for j in gain: try: data.loc[n,'名称'] = j.find("div",class_='title').find("a").get_text() # print(name) except: continue # data.loc[n,'公里'] = j.find("div",class_='detail-l').find("p").get_text() data.loc[n,'公里'] = j.find("div",class_='detail-l').find_all("p")[0].get_text() data.loc[n, '年份'] = j.find("div",class_='detail-l').find_all("p")[1].get_text() data.loc[n, '价格(万)'] = j.find("div",class_='detail-r').find("span").get_text() print(dict(data.loc[n,])) n =n+1 data.to_excel("二手之家汽车情况-bs4.xlsx")代码导入request、BeautifulSoup、pandas库,设置headers,创建data表。 第一个循环控制的是网页的翻页,从第一页到第四十页,拼接url字符串实现的
对每一个url发送请求,.text设置响应为文本格式并利用它实例化一个BeautifulSoup对象。
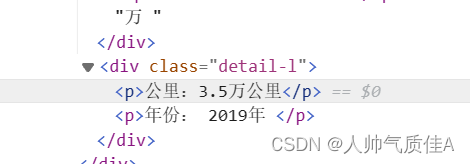
这句代码定位到所有的li标签。 在下面一个for循环就是对每一个li标签的循环。每一个li标签解析出相应的内容。 值得注意的是: 1.查找元素可以利用语法find(“标签”,class_ = “类名”),class是python关键字,因此用class_。 2.find方法返回的是元素本身,find_all方法返回的是元素列表,比如 data.loc[n,'公里'] = j.find("div",class_='detail-l').find_all("p")[0].get_text() data.loc[n, '年份'] = j.find("div",class_='detail-l').find_all("p")[1].get_text()
find_all此处返回的列表装有公里和年份,列表取[0]代表公里,取[1]代表年份。 3.代码中的try——except语句是由于有的li标签不存在汽车信息,如果名称没有解析到执行continue关键字跳过这个元素,执行下一个元素的解析。 最后导出为表格。
三、selenium实现(二手之家网) 1.思路 抓包方式找不到的情况下,数据是通过html、css、javascript写在了网页上,不仅仅可以通过beautifulsoup定位,还能利用selenium控制浏览器并且自动定位提取。 2.实现过程 2.1页面分析同上一小节 2.2代码 import pandas as pd from selenium.webdriver import Chrome from selenium.webdriver.common.by import By # 键盘按键包 from selenium.webdriver.common.keys import Keys # 创建浏览器对象 # executable_path 表示浏览器驱动路径 web =Chrome() n=0 data = pd.DataFrame() for i in range(1,10): url = "https://car.autohome.com.cn/2sc/china/a0_0msdgscncgpi1ltocsp"+str(i)+"ex/" web.get(url) # 获取网站title标签 print(web.title) list_info = web.find_elements(By.XPATH,'/html/body/div[2]/div/div[2]/div[4]/div/div[2]/div[2]/div/div[2]/ul/li') import time time.sleep(2) for i in list_info: try: data.loc[n,'名称'] = i.find_element(By.XPATH,'./div[2]/a').text except: continue data.loc[n,'公里'] = i.find_element(By.XPATH,'./div[3]/div[2]/p[1]').text[3:] data.loc[n, '年份'] = i.find_element(By.XPATH,'./div[3]/div[2]/p[2]').text[4:] data.loc[n, '价格(万)'] = i.find_element(By.XPATH, './div[3]/div[1]/span').text print(dict(data.loc[n,])) n =n+1 data.to_excel("二手之家汽车情况-selenium.xlsx")导入所需要的库之后创建一个谷歌浏览器对象,创建表格。 循环控制翻页,书写正确的url,调用get方法自动请求网页,输出网页标题。 然后查找元素,利用xpath方法,此处的xpath可以直接在浏览器右键复制。
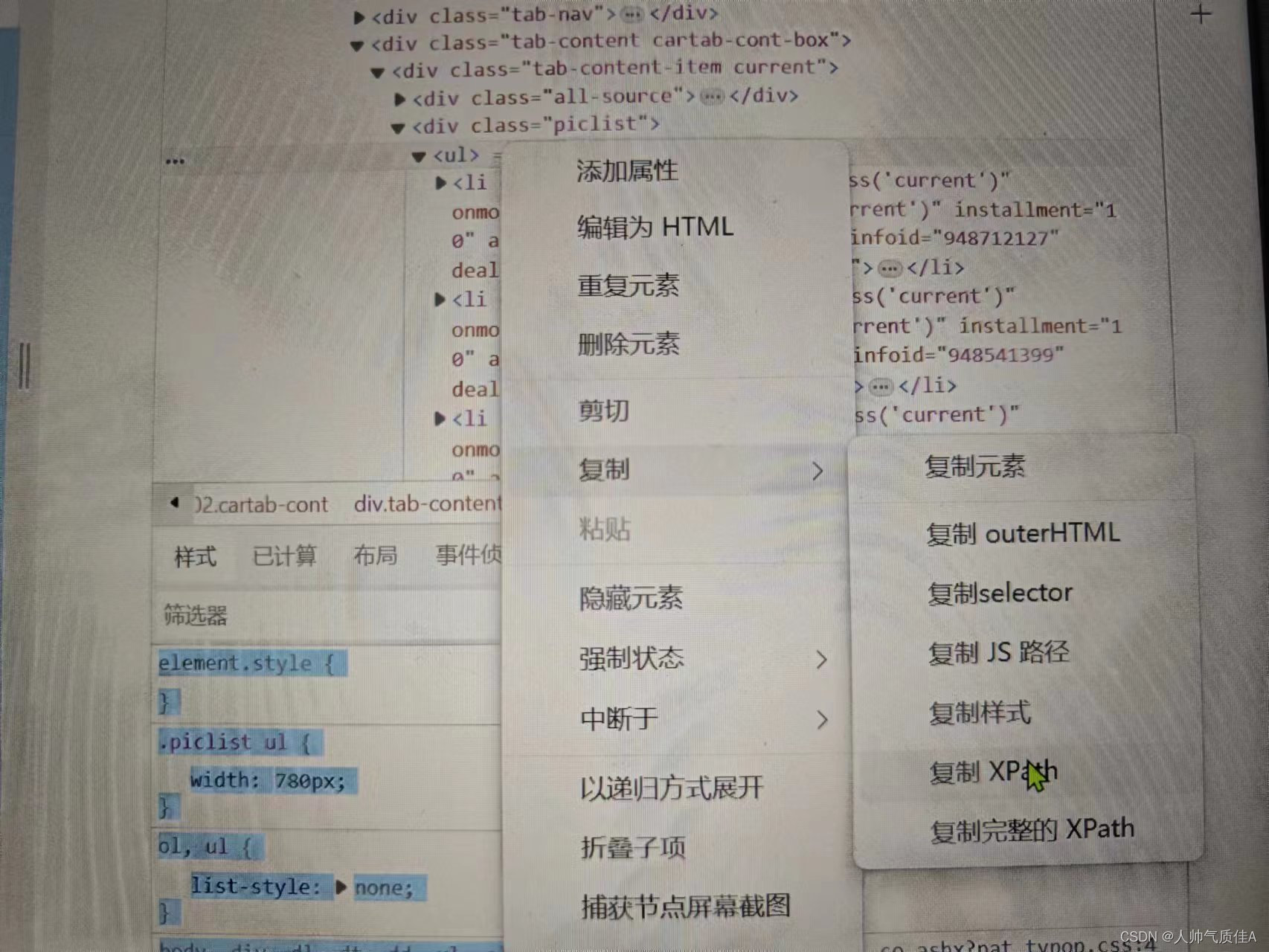
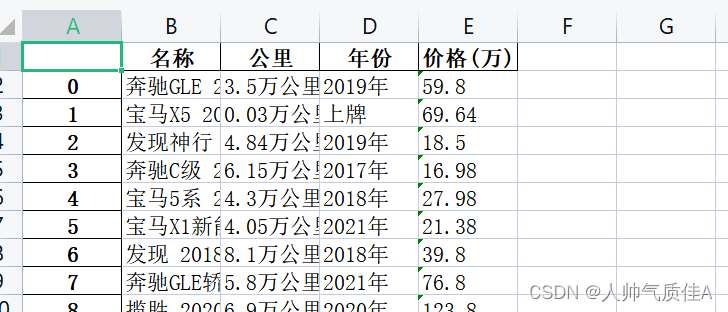
第二个循环同样是对一个网页内的不同车辆信息的循环。在循环中利用刚刚定位的li标签列表为父元素,继续寻找子元素标题、公里、年份、价格等。 值得注意的是: 1.此处selenium控制谷歌浏览器,需要给谷歌浏览器安装驱动才能被代码自动控制。 2.在selenium解析html时候,浏览器的xpath路径是可以直接复制使用的,尔使用lxml的etree树解析的时候,是不能直接右键复制xpath的,大概率定位不到元素。 3.列表切片是为了让数据更好看,解析出来不加切片,就是 公里: 3.5万公里。加了切片直接是3.5公里,年份也是这样一个效果。
4.xpath的寻找元素方式是以标签为节点的树。 最后导出为表格:
四、写在最后 菜鸡一枚,仅仅记录与分享。欢迎大佬多多指正,也欢迎交流。 |



【本文地址】