|
最近学习目标检测,通过多方找资料学习,以及看别的大佬的博客,终于是实现了自己的目标检测,数据集是本人打开王者荣耀亲自操作录制的视频哈哈哈,相信看完这篇博客之后你也能够自己录制一段视频实现自己的目标检测算法。先看看效果
YOLOv5实现王者荣耀目标检测
本文旨在帮助大家用yolov5从头到尾实现自己的目标检测,包括视频数据集转图片数据集、图片数据集的标注、训练集和验证集的划分、模型的训练以及测试。同时记录一下自己实现过程中遇到的问题以及报错,提醒自己以后不再踩相同的坑,也帮助大家避坑。接下来就开始步入正题。
第一步:数据集的准备。yolov5用来训练的数据集为图片,如果你自己的数据集是视频,那就需要将视频数据集转换为图片,本人用的数据集就是自己录制的视频。这里有现成的代码,可以直接使用,将其转换为图片。这里用的是cv2的库,需要自己提前安装,安装方法自己搜索即可。需要注意的是,这里的视频路径和保存路径需要自己设置,每一级目录要用反斜杠隔开,并且路径中均不能有中文命名,不然会找不到所转换的图片,这里设置的是每10帧取一张图片,读者也可以根据需要自行设置,后面的代码无需更改。
import cv2
video_path = 'E:/Master/DeepLearning/CV/YOLOv5-libai/video.mp4' # 视频地址
output_path = 'E:/Master/DeepLearning/CV/YOLOv5-libai/VOCdevkit/VOC2007/JPEGImages/' # 输出文件夹
interval = 96 # 每间隔10帧取一张图片,
if __name__ == '__main__':
num = 1
vid = cv2.VideoCapture(video_path)
while vid.isOpened():
is_read, frame = vid.read()
if is_read:
if num % interval == 1:
file_name = '%08d' % num
cv2.imwrite(output_path + str(file_name) + '.jpg', frame)
cv2.waitKey(1)
num += 1
else:
break
第二步:数据集的标注。这里使用的是labelimg库,需要提前在自己的环境下安装,直接在pycharm的终端输入pip install labelimg即可(或者自己去搜索别的安装方法)。这里需要提前说明一点,在使用labelimg之前,需要创建好数据集储存的目录结构,如下所示:
| VOC2007(注意:这里是文件夹) (一级目录)
| | JPEGImages(注意:这里是文件夹) (二级目录)
| | Annotations(注意:这里是文件夹) (二级目录)
| | predefined_classes.txt(文本文件,用于存储类别,标注的时候非常方便) (二级目录)
目录结构创建好之后,把所有需要训练的图片放在JPEGImages文件夹下面,Annotations文件夹用于存放标注之后的文件,后续会说明,predefined_classes.txt文本文件用于存放所需识别的类别名,本文做了七个分类,所以文本文件如下图所示。为什么创建这样的目录结构呢?因为在yolov5的代码里面是这么写的,你这样创建之后,代码里面很多地方就不用再修改了。

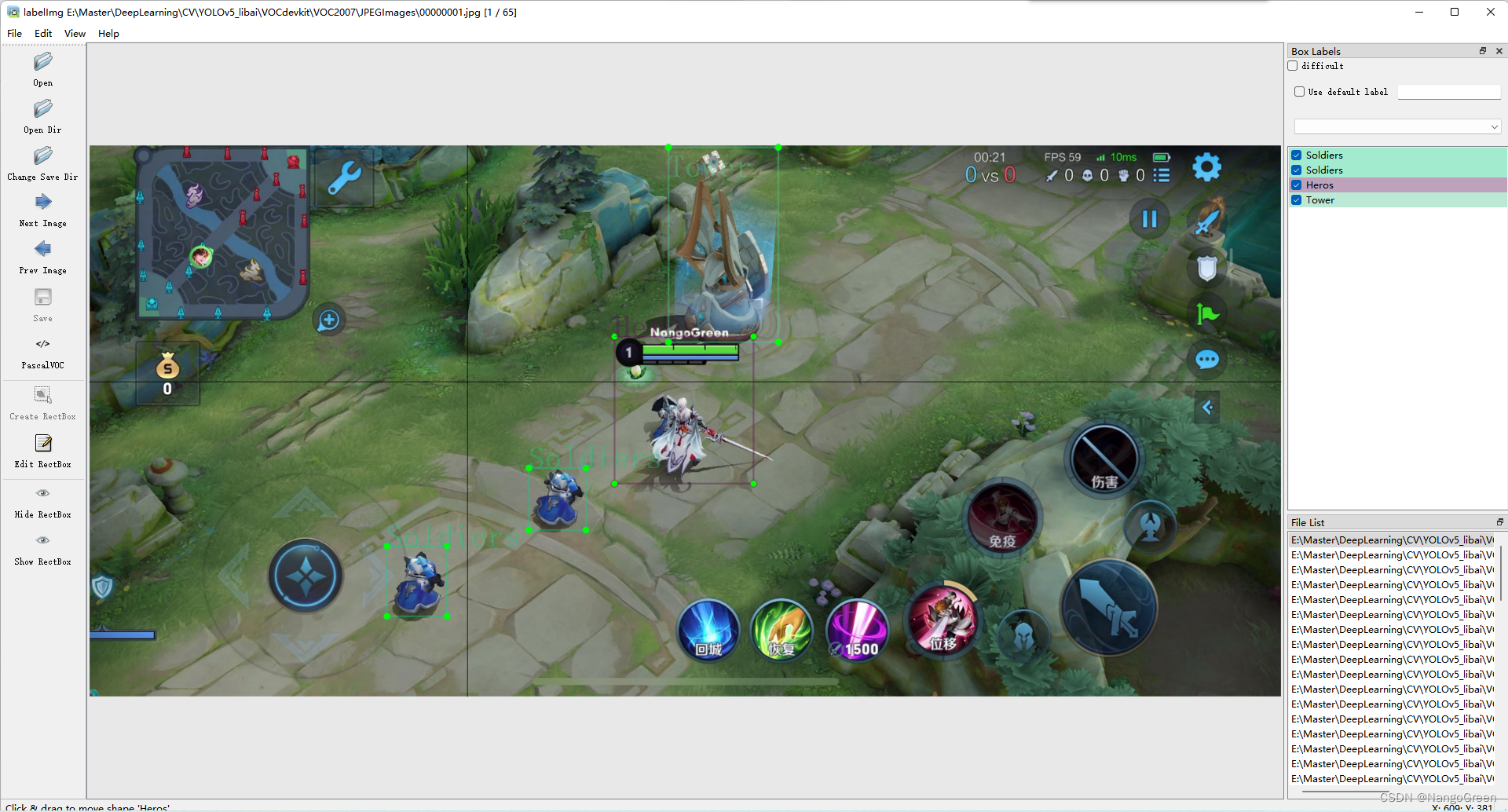
接下来开始标注,打开命令提示符,首先输入cd /d + VOC2007的绝对路径,如下图所示,切换到VOC2007目录。

再输入labelimg JPEGImages predefined_classes.txt,弹出的对话框为保存路径的位置,选择Annotations,打开软件界面之后,open dir按钮选择JPEGImages文件夹,最后labelimg的界面,如下图所示:,即可开始标注。标注完成之后,Annotations文件夹中会出现相应的xml文件。
 第三步:标注文件格式的转换以及训练集和验证集的划分。这里找了一个现成的代码,如下所示,只需要将代码中注释要修改的部分修改即可,根据自己的分类类别,修改classes的列表,TRAIN_TATIO = 80表示按照训练集:验证集=8:2划分数据集。这里注意一点,我们需要将VOC2007整个文件夹放在VOCdevkit文件夹下,也就是给VOC2007文件夹创建一个父文件夹,当然也可以不这么做,代码中相应的改过来就行。 第三步:标注文件格式的转换以及训练集和验证集的划分。这里找了一个现成的代码,如下所示,只需要将代码中注释要修改的部分修改即可,根据自己的分类类别,修改classes的列表,TRAIN_TATIO = 80表示按照训练集:验证集=8:2划分数据集。这里注意一点,我们需要将VOC2007整个文件夹放在VOCdevkit文件夹下,也就是给VOC2007文件夹创建一个父文件夹,当然也可以不这么做,代码中相应的改过来就行。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["Heros", "Soldiers", "Monster_Pig", "Red_Buff", "Monster_Wolf", "Bull_buff", "Tower"] # 修改
# classes=["ball"]
TRAIN_RATIO = 80 #TODO:修改
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
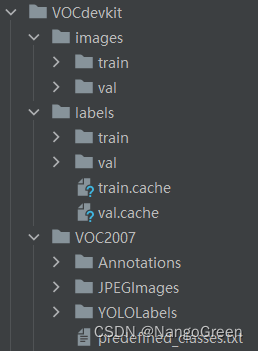
将代码放在VOCdevkit文件夹下 ,运行之后得到如下文件。相应的图片和标签以及训练集和验证集都划分好了,并且放在相应的目录下,后面yolov5训练的时候可以直接使用。
第四步:项目的克隆以及在自己的数据集上训练。 这一步包括下载yolov5以及修改相应的参数以及配置,是问题最多的一步,我也是卡了很久才解决,后面我会一一介绍。首先下载yolov5,这里给出github的地址,注意,一定要去下载源码,如果直接把别人下载的拿过来可能会报错,因为别人的可能针对他自己的数据集训练过,和你自己的数据集可能有的地方不匹配。

下载之后,将解压之后的所有文件复制到之前的VOCdevkit同级文件夹下,目录结构如图所示,其中runs为运行train之后才会有的文件夹。

接下来我们要下载预训练权重,因为我们用的是yolov5s,所以我们要去github上yolo的官网下载一个yolov5s.pt的文件(下图所示),这个表示的是yolo已经训练好的模型,我们自己的数据集就是在这个模型的基础上进行训练,相当于是一个迁移学习,下载好之后将他放在VOCdevkit的同级目录下。

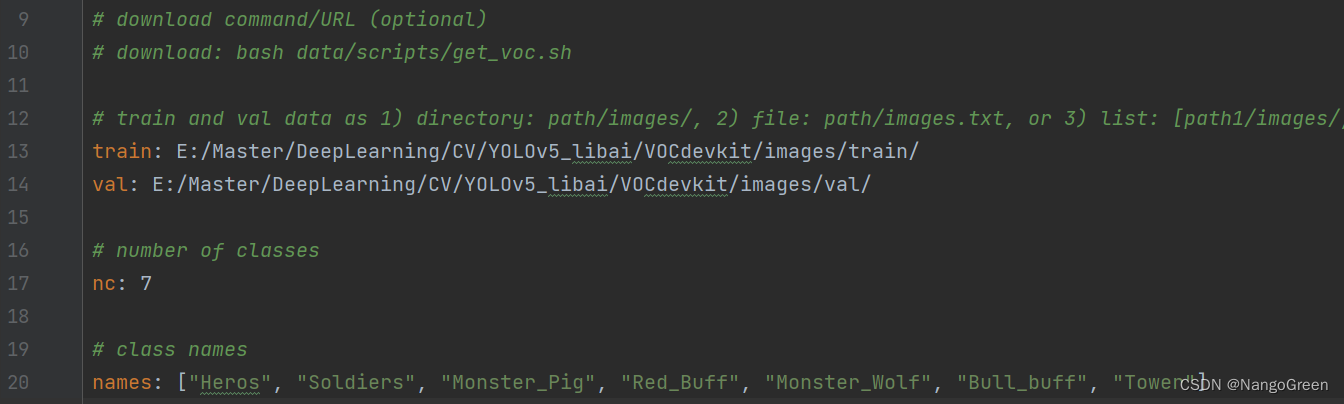
下面在文件夹中打开data文件夹,将voc.yaml复制一个副本,命名为自己需要的名字,这里我命名为libai.yaml,在pycharm中打开这个副本,把下图的第10行注释掉(这里我已经注释了),然后相应的训练集和验证集的路径改成我们上一步生成的train和val的绝对路径。nc改成自己所要分类的总类别数量,names列表中相应的类别名字要和之前predefined_classes.txt中的对应。
修改好之后,在文件夹中打开models文件夹,将yolov5s.yaml文件复制一份,重命名为自己的名字,这里我命名为yolov5s_libai.yaml,之后在pycharm中打开刚刚复制的文件,把nc改成需要分类的类别总数量,我这里nc=7。
之后在pycharm中打开train.py文件,找到程序入口,修改如下几行代码,就是把路径改成刚刚修改好的文件的路径,如图所示。

到这一步,就可以直接点击运行了,运行train.py,如果不出意外的话,相信你的代码就能正常跑起来了。但是一般情况下,如果不出意外的话往往就要出意外哈哈哈。这里列出我遇到的几个问题,如果大家也碰到了,及时避坑。
1.wandb的问题。wandb是一个可以把你的训练过程可视化的库,这里我下载安装了wandb库,但是运行的时候报错,一般情况下,对于新人来说,直接不用这个库即可。打开utils文件夹下wandb_logging文件夹下的wandb_utils.py文件,找到开头的这几行代码(下图所示),在后面加一行wandb = None就行。

2.GPU显存溢出。不同电脑CPU和GPU的配置不一样,所以这个代码所设置的参数不一定能够在你的电脑上正常运行,如果报这个错误的话,这时候就需要修改batch_size(批量大小)和workers(线程数)了,改小一点即可。如下所示,这里我改成了8和2。
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs')
parser.add_argument('--workers', type=int, default=2, help='maximum number of dataloader workers')
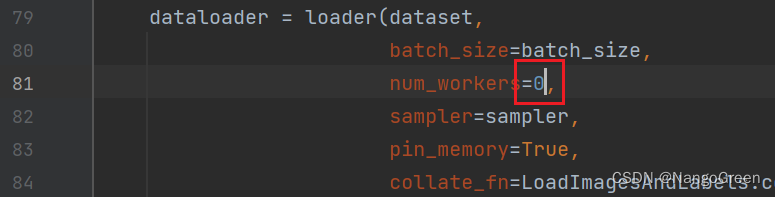
3.页面文件太小。打开utils文件夹下的datasets.py,把num_workers改成0即可。
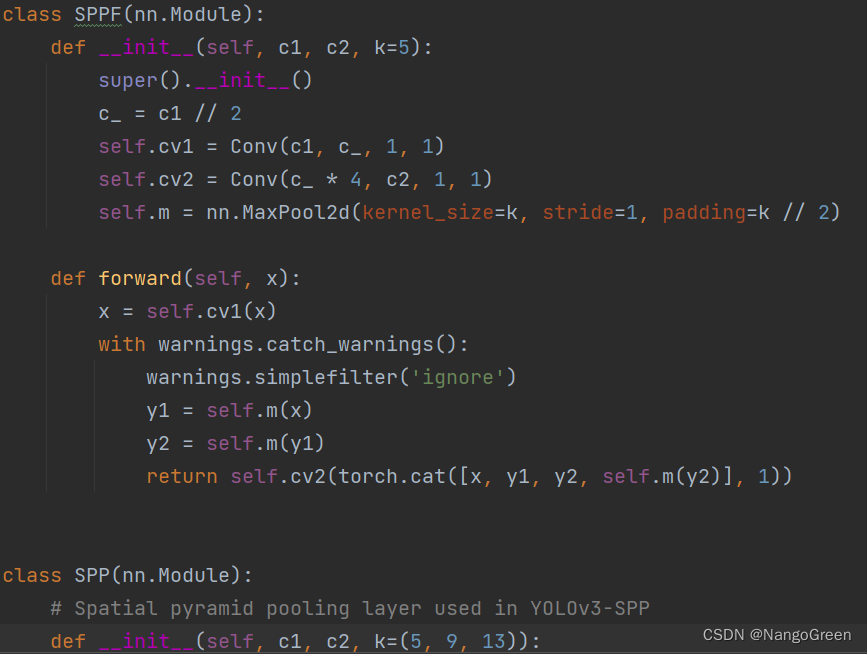
4.AttributeError: Can‘t get attribute ‘SPPF‘。找到models下的common.py文件,往下翻找到class SPP(nn.module):这一行,在上面插入如下代码:
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
插入后如图所示:
5.RuntimeError: result type Float can‘t be cast。修改utils文件夹中的loss.py中的两行代码。第一处:按住Ctrl+f,输入for i in range(self.nl),把anchors = self.anchors[i]替换成如下代码
anchors, shape = self.anchors[i], p[i].shape
第二处: 按住Ctrl+f,输入indices.append,把找到的这一行代码改成如下代码:
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
第五步:detect,检测。如果前面都没问题,那这一步一般不会出什么问题。选择一张图片或者一个视频,将它放在detect.py的同级目录下,打开detect.py文件,找到程序入口,修改如下两行代码。第一行是你训练之后的模型,,修改default的路径,里面有一个best和last,我们选择best,代表验证集上表现最好的模型。注意,runs的train里面,你每运行一次train.py,就会生成一个exp文件夹,我们要找到最新的exp下的best。第二行就是你要测试的图片文件或者视频文件,直接放在同级目录下,这里default相应的修改名称就行。
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp3/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='00000769.jpg', help='source') # file/folder, 0 for webcam
以上就是本项目的全部内容了,欢迎大家评论以及私信交流。
如果yolov5的依赖库不会安装的话,可以参考另一个大佬的博客,这里附上链接,这个大佬真的把整个过程写的非常详细!目标检测---教你利用yolov5训练自己的目标检测模型
|