| “伶荔”(Linly) 开源大规模中文语言模型 | 您所在的位置:网站首页 › 狗基础训练项目 › “伶荔”(Linly) 开源大规模中文语言模型 |
“伶荔”(Linly) 开源大规模中文语言模型
|
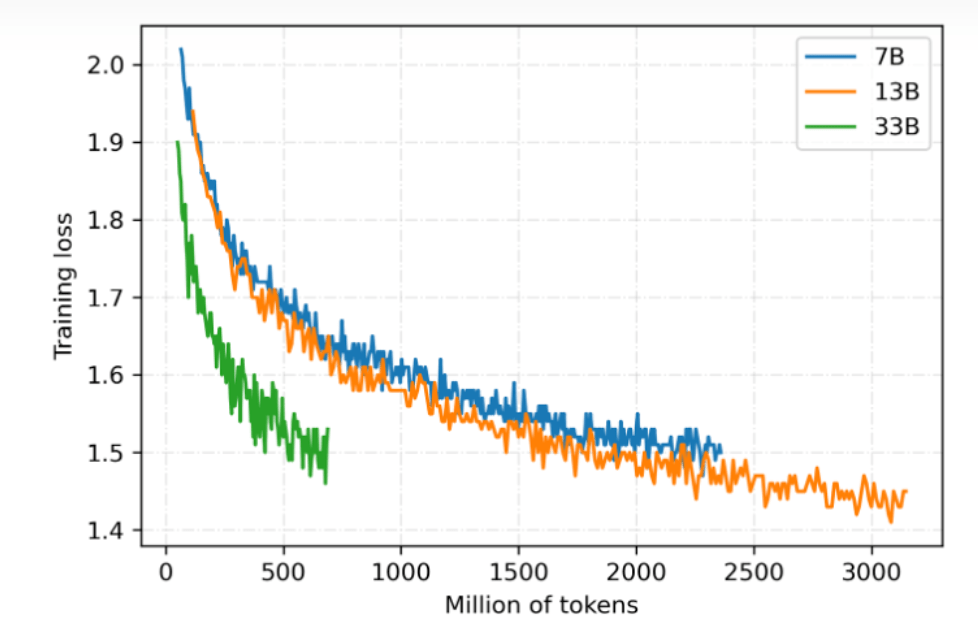
2. 全参数训练,覆盖多个模型量级 目前基于 LLaMA 的中文模型通常使用 LoRA 方法进行训练,LoRA 冻结预训练的模型参数,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数,来实现快速适配。虽然 LoRA 能够提升训练速度且降低设备要求,但性能上限低于全参数训练。为了使模型获得尽可能强的中文语言能力,该项目对所有参数量级都采用全参数训练,开销大约是 LoRA 的 3-5 倍。 伶荔语言模型利用 TencentPretrain 多模态预训练框架,集成 DeepSpeed ZeRO3 以 FP16 流水线并行训练。目前已开放 7B、13B、33B 模型权重,65B 模型正在训练中。模型仍在持续迭代,将定期更新,损失收敛情况如图所示:
3.可支持本地 CPU int4 推理、消费级 GPU 推理 大模型通常具有数百亿参数量,提高了使用门槛。为了让更多用户使用 Linly-ChatFlow 模型,开发团队在项目中集成了高可用模型量化推理方案,支持 int4 量化 CPU 推理可以在手机或者笔记本电脑上使用,int8 量化使用 CUDA 加速可以在消费级 GPU 推理 13B 模型。此外,项目中还集成了微服务部署,用户能够一键将模型部署成服务,方便二次开发。 未来工作 据透露,伶荔说系列模型目前仍处于欠拟合,正在持续训练中,未来 33B 和 65B 的版本或将带来更惊艳的性能。在另一方面,项目团队不仅公开了对话模型,还公开了中文基础模型和相应的训练代码与数据集,向社区提供了一套可复现的对话模型方案,目前也有团队基于其工作实现了金融、医学等领域的垂直领域对话模型。 在之后的工作,项目团队将继续对伶荔说系列模型进行改进,包括尝试人类反馈的强化学习 (RLHF)、适用于中文的字词结合 tokenizer、更高效的 GPU int3/int4 量化推理方法等等。伶荔项目还将针对虚拟人、医疗以及智能体场景陆续推出伶荔系列大模型。 相关链接: https://zhuanlan.zhihu.com/p/625786369返回搜狐,查看更多 |
【本文地址】