| ElasticSearch (ES)万字狂神学习笔记(超详细) | 您所在的位置:网站首页 › 狂神笔记md › ElasticSearch (ES)万字狂神学习笔记(超详细) |
ElasticSearch (ES)万字狂神学习笔记(超详细)
|
ElasticSearch (ES)万字狂神学习笔记(超详细)
ElasticSearch 学习笔记
全文概述
先聊一个人Doug Cutting
ElasticSearch概述
ES和solr的差别
注意:
工具说明
下载ES
数据展示工具head
下载node.js
安装和启动head
解决跨域问题
操作head
ELK工程师
**安装Kibana**
下载
解压和启动
访问IP:5601
汉化:
重启,查看效果:
测试的方法
ES核心概念
关系型数据库和es对比
**物理设计:**
**逻辑设计:**
**文档**(行)
**类型**(表)
**索引**(数据库)
物理设计:分片
倒排索引
elasticsearch的索引和Lucene的索引对比
ik中文分词器插件
安装ik分词器插件
使用ik分词器
ik_smart(最少切分)测试:
请求
结果
**ik_max_word(最细粒度划分)测试:**
请求
结果
向ik分词器增加自己的词库字典
新建自定义字典文档
添加新词至自定义字典文档
配置
重启ES 和 Kibana
再次访问Kibana查看效果
测试
结果
基础命令操作
Rest风格操作
启动软件
添加索引
请求
结果
在elasticsearch查看是否创建成功
数据类型
指定字段的类型(创建规则)
请求
结果
获取索引信息(使用规则)
请求
结果
查看默认的规则
请求
结果
其他命令
修改操作
1.直接再次put覆盖
请求
结果
2.使用update
请求
结果
删除操作
请求
结果
关于文档的基本操作
1.添加数据 PUT
2.获取数据 GET
请求
结果
3.**简单的条件查询**
请求
结果
说明:
4.复杂查询
条件筛选
请求
结果
结果过滤
请求
结果
排序
请求
结果
**分页查询**
请求
结果
布尔值查询(与、或、非)
**过滤操作**(想查询区间时用)
请求
结果
**匹配条件查询**
请求
结果
**精确查询**
注意两个类型:
精确查询多个值
**高亮查询**
请求
结果
自定义高亮条件
请求
结果
参考链接
ElasticSearch 学习笔记
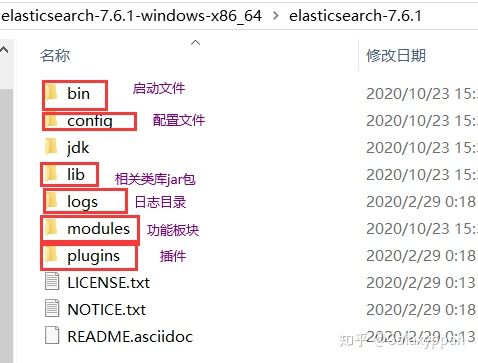
ElasticSearch adj. 有弹性的;灵活的;易伸缩的 全文概述ElasticSearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。它用于全文搜索、结构化搜索、分析以及将这三者混合使用: 总之,可以对搜索关键字高亮显示,可以对搜索结果纠错,提供建议。并且ELK是大数据必会的技术。 本人根据b站狂神说视频“【狂神说Java】ElasticSearch7.6.x最新完整教程通俗易懂”学习ES,参考网上已有笔记,对已有笔记错误修订和笔记整合,具体链接在文末。整理不易,望君珍惜。 先聊一个人Doug CuttingDoug Cutting 是一位美国工程师,迷上了搜错引擎。他做了一个用于文本搜索的函数库,命名为Lucene. Lucene 是用java写的,目标是为各种中小型应用软件加入全文搜索功能。**Lucene是一套信息检索工具包,**并不包含搜索引擎系统,它包含了索引结构、读写索引工具、相关性工具、排序等功能。因此在使用Lucenen时仍需关注搜索引擎系统,例如数据获取、解析、分词等方面的东西。 该项目早期被发布在Doug Cutting的个人网站,后来成为了Apache软件基金会jakarta项目的一个子项目。后来在Lucene的基础上开发了一款可以代替当时的主流搜索的开源搜索引擎,命名为Nutch. Nutch 是一个建立在Lucene核心之上的网页搜索应用程序,它在Lucene的基础上加了爬虫和一些网页相关的功能,目的就是从一个简单的站内检索推广到全球网络上的搜索上。 随着时间的推移,作为互联网搜索引擎,都面临对象“体积”不断增大的问题。需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。 在2004年,Doug Cutting实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)。后来他加入了雅虎,将NDFS和MapReduce进行了改造,并重新命名为Hadoop(NDFS也改名为HDFS,Hadoop Distributed File System). 这就是大名鼎鼎的大数据框架系统–Hadoop的由来,而Doug Cutting则被人称为Hadoop之父。 ElasticSearch概述ElasticSearch,简称es,es是一个开源的高拓展的分布式全文检索引擎,它可以近乎实施的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用java开发并使用Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。 谁在使用 维基百科,类似百度百科,全文检索,高亮,搜索推荐 国外新闻网站,类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据,数据分析。。。 Stack Overflow国外的程序异常讨论论坛 GitHub(开源代码管理),搜索上千亿行代码 电商网站,检索商品 日志数据分析,logstash采集日志,ES进行复杂的数据分析,ELK技术(elasticsearch+logstash+kibana) 商品价格监控网站 商业智能系统 站内搜索 ES和solr的差别ElasticSearch简介 ElasticSearch是一个实施分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。它用于全文搜索、结构化搜索、分析以及将这三者混合使用: 维基百科使用es提供全文搜索并高亮关键字,以及输入实施搜索和搜索纠错等搜索建议功能;英国公报使用es结合用户日志和社交网络数据提供给他们的编辑以实施的反馈,以便了解龚总对新发表的文章的回应。。。 es是一个基于Apache Lucene™的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好、功能最全的搜索引擎库。想要使用它,必须使用java来作为开发语言并将其直接继承到你的应用中。 solr简介 Solr是Apache下的一个顶级开源项目,采用java开发,是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展、并对索引、搜索性能进行了优化。它可以独立运行,是一个独立的企业及搜索应用服务器,它对外提供类似于web-service的API接口。用户可以通过http请求,像搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。 两者比较 当单纯的对已有数据进行搜索时,Solr更快 当实时建立索引是,Solr会产生io阻塞,查询性能较差,ElasticSearch具有明显的优势 随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化总结 es基本是开箱即用,非常简单。而solr会有点复杂。 Solr利用Zookeeper进行分布式管理,而elasticsearch自身带有分布式协调管理功能 solr支持更多格式的数据,比如json xml csv。而es只支持json文件格式 solr官方提供的功能更多,而elasticsearch更注重核心功能,高级功能由第三方插件提供 solr查询快,但更新索引时慢,用于电商等查询多的应用 es建立索引宽,即实时性查询快,用于facebook新浪等搜索 solr较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而elasticsearch相对开发维护者较少,更新太快,学习使用成本较高 注意:本教程使用的版本是7.6.1 需要注意所有es和es相关工具都要版本对应 工具说明elasticsearch-7.6.1:ES安装包 elasticsearch-head-master:用于数据展示 kibana-7.6.1-windows-x86_64:用于操作命令 下载ES在官网下载安装包 注:安装ElasticSearch之前必须保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败。 下载windows版本,解压压缩包,打开,看到如下目录:
打开config文件夹:
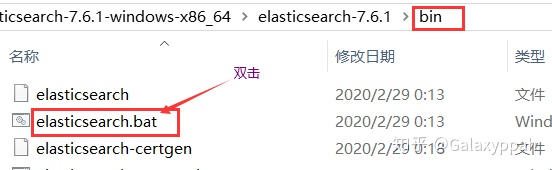
双击bin目录下的elasticsearch.bat启动
点击后:
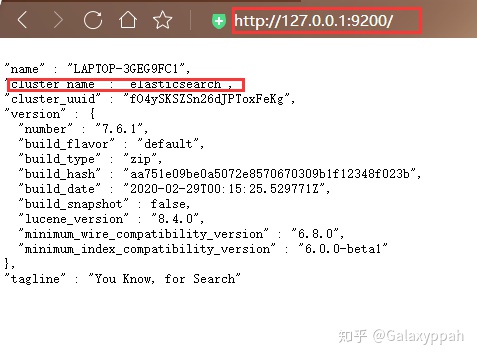
在浏览器访问127.0.0.1:9200,若得到以下信息则安装成功:
由于是命令行操作,不方便,所以需要安装图形化界面 数据展示工具headhead只用来看数据,不用来干别的 安装es的图形化界面插件 下载node.js下载nodejs:https://nodejs.org/en/ LTS:长期支持版本 安装:下一步下一步 。。。 查看版本:
下载elasticsearch-head-master.zip: 解压后安装依赖,一定要跳转到该解压文件夹下输入该命令:
访问测试:
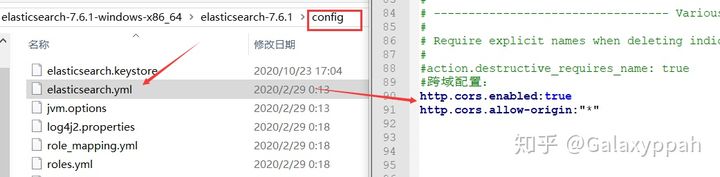
由于ES进程和客户端进程端口号不同,存在跨域问题,所以需要在ES的配置文件中配置下解决跨域问题:
启动es,使用head工具进行连接测试:
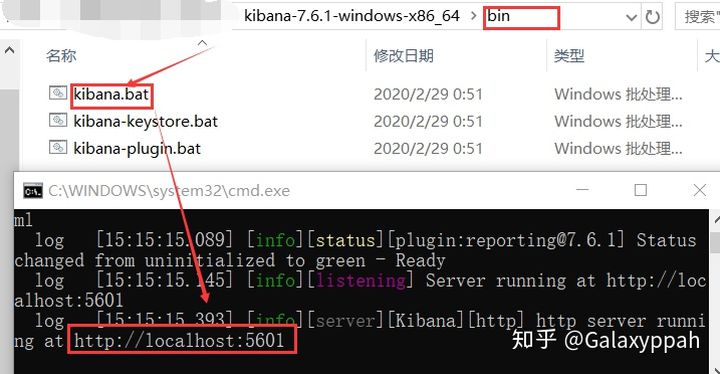
初学把ES当成一个数据库就行了 ES中 普通数据库中 数据库 索引 数据库 表 文档(用的不多了) 表 类型 type ELK工程师ELK是ElasticSearch 、 Logstash、Kibana三大开源框架首字母大写简称。市面上也称为Elastic Stack。Lostash是ELK的中央数据流,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地。Kibana可以将elastic的数据通过友好的页面展示出来,提供实时分析的功能。 市面上很多开发只要提到ELK能够一直说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其他任何数据分析和手机的场景,日志分析和收集知识更具有代表性。并非唯一性。 安装KibanaKibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。使用Kibana,可以通过各种如表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础构架,几分钟内就可以完成Kibana安装并启动Elasricsearch索引检测。 下载下载:https://mirrors.huaweicloud.com/kibana/?C=N&O=D 需要和es版本对应 解压和启动进入bin目录,启动服务
中文包在:kibana-7.6.1-windows-x86_64\x-pack\plugins\translations\translations
ElasticSearch是面向文档型的数据库,一条数据在这里就是一个文档。比如: { "name" : "John", "sex" : "Male", "age" : 25, "birthDate": "1990/05/01", "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] }在MySql中这样的数据存储容易想到建立一张User表,其中有一些字段,而在es中就是一个文档,文档会属于一个User类型,各种各样的类型存储于一个索引中。下表是关系型数据库和es的疏于对照表: elasticsearch是面向文档,关系型数据库和elasticsearch客观的对比!一切都是json 关系型数据库和es对比 关系型数据库 ElasticSearch 数据库 索引 表 type 行 document 列 fieldes中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档又包含多个字段(列)。 物理设计:es在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器中转移。 逻辑设计:一个索引类型,包含多个文档,当我们索引一篇文档时,可以通过这样的顺序找到他: 索引-》类型-》文档id(该id实际是个字符串),通过这个组合我们就能索引到某个具体的文档。 文档(行)es是面向文档的,意味着索引和搜索数据的最小单位是文档,es中,文档有几个重要的属性: 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value 可以是层次性的,一个文档中包含自文档,复杂的逻辑实体就是这么来的 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在es中,对于字段是非常灵活的。有时候,我们可以忽略字段,或者动态的添加一个新的字段尽管我们可以随意的添加或忽略某个字段,但是,每个字段的类型非常重要。因为es会保存字段和类型之间的映射以及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在es中,类型有时候也称为映射类型。 类型(表)类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为string类型.我们说文档是无模式的,他们不需要拥有映射中所定义的所有字段,当新增加一个字段时,es会自动的将新字段加入映射,但是这个字段不确定他是什么类型,所以最安全的方式是提前定义好所需要的映射。 索引(数据库)就是数据库! 索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。 物理设计:分片节点和分片如何工作 一个集群至少有一 个节点,而一个节点就是一个elasricsearch进程 ,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片( primary shard ,又称主分片)构成的,每一个主分片会有-一个副本( replica shard ,又称复制分片)
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同-个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上, 一个分片是一个Lucene索引, -一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼? 倒排索引elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文 档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。 例如,现在有两个文档,每个文档包含如下内容: Study every day, good good up to forever # 文档1包含的内容 To forever, study every day,good good up # 文档2包含的内容为创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens) ,然后创建一一个包含所有不重 复的词条的排序列表,然后列出每个词条出现在哪个文档: term doc_1 doc_2 Study √ x To x x every √ √ forever √ √ day √ √ study x √ good √ √ every √ √ to √ x up √ √现在,我们试图搜索 to forever,只需要查看包含每个词条的文档 term doc_1 doc_2 to √ x forever √ √ total 2 1两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。 再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构: 博客文章(原始数据) 博客文章(原始数据) 索引列表(倒排索引) 索引列表(倒排索引) 博客文章ID 标签 标签 博客文章ID 1 python python 1,2,3 2 python linux 3,4 3 linux,python 4 linux如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率! elasticsearch的索引和Lucene的索引对比在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。在elasticsearch中 ,索引被分为多个分片,每份分片是-个Lucene的索引。所以一个elasticsearch索引是由多 个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。 接下来的一切操作都在kibana中Dev Tools下的Console里完成。基础操作! ik中文分词器插件什么是IK分词器 ? 分词:即把一-段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神”会被分为"我",“爱”,“狂”,“神” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。 如果要使用中文,建议使用ik分词器! IK提供了两个分词算法: ik_ smart和ik_ max_ word ,其中ik_ smart为最少切分, ik_ max_ _word为最细粒度划分!一会我们测试! 什么是IK分词器: 把一句话分词 如果使用中文:推荐IK分词器 两个分词算法:ik_smart(最少切分),ik_max_word(最细粒度划分) 安装ik分词器插件下载链接 解压放入到es对应的plugins下即可 解压后的状态: 重启观察ES,发现ik插件被加载了 也可以通过bin目录下elasticsearch-plugin list 查看已经加载的插件 感觉像大学时《编译原理》课程里面的词法分析器 ik_smart(最少切分)测试:
会把多种词组划分更细 |



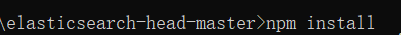















【本文地址】