| ChatGPT与Transformer模型详解 | 您所在的位置:网站首页 › 物理q表示什么 › ChatGPT与Transformer模型详解 |
ChatGPT与Transformer模型详解
|
ChatGPT详解详解GPT字母中的缩写 GPT,全称Generative Pre-trained Transformer ,中文名可译作生成式预训练Transformer。 对三个英文进行解读: Generative生成式。GPT是一种单向的语言模型,也叫自回归模型,既通过前面的文本来预测后面的词。训练时以预测能力为主,只根据前文的信息来生成后文。与之对比的还有以谷歌的Bert为代表的双向语言模型,进行文本预测时会结合前文后文信息,以"完形填空"的方式进行文本预测。 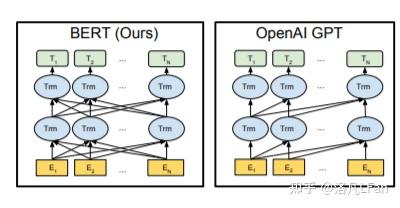 Pre-trained:预训练让模型学习到一些通用的特征和知识。预训练的Bert通常是将训练好的参数作为上游模型提供给下游任务进行微调,而GPT特别是以GPT3超大规模参数的模型则强调Few-shot(少样本学习,给出N个上下文和完成结果的示例,然后给出一个上下文的最终示例,模型需要提供完成结果), Zero-shot(零样本学习,不需要给出示例,直接让语言模型执行相应任务)能力,无需下游微调(Fine-tuning)即可直接使用(如GPT-3,无需进行额外参数调整即可满足各种任务需求)。 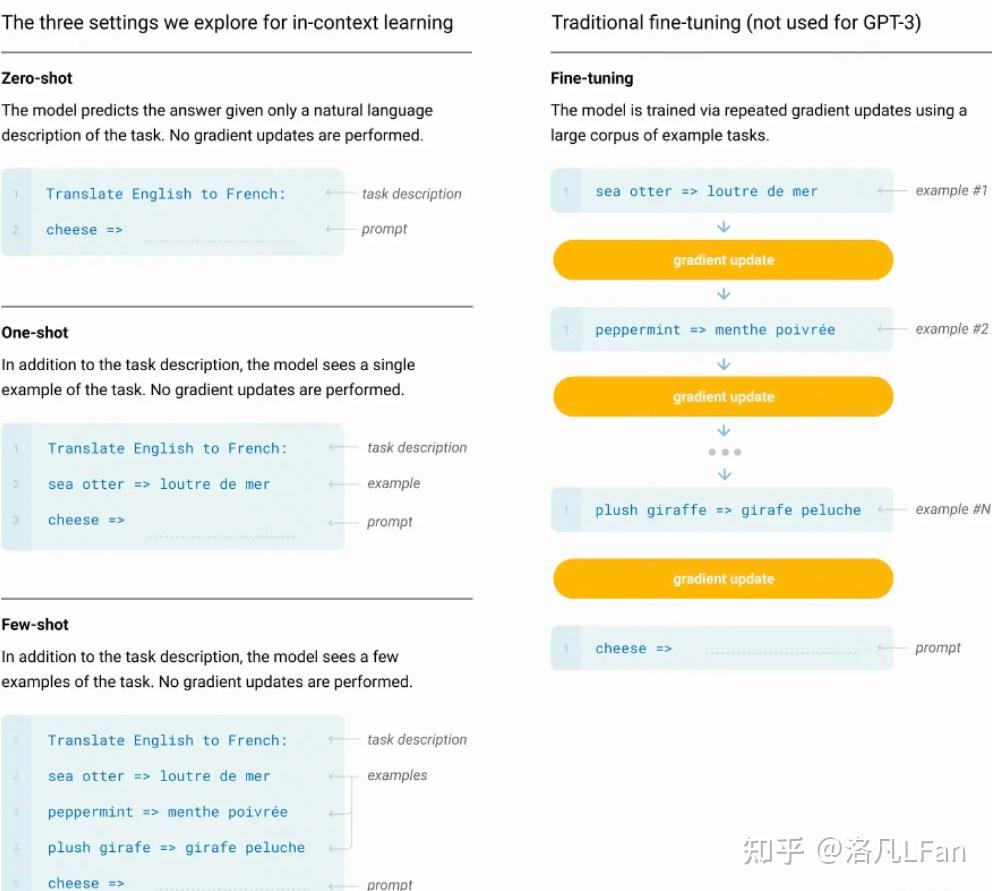 One-shot,单样本学习,只给出一个示例,模型即可以完成任务 One-shot,单样本学习,只给出一个示例,模型即可以完成任务Transformer:Transformer是一种基于编码器-解码器结构的神经网络模型,最初由Google在2017年提出,用于自然语言处理(NLP)领域。Transformer是一种基于自注意力机制(Self-attention Mechanism)的模型,可以在输入序列中进行全局信息的交互和计算,从而获得比传统循环神经网络更好的长距离依赖建模能力。后文会介绍Transfomer以及自注意力相关机制。 基于生成式的语言模型什么是生成式?就是生成文本时,通过前面的单词,来预测后面生成的内容。 最常见的生成式可以追溯到日常使用搜索引擎中的下拉提示框  而现如今的文本生成已经实现了通过文字描述的大部分需求(但其援引的文献真实性有待考证,以及个人能否将该需求描述出来)  ChatGPT的十一大功能及应用场景 ChatGPT的十一大功能及应用场景文字应当是我们获取知识最高效、记忆最长久的手段,相较于一闪而过的视频和音频。那么,作为文字生成式的AI,他的使用前景是非常广阔的。 已知的功能及应用场景: 1、写报告:报告开头、报告总结、研究报告、提出反方观点 2、资料整理:摘录重点、采集资料、内容总结 3、履历与自传:精简经历、定制化履历 4、程序开发:解BUG、写代码、写测试、代码调优 5、知识学习:简易教学、深度教学、教学和测验、概念说明 6、英文学习:翻译、英文语法校验、作文修改 7、工作生产力:回应email 8、写作帮手:撰写标题、撰写大纲、撰写文章 9、日常生活:提供食谱、活动企划清单、提供点子、旅游计划、食谱生成 10、有趣好玩:写歌词、故事、写RAP 11、角色扮演:担任导游、面试官、综合情境 Transformer模型详解2017年6月,谷歌大脑团队(Google Brain)在神经信息处理系统大会(NeurIPS,该会议为机器学习与人工智能领域的顶级学术会议)发表了一篇名为“Attention is all you need”《自我注意力是你所需要的全部》的论文。作者在文中首次提出了基于自我注意力机制(Self-attention)的变换器(Transformer)模型,并首次将其用于理解人类的语言,即自然语言处理。该模型替代了以往使用RNN(循环神经网络,Recurrent Neural Network)来处理自然语言问题带来的前后文较长时产生遗忘、严重依赖顺序计算而导致并行计算效率不高等问题。 而该Transformer模型的优点,就在于能够同时并行进行数据计算和模型训练,训练时长更短,并且训练得出的模型可用语法解释,也就是模型具有可解释性。 Transformer模型结构Transformer由若干个编码器和解码器组成,如下图所示:  可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。 可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。我们将Encoder和Decoder拆开,可以看到完整的结构,如下图所示: 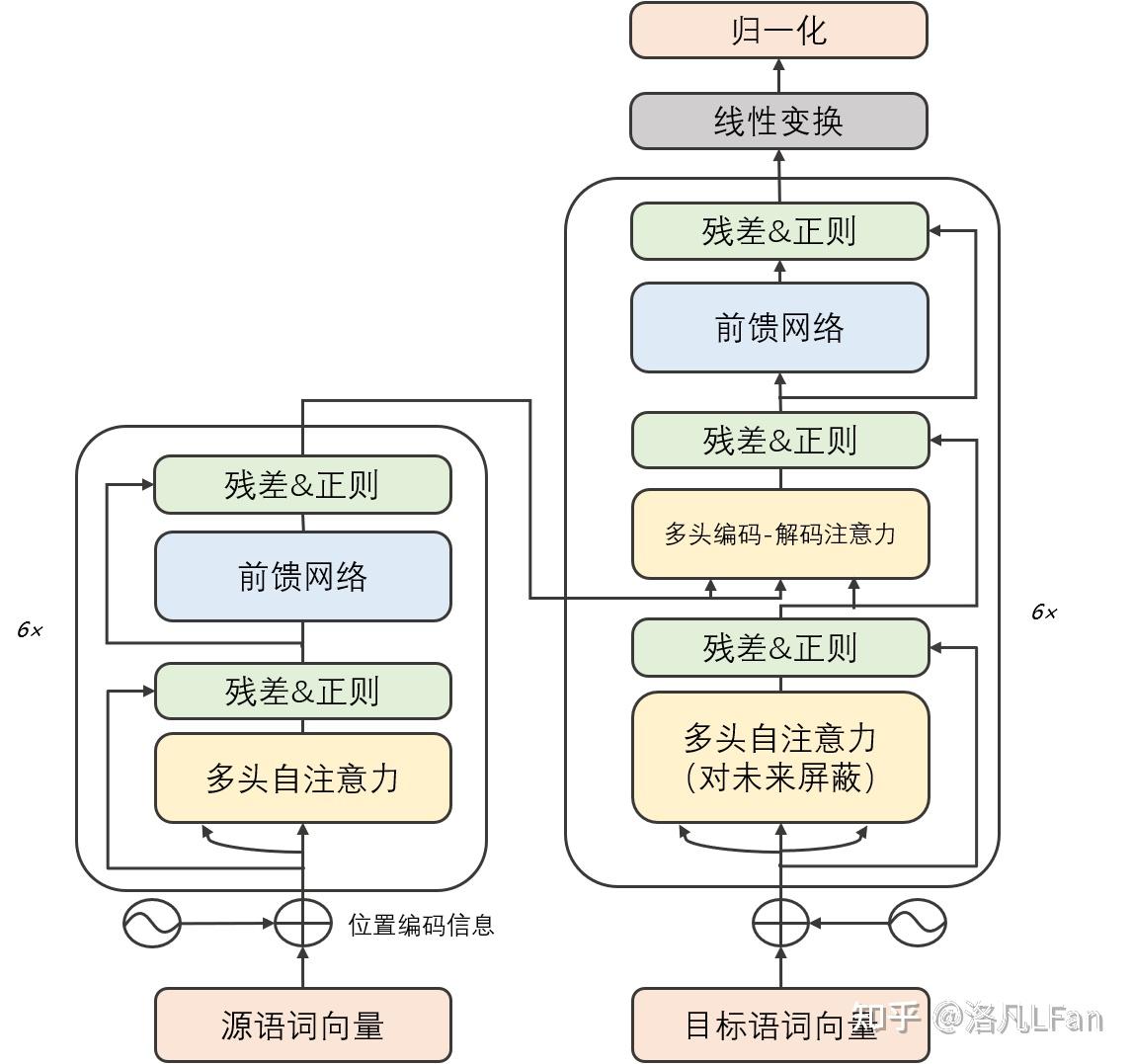 Transformer 的工作流程 Transformer 的工作流程第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding 和单词位置的 Embedding 相加得到。  Transformer 的输入表示 Transformer 的输入表示第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用 X_{n\times d} 表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。  Transformer Encoder 编码句子信息 Transformer Encoder 编码句子信息第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。  Transofrmer Decoder 预测 Transofrmer Decoder 预测上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 "",预测第一个单词 "I";然后输入翻译开始符 "" 和单词 "I",预测单词 "have",以此类推。 这里面向的是普适大众群体,就不细谈各个部分的细节。 如果有兴趣深入了解其数学公式及算法实现,可以参考Transformer 模型详解 如果还有更进一步兴趣,进行代码复现,可以参考Transformer注释及实现The Annotated Transformer 自我注意力机制(Self-Attention)在讲Self-Attention之前,先讲广义上的Attention机制。 Attention机制可以用一句话概括就是,分配权重系数。 Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射。  Attention Value= QK^{T}V 如果序列中每一个元素都以(K,V)形式存储,那么Attention则通过计算Q和K的相似度来完成寻址。Q和K计算出来的相似度反映了取出来的V值的重要程度,即权重,然后加权求和就得到了Attention值。 Attention的精髓便在于,某一个输出并不需要所有encoder信息,而是只需要部分信息。 举个例子来说:假如我们正在做机器翻译,将“I am a student”翻译成中文“我是一个学生”。在输出“学生”时,我们用到了“我”“是”“一个”以及encoder的输出。但事实上,我们或许并不需要“I am a ”这些无关紧要的信息,而仅仅只需要“student”这个词的信息就可以输出“学生”(或者说“I am a”这些信息没有“student”重要)。这个时候就需要用到attention机制来分别为“I”、“am”、“a”、“student”赋一个权值了。例如分别给“I am a”赋值为0.1,给“student”赋值剩下的0.7,显然这时student的重要性就体现出来了。 而Self Attention机制在KQV模型中的特殊点在于Q=K=V,这也是为什么取名Self Attention,因为其是文本和文本自己求相似度再和文本本身相乘计算得来。 Attention是输入对输出的权重,而Self-Attention则是自己对自己的权重,之所以这样做,是为了充分考虑句子之间不同词语之间的语义及语法联系。例如“I am a student”分别是对am的权重和对student的权重。用白话来讲就是,当输入一个句子时,里面的每个词都要和该句子中的所有词进行Attention计算。 如果想要了解详细的数学公式的原理实现,可以参考Tensor2Tensor Transformers New Deep Models for NLP 参考Attention Is All You NeedTransformer 模型详解The Annotated TransformerTensor2Tensor Transformers New Deep Models for NLP |
【本文地址】