| 双重差分及三重差分(倍差法)汇总 | 您所在的位置:网站首页 › 牛仔七分裤穿搭图片大全女 › 双重差分及三重差分(倍差法)汇总 |
双重差分及三重差分(倍差法)汇总
|
命令介绍:diff runs several difference in differences (diff-in-diff) treatment effect estimations of a given outcome variable from a pooled baseline and follow up dataset: Single Diff-in-Diff, Diff-in-Diff accounting for covariates, Kernel Propensity Score Matching diff-in-diff, and the Quantile Diff-in-Diff. diff is also suitable for estimating repeated cross sections diff-in-diff (including the kernel option) and the triple difference-in-differences analysis. The command requests the specification of the outcome variable (outcome_var) and allows the use of weights, except for some options. The initial required option is the period(varname), which contains a dummy variable indicating the baseline (period==0) and a follow-up (period==1) periods. Additionally, the option treated(varname), is need, containing a dummy variable with the indicator of the control (treated==0) and treated (treated==1) individuals. For the individual , this initial setting performs the following linear regression:
模型必选项介绍: period(varname) Indicates the binary period variable (0: before; 1: after). Note: if your data contains a periodical frequency (monthly, quarterly, yearly, etc.), it is suggested to specify option period(varname) and include a binary variable for each frequency in option cov(varlist). treated(varname) Indicates the binary treatment variable (0: controls; 1:treated). 可选项介绍: cov(varlist),协变量,加上 kernel可以估计倾向得分 kernel, 执行双重差分倾向得分匹配 id(varname),kernel选项要求使用 bw(#) ,核函数的带宽,默认是0.06 ktype(kernel),核函数的类型. The types are epanechnikov (the default), gaussian, biweight, uniform and tricube. rcs Indicates that the kernel is set for repeated cross section. This option does not require option id(varname). Option rcs strongly assumes that covariates in cov(varlist) do not vary over time. qdid(quantile),执行分位数双重差分Performs the Quantile Difference in Differences estimation at the specified quantile from 0.1 to 0.9 (quantile 0.5 performs the QDID at the medeian). You may combine this option with kernel and cov. qdid does not support weights nor robust standard errors. This option uses [R] qreg and [R] bsqreg for bootstrapped standard errors pscore(varname) Supplied Propensity Score.提供倾向得分 logit,进行倾向得分计算,默认probit回归Specifies logit estimation of the Propensity Score. The default is Probit. support Performs diff on the common support of the propensity score given the option kernel. addcov(varlist) Indicates additional covariates in addition to those specified in the estimation of the propensity score. Also use this option to specify time fixed-effects in the case of multiple time-frequency data (e.g. monthly, yearly, quarterly, etc.). ddd(varname),三重差分 Additional category for triple difference estimation. treated(varname) is deemed as the first category and ddd(varname) the second category. This option is not compatible with options kernel, test or qdid(quantile). SE/Robust cluster(varname) Calculates clustered Std. Errors by varname.计算聚类标准误。 robust Calculates robust Std. Errors.稳健标准误 bs performs a Bootstrap estimation of coefficients and standard errors. reps(int) Specifies the number of repetitions when the bs is selected. The default are 50 repetitions. Balancing test 平衡检验 test Performs a balancing t-test of the difference in the means of the covariates between the control and treated groups in period == 0. The option test combined with kernel performs the balancing t-test with the weighted covariates. See [R] ttest Reporting report Displays the inference of the included covariates or the estimation of the Propensity Score when option kernel is specified. nostar Removes the inference stars from the p-values. 三、案例介绍 案例数据介绍:cardkrueger1994 背景介绍:diff提供了一个来自Card和Krueger(1994)的数据集的例子。它可以 通过运行net get diff下载到工作目录,然后使用cardkrueger1994,clear。在这个案例中,作者研究了新泽西州最低工资的提高对快餐业就业水平的影响。他们比较了这一组餐馆员工人数的变化与相邻的宾夕法尼亚州的对照组。他们在1992年2月收集了基线数据,并在11月进行了随访。 数据集中的变量描述如下:
在820次观察中,实验组和对照组的个体数分别为331和79。结果变量为fte,而一些协变量被定义为虚拟变量,表示观察是否属于给定的快餐店。基本统计数据如下: 1、DID with no covariates不带协变量的估计 diff fte, t(treated) p(t)
bootstrapped 稳健标准误
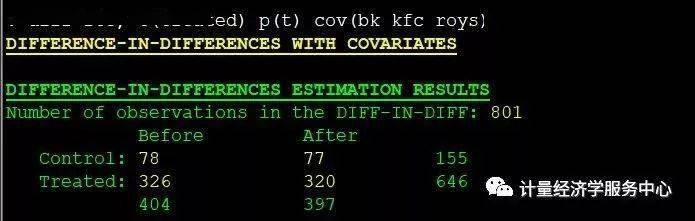
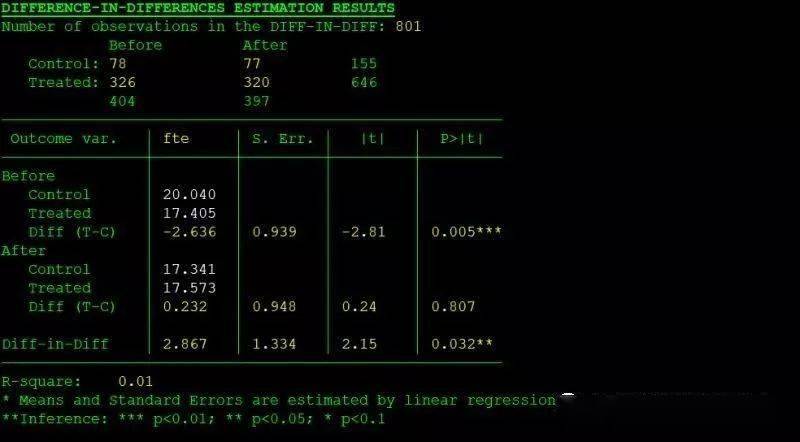
2、DID with covariates带协变量的估计 diff fte, t(treated) p(t) cov(bk kfc roys) diff fte, t(treated) p(t) cov(bk kfc roys) report diff fte, t(treated) p(t) cov(bk kfc roys) report bs
3、Kernel Propensity Score Diff-in-Diff diff fte, t(treated) p(t) cov(bk kfc roys) kernel rcs diff fte, t(treated) p(t) cov(bk kfc roys) kernel rcs support diff fte, t(treated) p(t) cov(bk kfc roys) kernel rcs support addcov(wendys) diff fte, t(treated) p(t) kernel rcs ktype(gaussian) pscore(_ps) diff fte, t(treated) p(t) cov(bk kfc roys) kernel rcs support addcov(wendys) bs reps(50)
4、 Quantile Diff-in-Diff 分位数双重差分法 diff fte, t(treated) p(t) qdid(0.25) diff fte, t(treated) p(t) qdid(0.50) diff fte, t(treated) p(t) qdid(0.75) diff fte, t(treated) p(t) qdid(0.50) cov(bk kfc roys) diff fte, t(treated) p(t) qdid(0.50) cov(bk kfc roys) kernel id(id)diff fte, t(treated) p(t) qdid(0.50) cov(bk kfc roys) kernel rcs
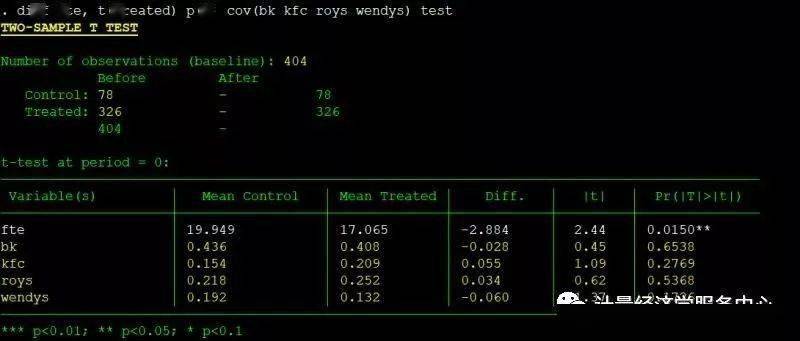
5、Balancing test of covariates.包含协变量的控制组与实验组之间差异检验 diff fte, t(treated) p(t) cov(bk kfc roys wendys) test diff fte, t(treated) p(t) cov(bk kfc roys wendys) test id(id) kernel diff fte, t(treated) p(t) cov(bk kfc roys wendys) test kernel rcs
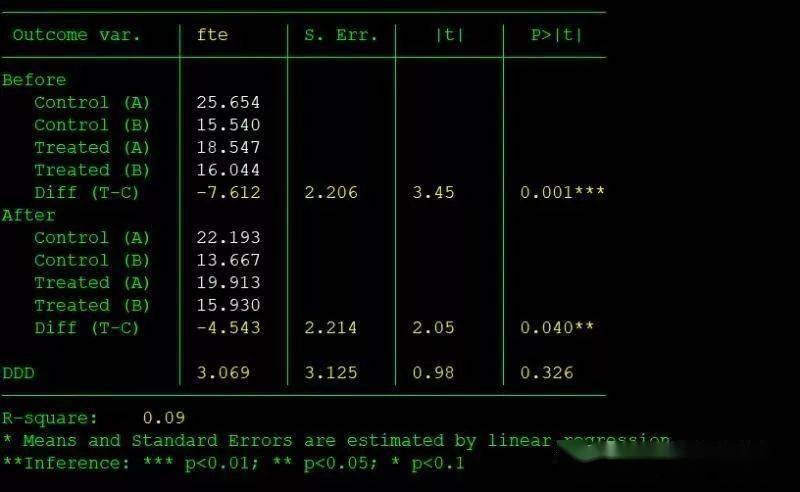
6. Triple differences (consider bk is a second treatment category). 三重差分法 diff fte, t(treated) p(t) ddd(bk)
|











 返回搜狐,查看更多
返回搜狐,查看更多【本文地址】