| 基于新浪微博评论的情感分析 | 您所在的位置:网站首页 › 爱情公寓csgo图片高清无水印 › 基于新浪微博评论的情感分析 |
基于新浪微博评论的情感分析
|
目录
摘 要ABSTRACT第1章 绪论1.1 研究背景1.2 国内外研究现状1.3 研究的目的和意义1.4全文组织结构
第2章 相关技术综述2.1 文本挖掘技术2.2 SVM2.3 Python
第3章 基于SVM和情感词典的情感分析方法3.1 支持向量机3.2基于情感词典的情感分析方法3.3情感词典构建3.4 SVM算法3.5 评价指标
第4章 实验与分析4.1设计内容4.1.1数据4.1.2 设计流程图
4.2 实现过程4.2.1获取原数据4.2.2 数据处理4.2.3 文本预处理4.2.4 文本特征提取4.2.5 word2vec模型4.2.6 训练SVM模型4.2.7 情感判断
第5章 总结与展望
摘 要
如今的网络时代带动了微博娱乐平台的发展,对微博评价进行情感分析不仅可以通过新浪微博评论的情感分析,完成把握社会人群的观点态度,提高管理部门舆情监控。 通过对如今情感分析技术的分析,为了提高微博评价分析的准确性,可以使用支持向量机(Support Vector Machine,SVM)对微博评论进行分析。在此过程中,既积累了大量的文本分类和文本分析的经验,对分析结果的准确性也能够逐渐提高,达到对微博评价分析的重要意义。 引入表达的文本情感分析算法用于实现微博文本的情感分析。受用户习惯的影响,微博文本通常由短文本和表情符号组成。由于表情符号所表达的情绪通常简单明了,而且远不如汉字丰富,因此它们通常可以更准确地表达用户情绪。 表情符号还用作情感参考值,这已在文本情感判定的准确率上进行了一些改进。 关键词: 微博评论;文本分类;情感分析;SVM ABSTRACTIn the booming online environment of e-commerce, subjective review texts about Today’s Internet era has driven the development of Weibo entertainment platforms. Sentiment analysis of Weibo evaluation can not only achieve sentiment analysis of Sina Weibo reviews, but also grasp the opinions and attitudes of social groups and improve public opinion monitoring of management departments. Through the analysis of today’s sentiment analysis technology, in order to improve the accuracy of Weibo evaluation analysis, Support Vector Machine (SVM) can be used to analyze Weibo reviews. In this process, not only has accumulated a lot of experience in text classification and text analysis, but also the accuracy of the analysis results can be gradually improved, reaching the significance of evaluation and analysis on Weibo. The text sentiment analysis algorithm that introduces expressions is used to realize the sentiment analysis of microblog texts. Affected by user habits, Weibo text is generally composed of short text and emoticons. Since the emotions expressed by emojis are generally straightforward and far less rich than Chinese characters, they can usually express user emotions more accurately. Emoticons are also used as emotional reference values, which have made certain improvements in the accuracy of text sentiment determination. Keywords: Product reviews, text classification, sentiment analysis 第1章 绪论 1.1 研究背景微博的信息在用户间分享流转,使微博具有了传播的特点,微博的信息包含了用户的主观情感,用户能在文字中加入情感色彩的词藻,使微博具有了描述人类主观喜好、赞赏、感觉等情感的特点。微博在传播过程中可能会在某个时间节点或者某个用户参与后,其热议程度呈井喷式增长。微博的传播依靠的是用户,所以需要明白哪些用户是适合做分流工作的,哪些用户是会引起不必要的轰动而尽量避开的。微博的情感信息来源仍是用户,研究需要去发现用户的情感变化以及情感不同于其他用户的用户。用可视化的方法呈现信息有助于用户更加深入地理解微博的特点。可视化架起了用户与数据间的桥梁,让用户洞察看似七零八碎而实则玄机暗藏的数据关系与规律,发现有价值的情感走向、传播趋势,对于舆论引导、新闻扩散具有非常积极的意义。 1.2 国内外研究现状随着互联网的线上评价信息越来越多。据《中国互联网发展状况第35次统计报告》,截至2014年12月,中国互联网用户数量达到6.49亿,研究情感分析,对于热点事件,大家各有各的看法,态度也会大不相同,我们将会从数据中分析其情感倾向,同时一些因素也会影响评价对象的微博评论,其中方向之一就是对这些微博评价进行情感分析。在中国,复旦大学的朱艳兰和周亚谦根据语义相似度的相似度计算了单词的语义倾向,并研究了文本词与已知的贬义知网词之间的相关性,从而得出了文本的情感倾向。后来的研究人员不断尝试改进情感词典,刘卫平首先确定了语义词集中的种子词和贬义词集中的种子词。在HowNet情感词集的帮助下,构建了中文基本情感词典,然后又整合了TF-IDF方法。最后加权,用来判断中文文本数据集的情感极性。 参考国内外文献之后,发现采用情感词典的方法对于情感分析研究,是比较适合的,我们知道情感词虽然可以反映出情感的倾向,比如正负,但是有些情感词也是有强弱的,比如“激动”就比“开心”的强度的要高,所以本文结合汉语情感词本体数据库,构建了具有情感强度的基本情感词。此外,也会构建程度副词和否定词等情感词典。将采用情感倾向加权的方法对微博评论进行情感计算。因为采用加权的方式可以区分出情感的强弱,体现出了其中的差异性。提高了准确性,以及分类的效果。 近年来,尽管研究人员对微博情感分类的研究兴趣持续上升,但与国外相比仍有一定差距。 毕竟中文微博不同于英语微博。在中文微博中,情感分类研究中仍然存在很大的挑战。 1.3 研究的目的和意义如今线上微博评价大量增加、评价内容多种多样,大家在获取信息这方面很难实现。所以将这些评价进行有效的挖掘就显得格外重要,尤其是对微博评价实现情感分析,也就是我们所要研究的基于支持向量机分析微博评价,通过支持向量机的方法更好的解决微博评论二分类的问题。针对微博评论语句进行数据预处理和分词工作,将对句子情感的识别转化为词汇序列的情感识别问题。 为了提高词汇情感辨别的准确性,减轻实验工作的强度,本文采用基于“词云”的数据可视化方法对特定词汇进行筛选和判断,并通过Word2vec等提取原始文本数据的特征信息。构造单词向量矩阵,并为后续的情感分类模型的训练提供数据。 使用数据可视化工具进行报告可以使我们能够使用一些简短的图形来反映那些复杂的信息,从而可以更好地帮助我们掌握社会团体的观点和态度。 1.对现有的情感分析算法进行研究,了解其不足及其产生的原因,在参考当今研究现状的基础上,了解推荐算法的攻关难题和提出的解决方案,整合各个算法的优点,运用改进的算法对数据进行分析。 2.微博的情感分类具有重要的理论意义和应用价值[2]。 1.4全文组织结构本文共分为6章,文章结构及各章内容简介如下: 第1章 介绍了本论文研究的背景、目的和意义,以及中文语句情感分析的国内外的研究现状。最后,给出全文的整体组织结构。 第2章 主要介绍本文所用的技术与算法,比如文本挖掘技术、SVM、Word2Vec、Python等。 第3章 重点讲解基于SVM和情感词典的情感分析方法。 第4章 实现过程从获取原数据,对数据进行文本预处理,使用word2vec模型训练SVM模型,最后进行情感判断。 第5章 工作总结与展望。主要对论文的工作进行总结回顾,并提出下一步的工作展望。 第2章 相关技术综述 2.1 文本挖掘技术Web挖掘逐渐从数据挖掘演变而来[3][4]。但也可以这样说,它的概念为从大量网络信息中搜索有用信息。在动态,半结构化网站资源中搜索重要信息是一个综合领域,包括Web技术。 Web中的内容挖掘一般基于文本信息挖掘,但与普通的平面文本挖掘功能和方法大体上相同,但大多数Web文本都是非结构化和半结构化的,因此很常见比传统的数据挖掘更难。传统的数据挖掘面向的是数据仓库中的数据,网页结构的差异,Web内容的实时变化是需要获取数据对象的许多网页的操作,它的特点是,Web挖掘使用文本分类,文本聚类,关联规则和其他方法来详细分析内容。 文本挖掘的主要功能是从未经处理的原始文本中提取有用的知识,但是文本挖掘是一项非常艰巨的任务,因为它必须处理本质上模糊且非结构化的文本数据,因此需要学习多种学科,涵盖文本分析, 模式识别,统计学,数据可视化,机器学习,数据挖掘和其他技术。
基于支持向量机的方法是将文本趋势分析作为一个分类问题,选择一个离俩个样本都尽量远的中间线,当有新的样本来时,判断在这条线的哪个部分可以得出新的样本的类别。选择文本中的代表性词作为特征,计算其权重,形成向量空间模型。 SVM使用有限的样本信息来找到学习能力和模型复杂性之间的最佳,以期获得最佳的提升能力。SVM最初显示出比现有方法优越的性能[5]。一些学者认为,随着神经网络的发展,支持向量机正在成为一个新的研究热点[6]。 2.3 PythonPython具有如下特点: (1)可移植性,因为其开源特性,Python在很多平台被使用。 (2)解释性,可以通过编译器和不同的标签和选项从源文件转换成计算机所使用的语言。 (3)面向对象,可以面向过程也可以面向对象[7][8]。 (4)可扩展性 (5)大量的库,Python标准库都非常庞大[9] 第3章 基于SVM和情感词典的情感分析方法 3.1 支持向量机支持向量机是Vapnik等人通过对统计学习理论的多年研究而提出的一种机器学习算法。它使用非线性映射将原始数据映射到更高的维度。支持向量和最优分割超平面是SVM算法的中心。SVM通过找寻最大边缘超平面来决定SVM的支持向量和最佳分割超平面。 SVM算法中支持向量和分割超平面如图3-1所示:
图3-1 SVM分类示例 3.2基于情感词典的情感分析方法传统的基于情感词典的情感分析方法主要是基于情感词典来分析评论文本。一些常见单词为基准情感词典,但是很容易被批评。因为中文表达形式的多样性,在各种应用领域中,情感词能够表达的情感并不都是一样的。因此,如果使用某个字段中的中文文本,则使用该字段的情感词典来分析情感。这是必要且合理的。 大致算法的就跟下图所示一样,但我这张图还存在一些缺陷,就是在判断词语词性时没有将循环展示出来。
名词,动词,形容词,副词,成语都能够作为情感词。一般情况下,对出现在文本中的情感词来分析文本的情感倾向。网络时代的到来,使微博评论文本中出现了大量的网络术语和各类的表情包,一些网络用语与如今情感词典中的情感词不同,但它们也表达了情感倾向。微博评论的情感分析经常在文本中遇到Internet情感词[11]。如何让机器对这些网络情感词做出情感倾向判断将直接影响情感分析对微博评论的结果。 3.4 SVM算法SVM算法推导到最后其实就是解决二次规划的问题,序列最小化(Sequential Minimal Optimization,SMO)算法就是SVM中解决二次规划问题的算法。SVM的优化目标是为了找一个平面,该平面可以使间隔最大化,所以为了解决优化问题,可以使用拉格朗日乘子法求解对偶问题,这个对偶问题还有一个条件是KKT条件约束,要求样本中每一个向量都满足约束条件。可是实际结果是没有合适的核函数能使得样本是线性可分的,所以为了解决这个问题,我们就需要允许支持向量机在少部分样本上出错,因此就需要确定新的KKT条件,所以在这样的情况下,KKT公式中的容忍度因子C值越小[12],允许越多的样本不满足约会条件,最终目的也就是计算出一组最优的alpha和b的值。重复此过程,直到达到一个条件满足我们需要的最优结果,程序结束。 将上面的式子代入SVM的对偶问题并消去求和项中的可以得到仅关于的二次规划问题,该优化问题有闭式解可以快速计算。 SMO计算步骤: (1)将所有的拉格朗日乘子格式化 (2)将不满足KKT条件的乘子带入,求解二次规划问题。 (3)反复执行上面步骤,直到全部乘子满足KKT条件。 SVM的目标是找到一个超平面,这个超平面能够很好的解决二分类问题,所以先找到各个分类的样本点离这个超平面最近的点,使得这个点到超平面的距离最大化,最近的点就是虚线所画的。由以上超平面公式计算得出大于1的就属于打叉分类,如果小于0的属于圆圈分类。 这些点能够很好地确定一个超平面,而且在几何空间中表示的也是一个向量,那么就把这些能够用来确定超平面的向量称为支持向量(直接支持超平面的生成),于是该算法就叫做支持向量机(SVM)了。(感觉这个可以删掉了,除了增加重复率没什么用了) 3.5 评价指标如今在情感分析领域,评价分类器的分类好坏由多种评价指标来实现。这些主要包括:准确率、精确率、召回率和F1值。描述分类器性能的各分类指标的计算公式如表1所示: 表1分类器性能指标 本文课题基于SVM的微博评论分析的数据集来源于网络爬虫微博评论。数据集中有数据10680条。 4.1.2 设计流程图流程主要是以下几个部分,首先需要知道爬虫的网址和内容,接着将数据获取到,获取到数据之后,导入系统,然后进行数据处理,生成词汇表,接着构建向量矩,进行特征选择和训练模型,最后可以出现可视化到界面以供分析。具体流程由下图4-1所示:
获取原数据,是依据特定规则智能地自动检索Internet上的信息,基于Python语言,运用网络爬虫,模拟用户登录,获取微博热点事件的评论数据。爬虫数据的网址为, https://weibo.com/1736329970/IrmrUtVRW?type=comment&sudaref=s.weibo.com&display=0&retcode=6102#_rnd1587618599670 界面如下图4-2所示,部分爬虫所需代码如下图4-3所示:
导入原始数据,利用正则表达式筛选评论内容[13],将原始的数据处理为便于处理的数据,同时去除多余的空格。
预处理主要就是进行文本的词性标注。实际数据无噪音,可在处理后使用。应将高质量数据用作研究目标,以实现所需的高质量采矿结果。本方法选用的是jieba词云。本系统主要是对微博评论进行情感分析,主要以中文为主,因此不但要用到jieba模块的分词技术,还要进行筛选。主要步骤如下所示: (1)首先需要加载词云生成工具,在这里需要对中文跟进行处理。 (2)读取要分析的文本,读取格式 (3)词频统计 (4)取前100个数据 (5)提取关键词绘制词云 具体代码如下图4-5所示:
文本挖掘时间和空间开销增加,中文输入到大规模网络文本提取可能包括与决策无关的单词文本特征提取,这解决了改进文本分类和聚合的问题。分类的通用特征提取方法包括词频,文档频率方法,TF-IDF,信息增益,卡方检验,互信息等。 在本课题中,选用以下方法: ① 将文本进行噪声过滤、分词、停用词过滤等预处理。 ② 计算每篇文本中每个关键词的词频(TF),TF=N/M, 其中M表示这一篇文本中共有M个词,N表示该关键词在该文本中共出现的次数 ③ 计算每篇文本中每个关键词的逆文本频率(IDF) ,IDF=log(D/Dw),其中D表示文本总数,Dw表示该关键词出现过的文本数。 ④ 将每个关键词的TF值和IDF值合并为TF-IDF,TFIDFi.j=TFi.j*IDFi.j。 ⑤ 将每个文档的关键字按照TF-IDF值排序构成最终的向量。情感分类,利用对于评论进行情感分类。 4.2.5 word2vec模型它的主要功能是能够自动确定评论中在线情感词的情感,去掉不需要的无意义的一些词。情绪倾向的判断包括两部分:情绪极性和情绪强度。情绪极性指示情绪是正的还是负的,情绪的强度是指相应情绪的强度。具体实现如下图4-7所示
在加载训练好的积极和消极两个word2vec模型后,就可以对svm模型进行训练,具体的代码如下图4-8所示
在准备工作已经结束后,就可以开始进行单个句子进行情感判断。具体代码如下图4-9所示:
本设计的主要成果是设计并实现一个基于SVM的微博评论分析与预测。主要使用熟悉的开发工具进行研究,并结合基础知识进行详细的设计与实现。 对于本次设计做到了以下两点: (1)分步有序,不能随意更改设计思路。 (2)分析的目的是搞清楚逻辑中心,流程。 通过本次评价分析研究,发现了基于SVM的微博评论分析需要设计一个非常明确的流程,特别是特征选择和算法理解这俩个方面。在微博评论分析方面,机器学习起到了很重要的作用,微博评论分类与分词、还有数据来源、特征选择、参数选择都有很大的关系。 对于本次设计不足的地方有以下几点: (1)特征选择方面,了解并熟悉的方法少,所以对后面的结果无法进一步改善,有待提高。 (2)程序的性能需要不断地优化。 (3)支持向量机的算法学习不到位,当样本量出现不平衡状况时候,会出现预测不准确等其他一些问题。 在最初的系统开发层面,需要熟悉基于SVM的微博评论分析的工作流程,并掌握合适的软件程序的基本知识。从一开始的认识到整体的充分理解,尽管整个过程中存在许多问题,但对最终结果、详细设计和最终测试还是可以接受的。在这探索的过程中,遇到了很多难题,通过自己的努力在各大网站和图书馆找寻相关知识背景的数据和需求,更进一步询问老师和同学。当然,也得到了很多专业解决方案和好的建议。最终通过自己的努力整理出适合本设计的合适方案,包括流程设计方案、调试方案等,直到最终成功运行跑起来,第一次感受到了学以致用的快乐。 随着系统设计即将结束,当前正在设计开发的基于SVM的微博评论分析也初具规模,虽然它们的各项功能并不是特别完善,尽管付出了所有的努力,但感觉它还有一定程度的提升空间,最终还可以做得更好,百尺竿头更进一步,期望为它留下一个圆满的句号,给自己一个好的交代。在这个过程中了解很多新知识,同时,随之而来,也发现了自己的计算机专业知识储备还远远不够,需要继续学习,继续提高自己的专业综合素质。这次的应用研究让我有机会实践应用了学到的知识,这让我意识到实践这两个字的重要性。过程很曲折,但在一一克服的过程中我收获颇多,也成长了很多,知识和经验都得到了极大的丰富。 附录 参考文献 [1]丁森华,邵佳慧,李春艳,杨枝蕊.文本情感分析方法对比研究[J].广播电视信息,2020(04):92-96. [2]李丽华,胡小龙.基于深度学习的文本情感分析[J].湖北大学学报(自然科学版),2020,42(02):142-149. [3]徐琳宏,丁堃,林原,杨阳.基于机器学习算法的引文情感自动识别研究——以自然语言处理领域为例[J].现代情报,2020,40(01):35-40+48. [4]申莹,刘春阳,赵永翼.基于SVM算法的微博评论数据情感分析[J].数字通信世界,2020(01):111+117. [5]吴国栋,刘国良,张凯,涂立静.SVM和RNN在网络评论情感分析中的比较研究[J].上海工程技术大学学报,2019,33(04):378-383. [6]严军超,赵志豪,赵瑞.基于机器学习的社交媒体文本情感分析研究[J].信息与电脑(理论版),2019,31(20):44-47. [7]王锭,杜红.基于深度神经网络的电影评论情感分类研究[J].电脑与信息技术,2019,27(04):18-20. [8]杨亮,周逢清,林鸿飞,殷福亮,张一鸣.基于情感常识的情感分析[J].中文信息学报,2019,33(06):94-99. [9]吴杰胜,陆奎,王诗兵.基于多部情感词典与SVM的电影评论情感分析[J].阜阳师范学院学报(自然科学版),2019,36(02):68-72. [10]彭丹蕾. 商品评论情感分析系统的设计与实现[D].北京邮电大学,2019. [11]CHRISTIAN RAUH,BART JOACHIM BES,MARTIJN SCHOONVELDE. Undermining, defusing or defending European integration? Assessing public communication of European executives in times of EU politicisation[J]. European Journal of Political Research,2020,59(2). [12]Douglas Castro,Danielle Mendes Thame Denny. Economic Relationship between Brazil and China: An Empirical Assessment Using Sentiment and Content Analysis[J]. Scientific Research Publishing,2020,11(01). [13]Wenling Li,Bo Jin,Yu Quan. Review of Research on Text Sentiment Analysis Based on Deep Learning[J]. Scientific Research Publishing,2020,07(03). 
源码下载链接 |
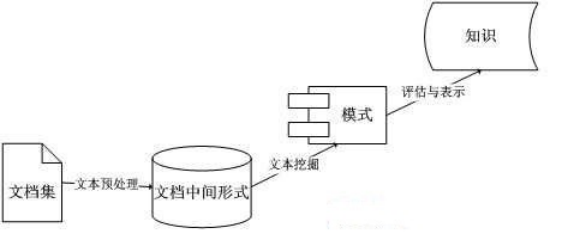 图2-1文本挖掘过程图
图2-1文本挖掘过程图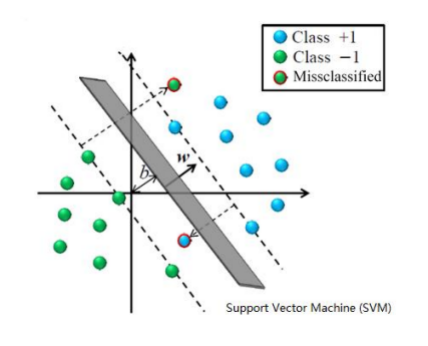
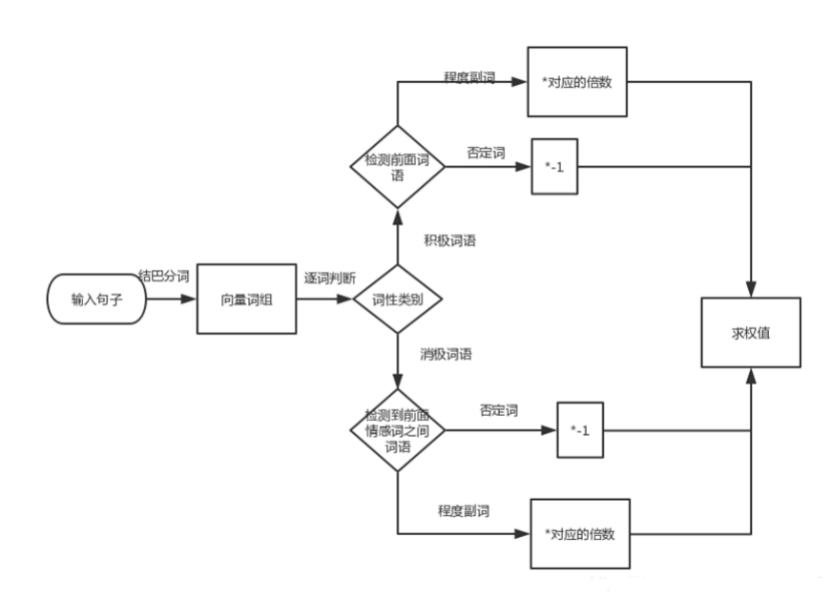 图3-2 算法流程图
图3-2 算法流程图
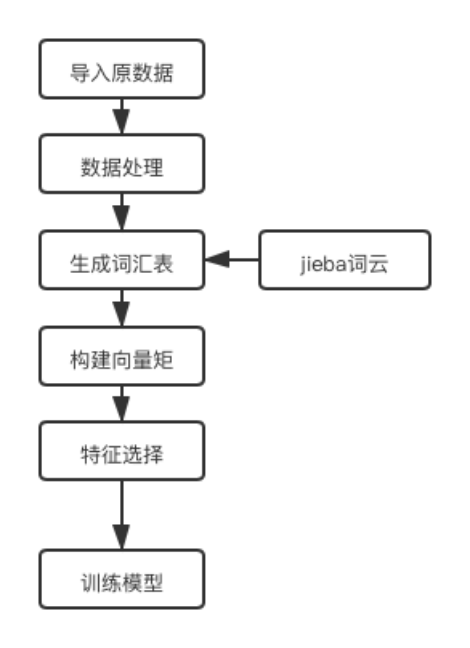 图4.1 基于SVM微博评论分析的流程
图4.1 基于SVM微博评论分析的流程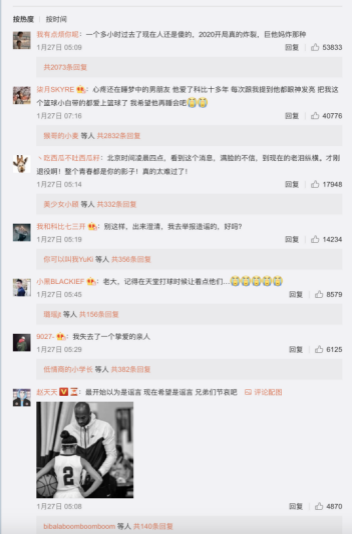 图4-2 需要爬虫的界面
图4-2 需要爬虫的界面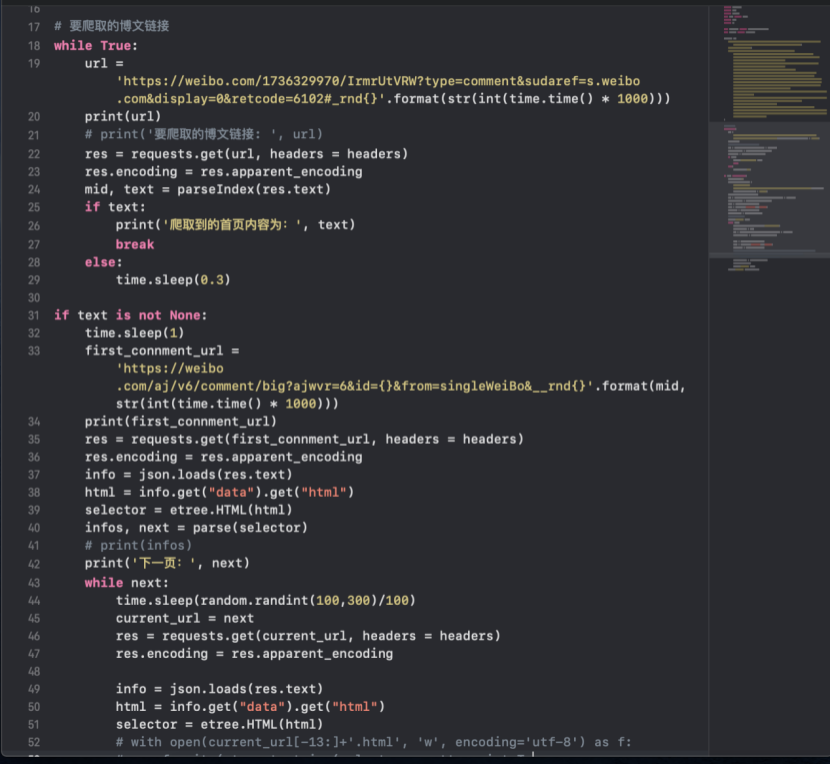 图4-3 爬虫过程
图4-3 爬虫过程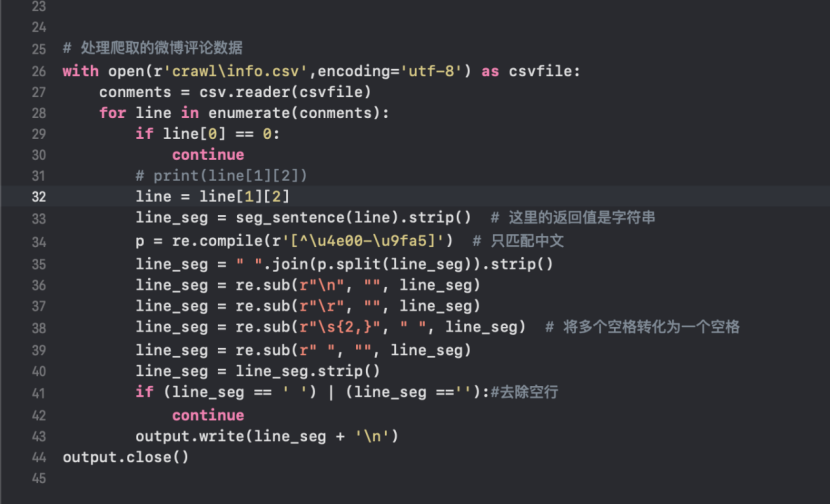 图4-4 处理原始的数据
图4-4 处理原始的数据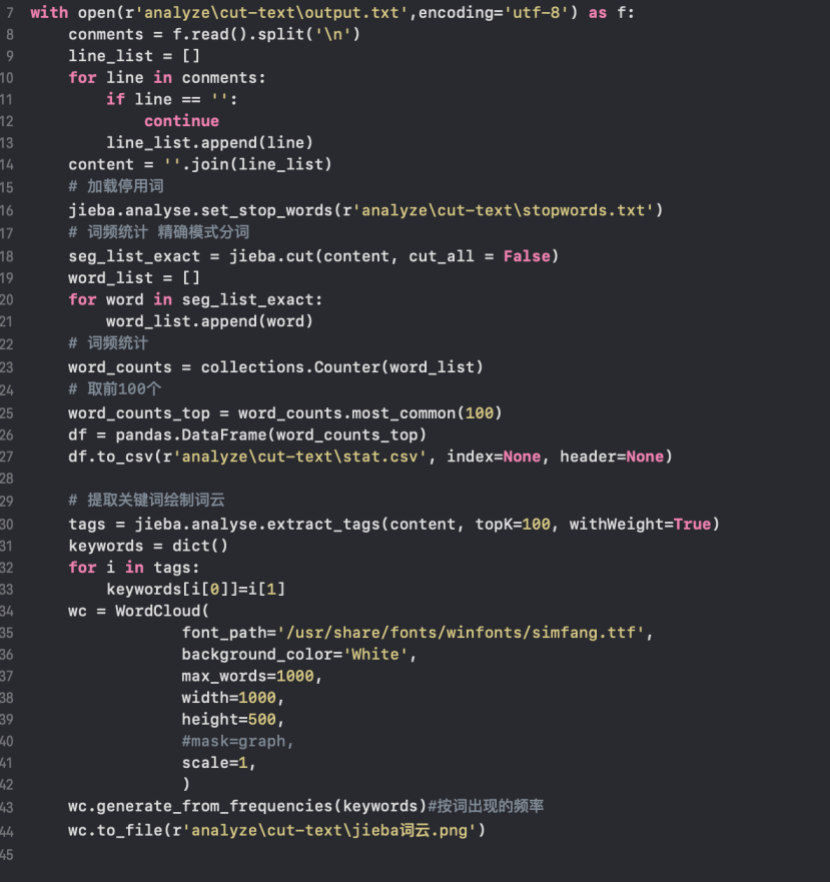 图4-5 绘制词云 生成的没有背景图的词云如下图4-6所示
图4-5 绘制词云 生成的没有背景图的词云如下图4-6所示 图4-6 词云生成结果
图4-6 词云生成结果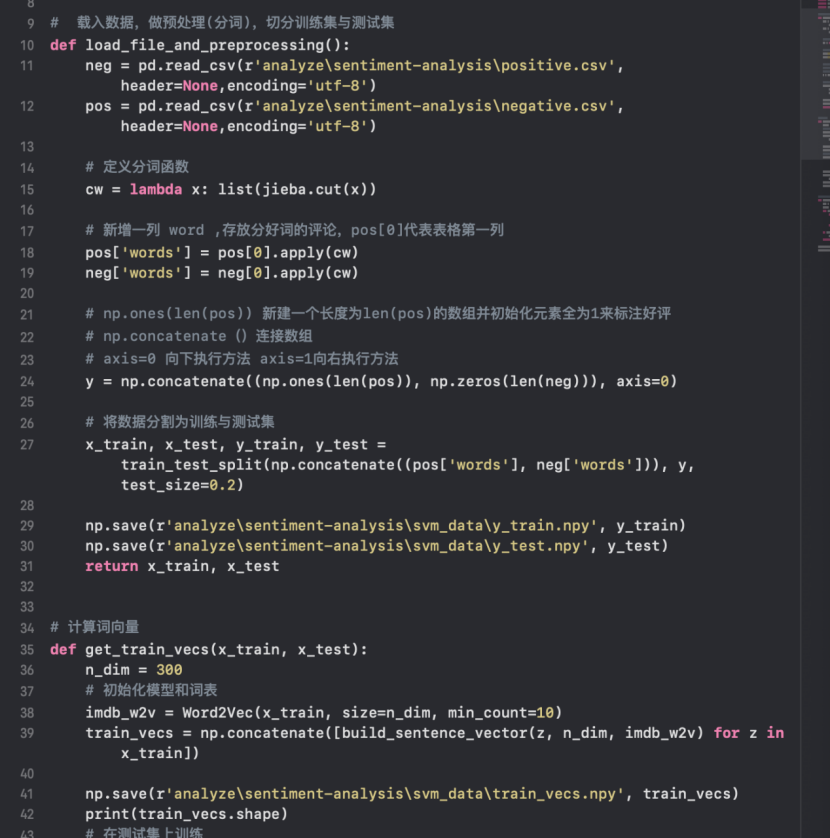 图4-7 正负情绪词典构建
图4-7 正负情绪词典构建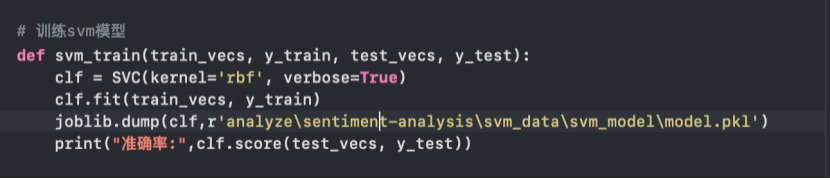 图4-8 svm模型的构建
图4-8 svm模型的构建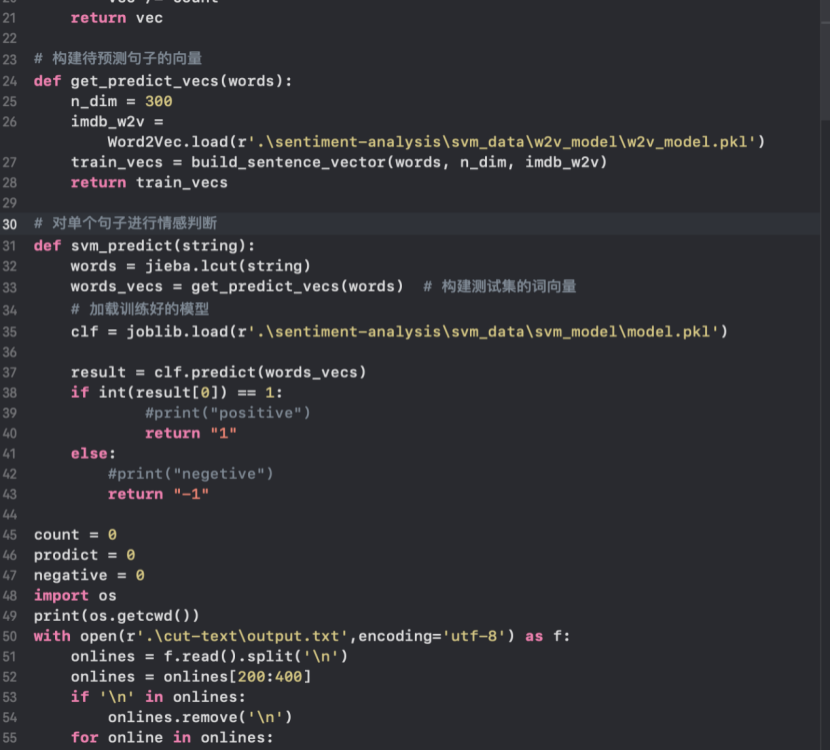 图4-9 情感判断 根据运行出来的结果我们发现,准确率为62.5%,如图4-10。
图4-9 情感判断 根据运行出来的结果我们发现,准确率为62.5%,如图4-10。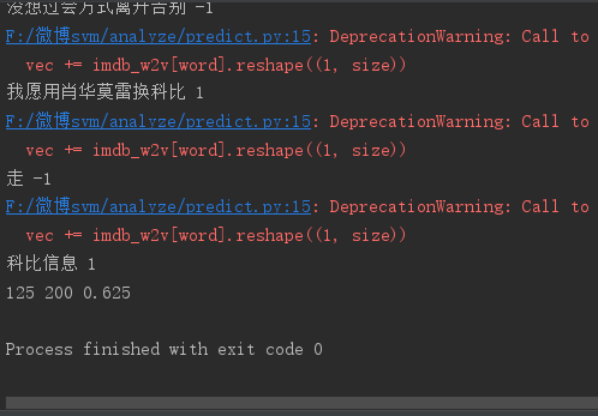 图4-10准确率
图4-10准确率【本文地址】