| Deep Compression for Dense Point Cloud Maps | 您所在的位置:网站首页 › 点云数据采集方法 › Deep Compression for Dense Point Cloud Maps |
Deep Compression for Dense Point Cloud Maps
|
论文 代码 简介:作者提出了一种基于深度学习的有损压缩方法,将一组局部特征描述符与位置存储在一起,然后可以从中恢复点云。 专注于在大型室外环境中有效压缩现代三维LiDAR传感器采集的三维点云数据。 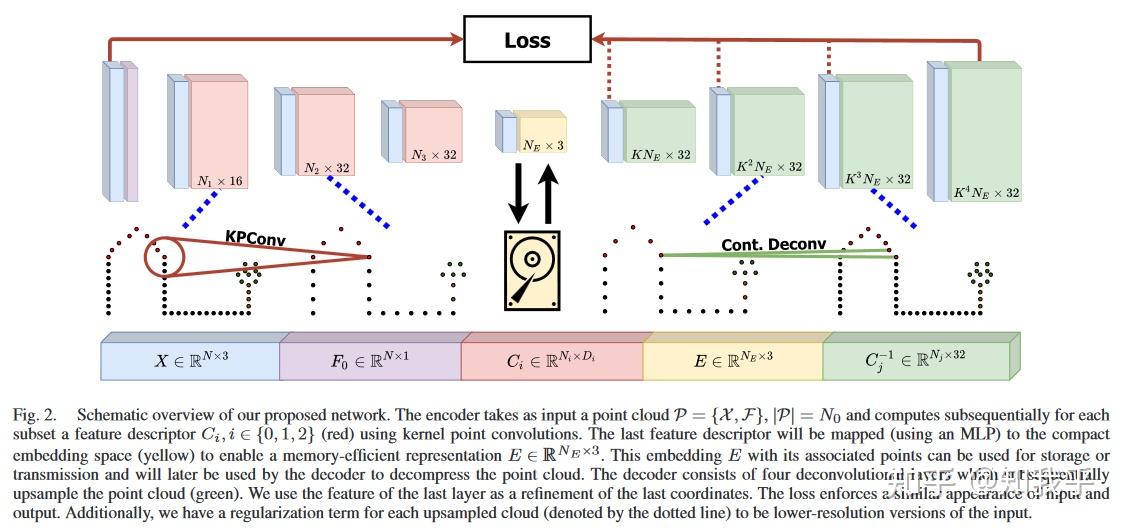 related work: 八叉树需要额外的方法来压缩属性,并且树结构在利用重复出现的常见对象方面不是很有效。 另一种节省内存的可能性是使用从激光雷达或深度摄像机流中采集的点云之间的相关性。这样的投影表示不适用于从许多位置捕获的大型密集地图,因为它只能很好地代表实际视点的环境,不具有很好的通用性。 method:自动编码器由两部分组成:编码器和解码器。编码器获取输入数据,然后学习对其进行简化、更抽象的表达,称为嵌入或代码。然后,将此嵌入用作解码器的输入,解码器尝试使用这种压缩表示来重建原始数据。网络通过将重建结果与原始点云进行比较,通过反向传播学习自监督参数。只要嵌入小于原始点云,就可以实现压缩。换句话说,自动编码器通过减小点云的大小来压缩点云,同时仍保持其基本功能。然后可以更有效地存储或传输这种压缩后的表示形式。 Encoder Blocks为了避免因使用基于网格的表示形式(例如体素网格或八叉树)而产生的离散化效应,作者使用了内核点卷积(KPConv)[1],直接对点本身的特征进行操作。这意味着卷积内核在单个点上运行,而不是在基于网格的点表示上运行。 学习到的描述符在具有卷积核 g 的点 x 处的卷积被定义为其相邻特征的加权和。即:卷积运算的结果是在点 x 处生成一个新的特征描述符(子)—— C_{i} ,它是邻域中特征描述符的加权和,其中权重由过滤器函数g确定。  其中N ( x ) = { ( xi , Fi)∈P | ‖xi-x‖; r }是x在半径r内的邻域。 其中N ( x ) = { ( xi , Fi)∈P | ‖xi-x‖; r }是x在半径r内的邻域。作者认为对于函数g在一致的球面域有助于网络去学习一些有特殊含义的表示信息。 卷积权重W定义在M个核点上,相邻N ( x )的权重由大小为σ的一阶样条插值得到:  其中相对坐标yi = xi - x 、第m个核点( xm )的权重Wm,σ是Kernel Points的影响距离,将根据输入密度进行选择。 其中相对坐标yi = xi - x 、第m个核点( xm )的权重Wm,σ是Kernel Points的影响距离,将根据输入密度进行选择。作者使用基于网格的子采样对之前的点云进行下采样,使用ResNet - like模块。ResNet块中的标识快捷方式使梯度更直接地流向更早的层,以降低因梯度消失而遇到不稳定的风险。无需存储其他信息即可进行解压缩,最后一层由用于压缩特征的 MLP 组成。 Decoder Blocks解码器的任务是从embedding[2]中重构出原始数据。 作者提出了一种解码器块,它可以自己估算丢失的坐标,而不是使用跳过连接(需要额外存储信息)。对于每个点,反卷积由一组 K个MLP 层定义,通过使用偏移块 Δk 在给定半径 r 内获得 K 个新点,该偏移块 Δk 通过将特征空间非线性映射到内核坐标系来确定坐标增量。  方程 (3) 显示了如何通过将半径乘以偏移方块与原始点相加来获得新点,方程 (4) 显示了如何通过对原始特征应用非线性映射 Δk 来获得新特征。 文本描述了一种拟议的反卷积运算符,该运算符用于对点云进行上采样以将其解压缩到任意密度。运算符由两种类型的区块组成:偏移块和特征块。  反卷积核由两个小的MLP网络组成,作为一维卷积。第一个MLP (上半部分)将旧特征F转化为新的特征空间。第2个MLP (下半部分)预测到半径r内新位置X的偏移量。根据反卷积核的个数,在本例中K = 3,对点云进行了K倍的上采样。 反卷积核由两个小的MLP网络组成,作为一维卷积。第一个MLP (上半部分)将旧特征F转化为新的特征空间。第2个MLP (下半部分)预测到半径r内新位置X的偏移量。根据反卷积核的个数,在本例中K = 3,对点云进行了K倍的上采样。偏移块(蓝色方块),表示为 Δk,是一种称为多层感知器 (MLP) 的神经网络,具有一个隐藏层。MLP 在第一层之后使用 ReLU 激活函数,在第二层之后使用 tanh 激活函数。偏移块通过将特征空间映射到内核的坐标系来确定坐标增量。内核是一个数学函数,用于将输入数据转换为更高维度的空间,在那里可以更轻松地将其分开。在这种情况下,内核是 3D 坐标系。 特征块(绿色方块),表示为 \Phi_{k} ,也是一个带有一个隐藏层的 MLP,但它使用两个 ReLU 激活函数,而不是 ReLU 和一个 tanh。该功能块根据旧描述符计算新要素。 反卷积运算符以 C^{-1} 表示,由 K 个偏移块和 K 个特征块组合而成。它以包含 N 个点的点云作为输入,其中每个点具有三个坐标(x、y、z)和一个长度为 Din 的特征向量。操作员输出一个包含 KN 个点的点云,其中每个点都有三个坐标和一个长度为 Dout 的特征向量。将运算符应用于当前图层中的每个点,该点对点云的采样系数为 K。 Loss Function使用倒角距离[3] D_{CD} 作为相似性的度量。  损失函数: 将所有反卷积的输入点云和输出点之间的倒角距离 pˆ 作为正则化项,以确保有效的中间结果。  其中β是一个权重来控制正则项的影响,在此论文中所有的实验中使用β = 0.2。 其中β是一个权重来控制正则项的影响,在此论文中所有的实验中使用β = 0.2。评价指标: 压缩算法的质量由压缩比和重建误差之间的权衡决定。 压缩比是使用存储点云编码所需的每点平均比特数 (BPP) 来测量的。 该指标被称为 “每点平均位数” (BPP),它计算存储点云中每个点的编码所需的位数。要理解这一点,重要的是要知道点云是代表物体或环境表面的三维点的集合。点云中的每个点都有一组坐标(x、y、z),用于定义其在 3D 空间中的位置。 压缩点云时,目标是减少表示每个点所需的数据量,同时仍保持点云的整体形状和结构。BPP 指标衡量平均需要多少位来表示压缩点云中的每个点。 例如,如果压缩点云的平均 BPP 为 2,则意味着平均而言,点云中的每个点都需要 2 位才能以压缩格式存储。此指标可用于比较不同的压缩算法并确定哪种算法在存储空间方面更有效。 为了衡量重建误差,本文使用了三个指标。第一个指标是对称点云距离 (Dd),它广泛用于测量点云重建的质量。Dd 指标由两部分组成:从地面真值点云 (Pin) 到重建 (Pout) 的距离,反之亦然。计算 Dd 的公式由方程 (9) 给出。  使用的第二个指标是地面真值点云 (Pi) 和重建的点云 (Pj) 中点之间的平均距离。该指标由 \bar{D}_{d} (Pi,Pj)表示,使用方程(10)计算。  在此方程中,|Pi| 表示地面真值点云中的点数,xi 表示地面真值点云中的第 i 个点,xj 表示重建的点云中的第 j 个点。xi 和 xj 之间的距离由 d (xi − xj) 表示。 在此方程中,|Pi| 表示地面真值点云中的点数,xi 表示地面真值点云中的第 i 个点,xj 表示重建的点云中的第 j 个点。xi 和 xj 之间的距离由 d (xi − xj) 表示。使用的第三个指标是是两个点云占用网格G之间的交并比( IoU )。这里的IoU定义为  地面真值 (Gin) 和预测输出 (Gout)。结果值的范围介于 0 到 1 之间,其中 0 表示没有重叠,1 表示两组之间完美匹配。参考^https://zhuanlan.zhihu.com/p/394545144^https://zhuanlan.zhihu.com/p/46016518^https://blog.csdn.net/weixin_42894692/article/details/106148094?spm=1001.2101.3001.6650.3&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-3-106148094-blog-107751215.235%5Ev28%5Epc_relevant_t0_download&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-3-106148094-blog-107751215.235%5Ev28%5Epc_relevant_t0_download&utm_relevant_index=6 地面真值 (Gin) 和预测输出 (Gout)。结果值的范围介于 0 到 1 之间,其中 0 表示没有重叠,1 表示两组之间完美匹配。参考^https://zhuanlan.zhihu.com/p/394545144^https://zhuanlan.zhihu.com/p/46016518^https://blog.csdn.net/weixin_42894692/article/details/106148094?spm=1001.2101.3001.6650.3&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-3-106148094-blog-107751215.235%5Ev28%5Epc_relevant_t0_download&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-3-106148094-blog-107751215.235%5Ev28%5Epc_relevant_t0_download&utm_relevant_index=6
|
【本文地址】