| 3D目标检测跟踪:激光雷达+视觉的目标级融合 | 您所在的位置:网站首页 › 激光雷达ros论文 › 3D目标检测跟踪:激光雷达+视觉的目标级融合 |
3D目标检测跟踪:激光雷达+视觉的目标级融合
|
论文:Visual-LiDAR based 3D Object Detection andTracking for Embedded Systems-IEEE Access
内容主要方法激光雷达地面滤波聚类+Bounding box拟合跟踪
视觉雷达和视觉融合
总结
论文中激光检测方法是在原工作基础上改进的,可阅读论文Dynamic Multi-LiDAR Based Multiple Object Detection and Tracking—sensors
内容
提出一种基于Lidar和camera融合的3D目标检测跟踪的方法,在嵌入式平台验证(Jetson AGX Xavier unit by Nvidia)。 Lidar型号:OS1-64 Ouster;Camera型号:ZED camera (Stereo Labs, San Francisco, CA, USA);基于ROS平台开发。 Lidar:3D检测和跟踪,Camera:目标识别,对cluster点云进行分类 如上图框架所示,lidar和camera是两个并行执行的线程。 Lidar线程是对点云处理,获取3Dtrack。Camera线程是同步对图像进行处理,获取2D bounding boxes和label。然后两个传感器的结果进行融合输出最终track。 激光雷达 地面滤波常见地面分类方法: scan-rings(适用于单激光雷达), voxels, height threshold, feature learning 所提方法的前提假设:地面是非平整,点云是由多个激光雷达合成。流程图: 常用的聚方法: The clustering approaches generally utilize connectivity, centroid, density, distribution, or learned features of the LiDAR measurements。 论文采用3D的极坐标网格对点云进行划分。 Step1:采用3D的connected component clustering approach对cell进行分组 Step2:依据cluster的尺寸大小对进行filter,删除尺寸较小的cluster,属于噪声。 Bounding fitting方法是先找到成对角线的两个角点,然后找第三个角点(距离两个角点连线距离最大的point) 当存在遮挡情况时,在tracker模块利用历史信息,对尺寸、方向、位置进行更新。 采用IMM-UKF-JPDAF方法:使用多个运动模型,可适用于车辆在场景下的运动状态,使用JPDAF方法进行关联,适用于多目标复杂场景下关联匹配,主要有以下五步: (a) interaction, (b) state prediction and measurement validation, © data association and model-based filtering, (d) mode probability update, and (e) combination Camera的目标检测采用YOLO-V3网络。 网络说明:uses Darknet-53 (a CNN model with 53 convolutional layers) backbone, and delivers 57.9 mAP (AP50) on Microsoft’s COCO dataset, using an input resolution of 608×608 pixels。 论文中的图片输入大小为416x416,处理时间在100ms以下。 雷达和视觉融合目的:对点云的cluster进行分类 方法:Lidar track的质心点投影到图像坐标系下,计算track质心点o与图像detection bounding box质心点m之间的欧氏距离,形成代价矩阵E,其中依据两个bounding box的iou作预判段,如果小于阈值则欧式距离值设置为默认值,ti是第i个track,dj是第j个detection,k表示第k帧: 采用Munkres association strategy方法确认track和detection的最优关联矩阵为E^ 。并设计一个class的集合γ与代价矩阵E^ 进行对应,使用视觉检测到物体类别进行赋值: 使用KITTI数据集验证了3中object的识别跟踪效果,car 和cyclist跟踪性能优于pedestrian。 |

 以2D的极坐标网格对点云进行划分。每个cell(紫色区域)有两个属性Bins和Channels。Channels是由车辆中心向外扩展。地面点云筛选方法:
以2D的极坐标网格对点云进行划分。每个cell(紫色区域)有两个属性Bins和Channels。Channels是由车辆中心向外扩展。地面点云筛选方法:  论文没有提slope阈值的设置方法。该方法的处理时间与划分的channels、bins、点云数量、FOV有关。在论文的实验条件下,处理时间约为39.1ms。
论文没有提slope阈值的设置方法。该方法的处理时间与划分的channels、bins、点云数量、FOV有关。在论文的实验条件下,处理时间约为39.1ms。



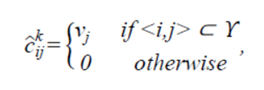 v表示视觉检测到物体类别的种类以及类别关联向量A的尺寸索引。其中每个track都有一个类别关联向量A。当第i个track和第j个detection关联上之后,将detection的class赋值给集合γ对应的C^。 然后依据关联到的类别,对每个track的类别关联向量A进行更新。但是论文中更新的表达式为C ̂_ij^k,存在疑问:
v表示视觉检测到物体类别的种类以及类别关联向量A的尺寸索引。其中每个track都有一个类别关联向量A。当第i个track和第j个detection关联上之后,将detection的class赋值给集合γ对应的C^。 然后依据关联到的类别,对每个track的类别关联向量A进行更新。但是论文中更新的表达式为C ̂_ij^k,存在疑问: 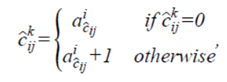 利用类别关联向量A和track的生命周期(age)计算两个指标:类别的确定度Pc和object比率Po。如果Po小于一定阈值,则会被滤掉。
利用类别关联向量A和track的生命周期(age)计算两个指标:类别的确定度Pc和object比率Po。如果Po小于一定阈值,则会被滤掉。 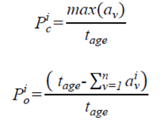
 该框架的最后一个模块是tack management,主要功能是initialize and maintain track statistics, occlusion handling of the tracked object, and pruning out of tracks pertaining to false positive measurements.
该框架的最后一个模块是tack management,主要功能是initialize and maintain track statistics, occlusion handling of the tracked object, and pruning out of tracks pertaining to false positive measurements.  当存在遮挡或距离较远时,bounding box的外形尺寸会变化,此时对track的质心点进行更新。对突变的速度,采用平滑滤波的方法处理,但未提平滑方法。centroid的更新方法:C是原始的,C’是更新后的,ΔL、ΔW、ΔH是外形尺寸上的变化:
当存在遮挡或距离较远时,bounding box的外形尺寸会变化,此时对track的质心点进行更新。对突变的速度,采用平滑滤波的方法处理,但未提平滑方法。centroid的更新方法:C是原始的,C’是更新后的,ΔL、ΔW、ΔH是外形尺寸上的变化: 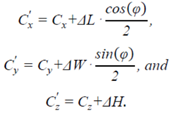 连续5次检测且跟踪上的track设定为mature track。在未被确认未mature track时,如果track未关联上视觉的detection,则会被过滤掉。在跟踪过程中,如果Po大于60%,则会被过滤掉。
连续5次检测且跟踪上的track设定为mature track。在未被确认未mature track时,如果track未关联上视觉的detection,则会被过滤掉。在跟踪过程中,如果Po大于60%,则会被过滤掉。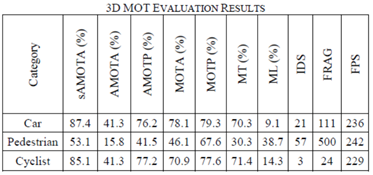 与其他方法的对比验证中,检测方法均使用了PointRCNN,对比结果如下
与其他方法的对比验证中,检测方法均使用了PointRCNN,对比结果如下  测试中该方法遇到的问题: 1) 适用于车速小于80Km/h的场景,进入到检测范围中,当相对车速较快时,无法跟踪上; 2) 当整个跟踪周期内,均存在遮挡,track的外形尺寸无法准确计算,主要原因centroid计算偏差; 3) Track的分类不一定准确,一是camera检测不准确,另一方面是lidar和相机融合关联不准确;
测试中该方法遇到的问题: 1) 适用于车速小于80Km/h的场景,进入到检测范围中,当相对车速较快时,无法跟踪上; 2) 当整个跟踪周期内,均存在遮挡,track的外形尺寸无法准确计算,主要原因centroid计算偏差; 3) Track的分类不一定准确,一是camera检测不准确,另一方面是lidar和相机融合关联不准确;【本文地址】