| Java 简单论文查重程序(SimHash+海明距离算法) | 您所在的位置:网站首页 › 源代码重复率 › Java 简单论文查重程序(SimHash+海明距离算法) |
Java 简单论文查重程序(SimHash+海明距离算法)
|
目录:
0、需求1、前言1.1、开发环境1.1、整体流程1.2、类1.3、核心算法
2、接口的设计和实现2.1、读写 txt 文件的模块2.2、SimHash 模块(核心模块)2.3、海明距离模块2.4、main 主模块
3、接口部分的性能改进3.1、性能分析
4、单元测试4.1、读写 txt 文件的模块 的测试4.2、SimHash 模块 的测试4.3、海明距离模块 的测试4.4、主测试 MainTest
5、异常处理5.1、设计与实现5.2、测试
6、PSP 表格7、参考
0、需求
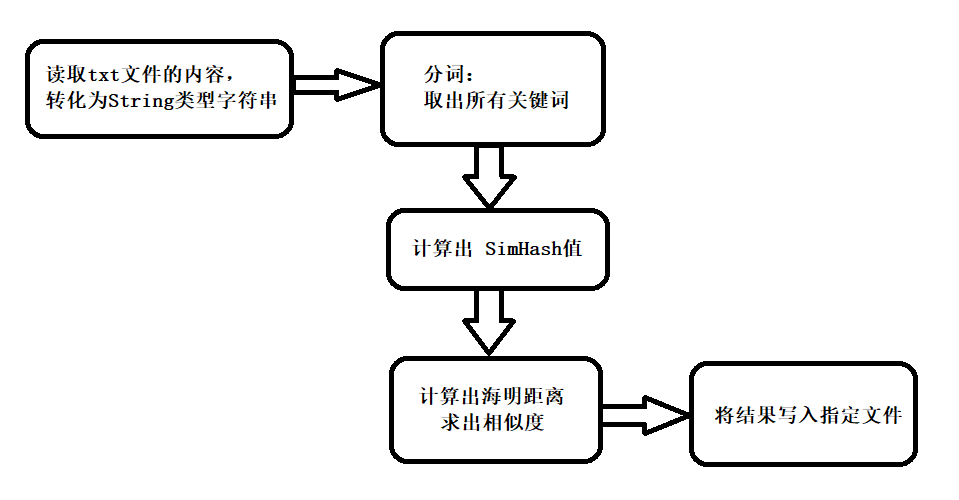
题目:论文查重 描述如下: 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。 原文示例:今天是星期天,天气晴,今天晚上我要去看电影。抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。要求输入输出采用文件输入输出,规范如下: 从命令行参数给出:论文原文的文件的绝对路径。从命令行参数给出:抄袭版论文的文件的绝对路径。从命令行参数给出:输出的答案文件的绝对路径。测试样例使用方法是:orig.txt 是原文,其他 orig_add.txt 等均为抄袭版论文。 测试文件的下载链接也可以自己创建测试文件。 注意:答案文件中输出的答案为浮点型,精确到小数点后两位 1、前言注:此项目是博主的软件工程课程的个人编程作业。 github地址(点击即可跳转) 1.1、开发环境编程语言:Java 14 IDE:Intellij IDEA 2020.1 项目构建工具:maven 单元测试:JUnit-4.12 性能分析工具:JProfiler 9.2 依赖的外部 jar 包:汉语言处理包 com.hankcs hanlp portable-1.5.4 1.1、整体流程
simhash+海明距离
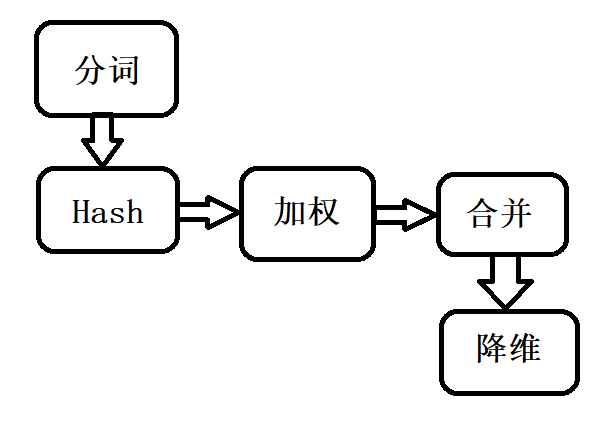
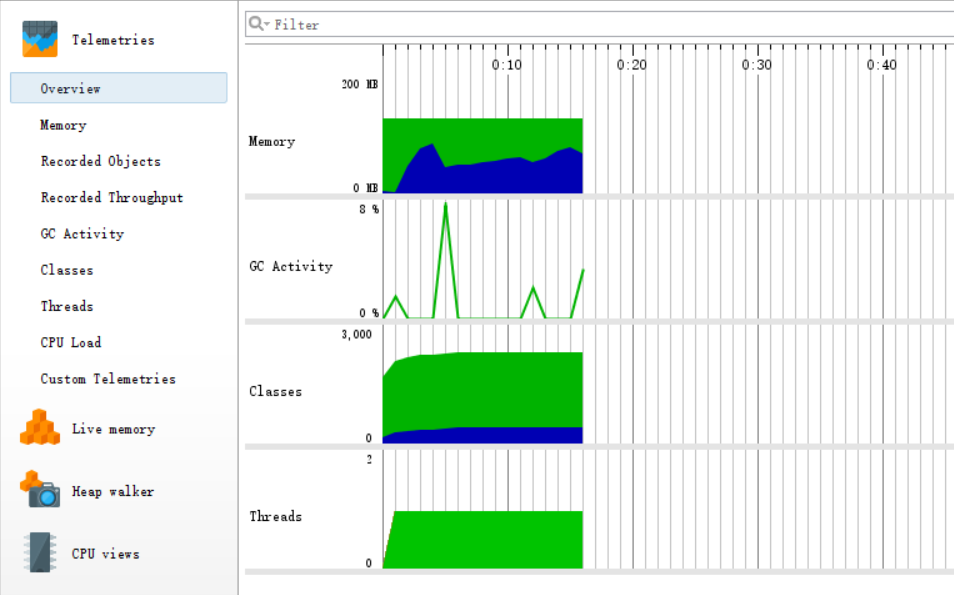
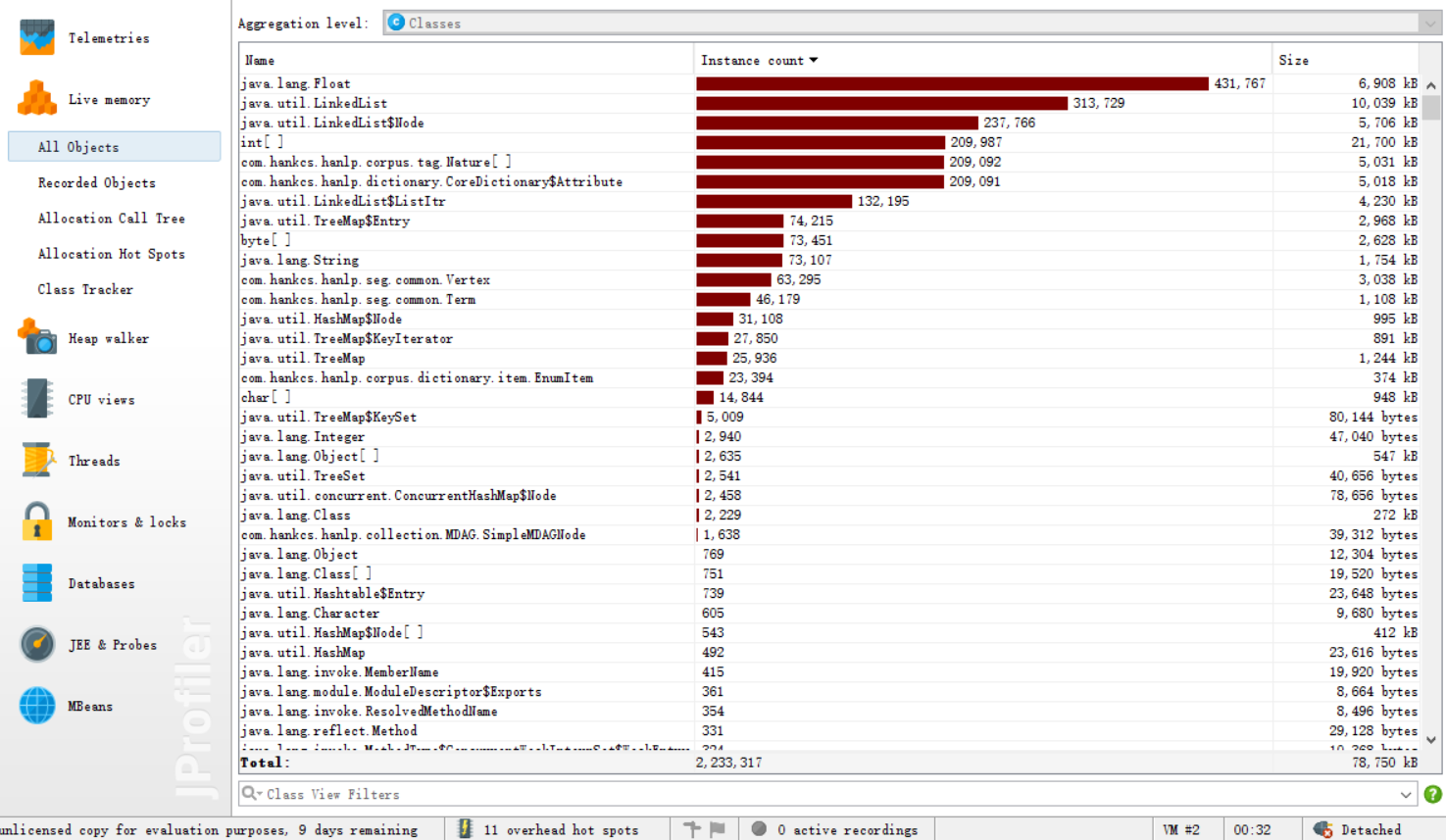
具体可参考: SimHash 原理与实现 2、接口的设计和实现 2.1、读写 txt 文件的模块类:TxtIOUtils 包含了两个静态方法: 1、readTxt:读取txt文件 2、writeTxt:写入txt文件 实现:都是调用 Java.io 包提供的接口,比较简单,这里省略。 2.2、SimHash 模块(核心模块)类:SimHashUtils 包含了两个静态方法: 1、getHash:传入String,计算出它的hash值,并以字符串形式输出,(使用了MD5获得hash值) 2、getSimHash:传入String,计算出它的simHash值,并以字符串形式输出,(需要调用 getHash 方法) getSimHash 是核心算法,主要流程如下: 1、分词(使用了外部依赖 hankcs 包提供的接口) List keywordList = HanLP.extractKeyword(str, str.length());//取出所有关键词2、获取 hash 值 String keywordHash = getHash(keyword); if (keywordHash.length() keywordHash += "0"; } }3、加权、合并 for (int j = 0; j //权重分10级,由词频从高到低,取权重10~0 v[j] += (10 - (i / (size / 10))); } else { v[j] -= (10 - (i / (size / 10))); } }4、降维 String simHash = "";// 储存返回的simHash值 for (int j = 0; j simHash += "0"; } else { simHash += "1"; } } 2.3、海明距离模块 类:HammingUtils包含了两个静态方法: 1、getHammingDistance:输入两个 simHash 值,计算出它们的海明距离 distance for (int i = 0; i distance++; } }2、getSimilarity:输入两个 simHash 值,调用 getHammingDistance 方法得出海明距离 distance,在由 distance 计算出相似度。 return 0.01 * (100 - distance * 100 / 128); 2.4、main 主模块 main 方法的主要流程: 从命令行输入的路径名读取对应的文件,将文件的内容转化为对应的字符串由字符串得出对应的 simHash值由 simHash值求出相似度把相似度写入最后的结果文件中退出程序 3、接口部分的性能改进 3.1、性能分析Overview
方法的调用情况
从分析图可以看到: 调用次数最多的是com.hankcs.hanlp包提供的接口, 即分词、取关键词与计算词频花费了最多的时间。 所以在性能上基本没有什么需要改进的。 4、单元测试 4.1、读写 txt 文件的模块 的测试基本思路: 1、测试正常读取 2、测试正常写入 3、测试错误读取 4、测试错误写入 public class TxtIOUtilsTest { @Test public void readTxtTest() { // 路径存在,正常读取 String str = TxtIOUtils.readTxt("D:/test/orig.txt"); String[] strings = str.split(" "); for (String string : strings) { System.out.println(string); } } @Test public void writeTxtTest() { // 路径存在,正常写入 double[] elem = {0.11, 0.22, 0.33, 0.44, 0.55}; for (int i = 0; i // 路径不存在,读取失败 String str = TxtIOUtils.readTxt("D:/test/none.txt"); } @Test public void writeTxtFailTest() { // 路径错误,写入失败 double[] elem = {0.11, 0.22, 0.33, 0.44, 0.55}; for (int i = 0; i @Test public void getHashTest(){ String[] strings = {"余华", "是", "一位", "真正", "的", "作家"}; for (String string : strings) { String stringHash = SimHashUtils.getHash(string); System.out.println(stringHash.length()); System.out.println(stringHash); } } @Test public void getSimHashTest(){ String str0 = TxtIOUtils.readTxt("D:/test/orig.txt"); String str1 = TxtIOUtils.readTxt("D:/test/orig_0.8_add.txt"); System.out.println(SimHashUtils.getSimHash(str0)); System.out.println(SimHashUtils.getSimHash(str1)); } }测试结果:
代码覆盖率: (SimHashUtils 的 getHash 方法的异常 catch 测试不了)
测试结果:
代码覆盖率:
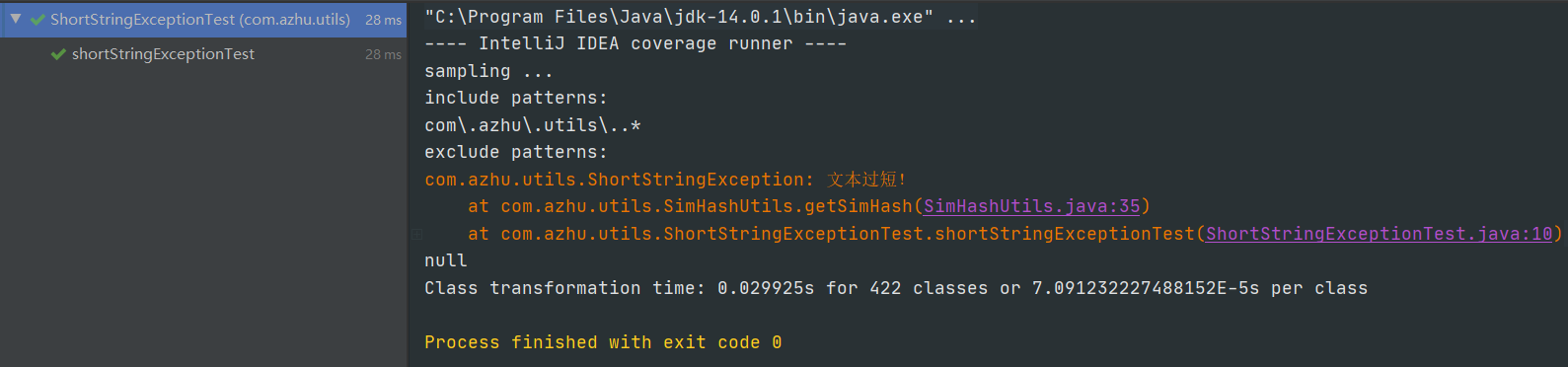
部分测试代码: public class MainTest { @Test public void origAndAllTest(){ String[] str = new String[6]; str[0] = TxtIOUtils.readTxt("D:/test/orig.txt"); str[1] = TxtIOUtils.readTxt("D:/test/orig_0.8_add.txt"); str[2] = TxtIOUtils.readTxt("D:/test/orig_0.8_del.txt"); str[3] = TxtIOUtils.readTxt("D:/test/orig_0.8_dis_1.txt"); str[4] = TxtIOUtils.readTxt("D:/test/orig_0.8_dis_10.txt"); str[5] = TxtIOUtils.readTxt("D:/test/orig_0.8_dis_15.txt"); String ansFileName = "D:/test/ansAll.txt"; for(int i = 0; i if(str.length() super(message); } 5.2、测试测试结果:
https://blog.csdn.net/lance_yan/article/details/10304747 https://www.cnblogs.com/huilixieqi/p/6493089.html |


【本文地址】