| 基于点云的深度学习:点云里的mlp | 您所在的位置:网站首页 › 游戏里mlp是什么意思 › 基于点云的深度学习:点云里的mlp |
基于点云的深度学习:点云里的mlp
|
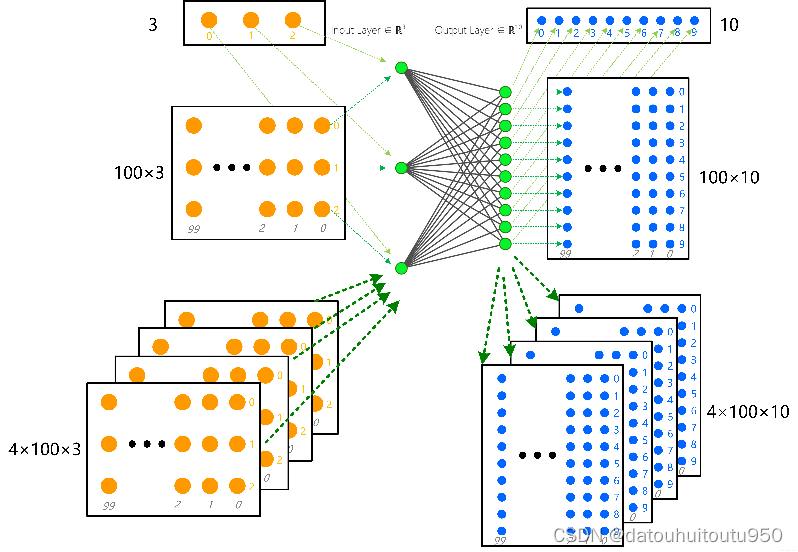
一、多层感知机(MLP)原理简介 多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图: 从上图可以看到,多层感知机层与层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。多层感知机最底层是输入层,中间是隐藏层,最后是输出层 输入层:输入是一个n维向量,就有n个神经元 隐藏层的神经元怎么得来?首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是f(W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数: 输出层,输出层与隐藏层是什么关系?其实隐藏层到输出层可以看成是一个多类别的逻辑回归,也即softmax回归,所以输出层的输出就是softmax(W2X1+b2),X1表示隐藏层的输出f(W1X+b1)。 MLP整个模型就是这样子的,上面说的这个三层的MLP用公式总结起来就是,函数G是softmax 因此,MLP所有的参数就是各个层之间的连接权重以及偏置,包括W1、b1、W2、b2。 对于一个具体的问题,怎么确定这些参数?求解最佳的参数是一个最优化问题,解决最优化问题,最简单的就是梯度下降法了(SGD): 首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止(比如误差足够小、迭代次数足够多时)。 这个过程涉及到代价函数、规则化(Regularization)、学习速率(learning rate)、梯度计算等, 总之,多层感知机是一个输入经过若干个线性加权,非线性激活之后输出的机制,根据通用近似定理:对于具有线性输出层和使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其中隐藏神经元的数量足够,它可以以任意的精度来近似任何一个定义在实数空间中的有界闭集函数。 二、MLP作用 先从感知机的一层说起,其MLP结构如下。 Output= f (Input×Weights+biases) 其中:Input:N×C1 Weights:C1×C2 biases:N×1×C2 Output:N×C2 f(·):激活函数,逐元素映射 权值矩阵的一行就是同一个神经元上面的所有不同输入的权值 Input一共N行,每行C1个Feature,MLP能够实现将C1维转换为C2维。这C2维中每一维都整合了原来全部C1维的信息,但不同维度对这些信息的侧重点不同。 换一个形象的说法,经过了MLP,相当于把原来整行的信息揉成一团,再揉成了C2个不同形状,代表原来那行信息的C2个不同特征。 本质上MLP的输入是单维的,MLP网络的结果由上一层所有单元决定, 如果从特征融合的角度来观察 MLP网络融合的是单个维度上所有位置的特征,即单维信息的全局特征转换和信息重组 从点云方面来说, 如果输入是每个点的位置及特征,对其使用MLP,它进行的就是单个点的所有特征(坐标颜色强度)的信息重组和高维转换。 再者,由于激活函数会放大一些值,抑制一些值,因此MLP可以实现特征提取。 除了上面的公式之外,MLP一般还会加上ReLU、Sigmoid等非线性的激活函数,以及Drop Out层等 三、点云里的shared mlp而所谓Shared,是指Input矩阵的每一行都利用相同的Weights的信息。这是MLP的自带属性。 因为根据矩阵运算规则,Input矩阵中的每一行都会乘以Weight矩阵中的每一列。我们可以把Weight矩阵的一列看成一个工人,一共C2个工人,每个工人都接受Input行的C1个零件,但不同工人对零件的使用不同,造出不一样的模型,也就是得到C2个的特征。这样Input中的行无论怎么排序都不影响结果。在点云处理领域,就解决了点云的无序性问题。只是在点云处理网络中的一个说法。强调对点云中的每一个点都采取相同的特征转换。 其本质上用[1,1]大小的卷积核去做卷积操作,减少了大量的参数 与普通MLP没什么不同,其在网络中的作用即为MLP的作用:特征转换、特征提取 从点云方面来说, 如果输入是每个点的位置及特征,对其使用MLP,它进行的就是单个点的所有特征(坐标颜色强度)的信息重组和高维转换。 由于点云中的每一个点不是独立的,因此不应看作独立的样本。在shared mlp中,输入为包含多点的点云,我们对每一个点乘以相同的权重,这就叫做shared weights。而在mlp中,输入为单个向量,因此不需要共享权重 PyTorch实现MLP的两种方法讨论MLP的时候输入的表示的是以向量(Tensor维度为1)作为输入的计算过程,对于由多个向量构成的多维矩阵(Tensor维度大于等于2),计算过程类似,保持向量的组合尺寸,只对向量的不同特征维度进行加权计算 例如对于一个长度为100的点云(100×3,tensor)进行MLP处理,经过一个3输入-10输出的Layer计算后,输出结果仍为一个二维tensor(100×10,tensor); 同样,对于一个batch size为4,长度为100的点云数据包(4×100×3,tensor),经过同样的Layer计算,输出为一个三维tensor(4×100×10,tensor),如下图所示
方法1:nn.Linear
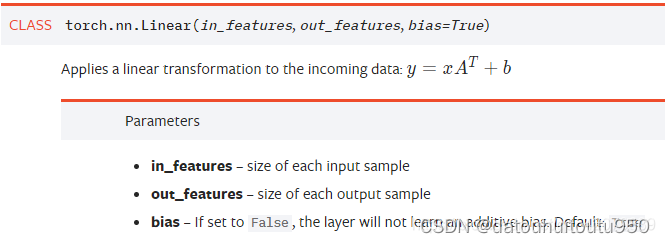
对输入数据x进行一个线性变化, in_features:每个输入样本的大小,对应MLP中当前层的输入节点数/特征维度 out_features:每个输出样本的大小,对应MLP中当前层的输出节点数/特征维度 输入数据形式:形状为[N, *, in_features]的tensor,N为batch size,这个参数是PyTorch各个数据操作中都具备的,相似的,输出数据形式为[N, *, out_features] 需要注意的是输入输出数据形式中的*参数,其表示为任意维度,对于单个向量,*为空 利用nn.Linear对多批次点云集进行Layer计算 import torch import torch.nn as nn import torch.nn.functional as F x = torch.randn(4, 100, 3) # 创建一个batch_size=4的点云,长度100 layer = nn.Linear(3, 10) # 构造一个输入节点为3,输出节点为10的网络层 y = F.sigmoid(layer(x)) # 计算y,sigmoid激活函数 print(x.size()) print(y.size()) >>>torch.Size([4, 100, 3]) >>>torch.Size([4, 100, 10]) 可以看出,nn.Linear作用在输入数据的最后一个维度上 方法2:nn.Conv1d & kernel_size=1
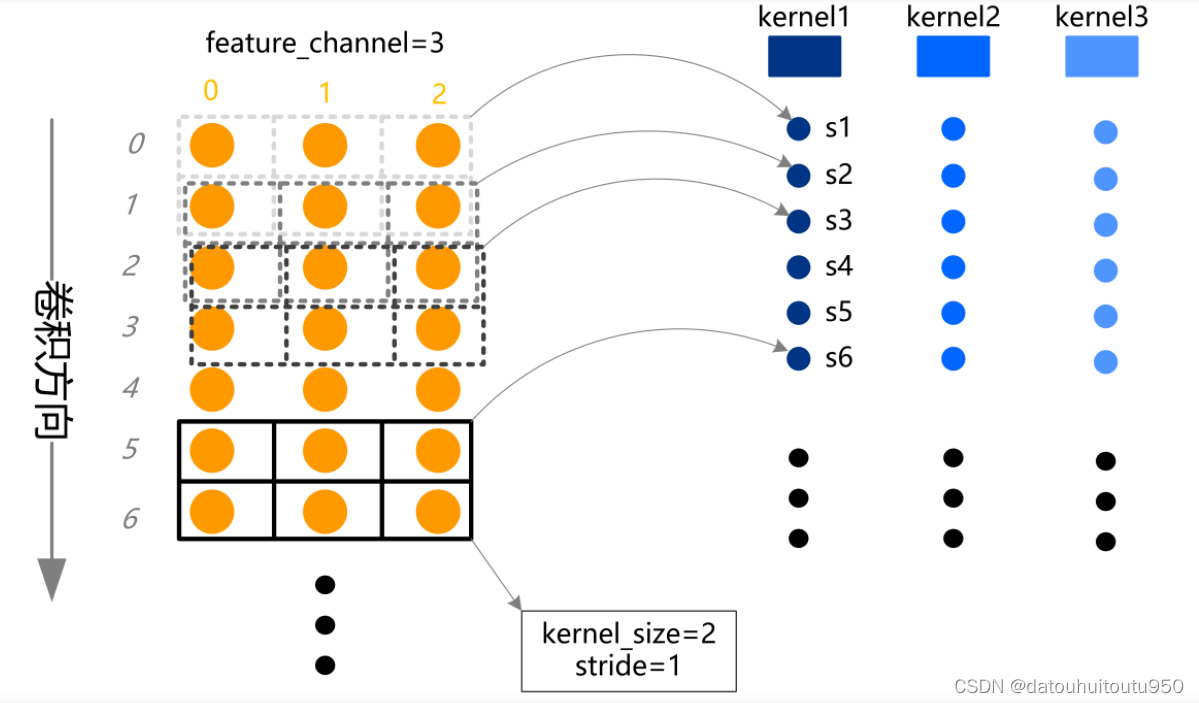
关键参数: in_channels:输入通道,MLP中决定Layer输入的节点(特征数) out_channels:输出通道,MLP中决定Layer输出的节点(输出特征数以及卷积核个数) kernel_size:卷积核的宽度,应用在MLP中必须为1 stride:每次卷积移动的步长,应用在MLP中必须为1 padding:序列两端补0的个数,应用在MLP中必须为0 一维卷积表示对序列数据进行卷积
利用nn.Conv1d对多批次点云集进行Layer计算 import torch import torch.nn as nn import torch.nn.functional as F x = torch.randn(4, 3, 100) # 创建一个batch_size=4的点云,长度100 layer = nn.Conv1d(3, 10, kernel_size=1) # 构造一个输入节点为3,输出节点为10的网络层 y = F.sigmoid(layer(x)) # 计算y,sigmoid激活函数 print(x.size()) print(y.size()) >>>torch.Size([4, 3, 100]) >>>torch.Size([4, 10, 100]) 可以看出,nn.Conv1d的输入数据格式只能一个三维tensor[batch, channel, length],与nn.Linear输入数据格式不同;并且,nn.Conv1d的数据作用位置也不同,nn.Conv1d作用在第二个维度channel上 nn.Conv1d, kernel_size=1与nn.Linear不同 从上述方法1和方法2可以看出,两者可以实现同样结构的MLP计算,但计算形式不同,具体为: nn.Conv1d输入的是一个[batch, channel, length],3维tensor nn.Linear输入的是一个[batch, *, in_features],可变形状tensor,在进行等价计算时务必保证nn.Linear输入tensor为三维 nn.Conv1d作用在第二个维度位置channel,nn.Linear作用在第三个维度位置in_features,对于一个X XX,若要在两者之间进行等价计算,需要进行tensor.permute,重新排列维度轴秩序 四、MLP在点云里的作用 1、单维信息的全局特征转换和信息重组 单个点的所有特征(坐标颜色强度)的信息重组和高维转换。 再者,由于激活函数会放大一些值,抑制一些值,因此MLP可以实现特征提取。 2、特征向量的维度变化 在特征学习阶段为了保证维度的整齐,一般会在最后特征提取完成之后再加一个线性层得到预定的维度。 备注:本文为早期学习笔记,参考了很多其他人的知识,参考文章不全,如有遗漏,希望可以提醒下我一定加上 参考文章: https://blog.csdn.net/liuyukuan/article/details/72934383 MLP多层感知机(人工神经网络)原理及代码实现_mlp神经网络_生活不只*眼前的苟且的博客-CSDN博客 |


【本文地址】