| 一文教你搞懂2D卷积和3D卷积 | 您所在的位置:网站首页 › 深度神经网络和卷积神经网络的区别 › 一文教你搞懂2D卷积和3D卷积 |
一文教你搞懂2D卷积和3D卷积
|
前言
本人最近在搞毕设时发现自己一直会搞混2D卷积和3D卷积,于是在网上查阅了大量资料,终于明白了其中的原理。希望刷到这篇博客的小伙伴能够停下来静心阅读10分钟,相信你读完之后一定会有所收获。 2D卷积 单通道卷积 在深度学习中,卷积是最基本的乘法和加法,对于一幅只有一个信道的图像,其卷积如图所示(本例中stride = 1, padding = 0)。 这里的过滤器是一个3×3的矩阵,它的元素是[[0,1,2],[2,2,0],[0,1,2]]。过滤器在输入端滑动。在每个位置,它都在做元素的乘法和加法。每个滑动位置都以一个数字结束。最终的输出是一个3x3矩阵。 多通道卷积 多通道卷积过程如下:每个kernel都应用于前一层的输入通道,以生成一个输出通道。我们对所有kernel重复这个过程以生成多个通道。然后将这些通道汇总在一起,形成一个单独的输出通道。 这里的输入层是一个5×5×3的矩阵,有3个通道。Convolution Filter是一个3×3×3矩阵。首先,Filter中的每个kernel分别应用于输入层中的三个通道,执行三个卷积,得到3个通道,大小为3 x 3。 在5×5矩阵上执行遍历的就是每一个kernel。然后这三个输出的通道相加(元素相加)形成一个单独的通道(3 x 3 x 1)。这个最终的单通道就是使用Filter(3 x 3 x 3矩阵)对输入层(5 x 5 x 3矩阵)进行卷积的结果。 在上面已经解释过,虽然我们是在3D数据(高度×宽度×通道数)上进行卷积,但由于Convolution Filter只能在高度和宽度方向上移动,因此仍被称为2D卷积,一个Filter和一张图像卷积只能生成一个通道的输出数据。 3D卷积使用的数据和2D卷积最大的不同就在于数据的时序性。3D卷积中的数据通常是视频的多个帧或者是一张医学图像的多个分割图像堆叠在一起,这样每帧图像之间就有时间或者空间上的联系。 下面这张图可以说明3D卷积的大致过程。左边是输入层,此时我们在空间上看到的3维(即深度方向)不再表示通道数,而是图片的帧数,**也就是说这其实是图像中的单个通道的一帧帧图片堆叠之后的效果。**因此对于三通道(RGB)图像组成的一段视频,实际应该包含三个这样的3D数据,这里只是其中一个通道。Convolution Filter的深度不再与通道数相同(很显然),只需要满足 |


 我们可以认为此过程是将3D Filter矩阵滑过输入层。请注意,输入层的通道数和Filter的Kernel数相同。3D Filter 只能在图像的2个方向(高度和宽度)上移动(这就是为什么这种操作被称为2D卷积的原因,尽管3D Filter 用于处理3D体积(高度×宽度×通道数)数据)。在每个滑动位置,我们执行逐元素的乘法和加法运算,结果为单个数字。 在以下示例中,滑动在水平5个位置和垂直5个位置(5=7-3+1)进行。在深度方向上再进行元素相加后,我们得到一个输出通道。
我们可以认为此过程是将3D Filter矩阵滑过输入层。请注意,输入层的通道数和Filter的Kernel数相同。3D Filter 只能在图像的2个方向(高度和宽度)上移动(这就是为什么这种操作被称为2D卷积的原因,尽管3D Filter 用于处理3D体积(高度×宽度×通道数)数据)。在每个滑动位置,我们执行逐元素的乘法和加法运算,结果为单个数字。 在以下示例中,滑动在水平5个位置和垂直5个位置(5=7-3+1)进行。在深度方向上再进行元素相加后,我们得到一个输出通道。 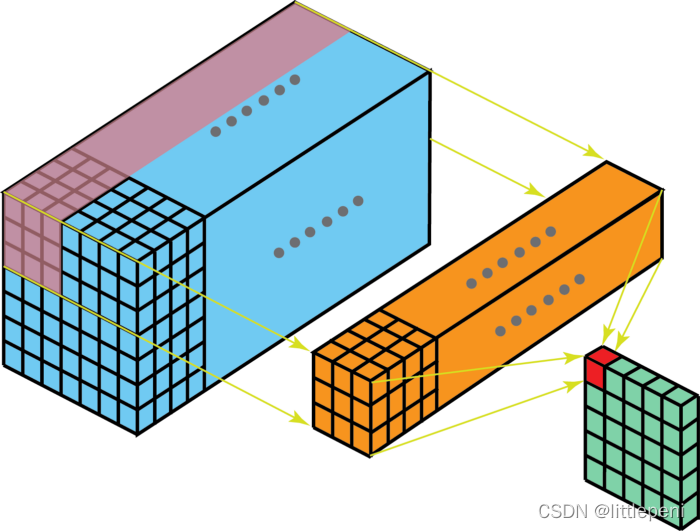 现在我们可以知道如何在不同深度的图层之间进行变换。假设输入层具有Din通道,而我们希望输出层具有Dout通道。我们需要做的只是将Dout 个Filter应用于输入层,每个Filter都有Din个kernel,每个Filter提供一个输出通道。应用Dout个Filter后,我们将拥有Dout个通道,然后可以将它们堆叠在一起以形成输出层。(输出层的Dout个通道也可称为Dout个Feature map,因此输出的Feature map数实际与Convolution Filter的数量相同。)
现在我们可以知道如何在不同深度的图层之间进行变换。假设输入层具有Din通道,而我们希望输出层具有Dout通道。我们需要做的只是将Dout 个Filter应用于输入层,每个Filter都有Din个kernel,每个Filter提供一个输出通道。应用Dout个Filter后,我们将拥有Dout个通道,然后可以将它们堆叠在一起以形成输出层。(输出层的Dout个通道也可称为Dout个Feature map,因此输出的Feature map数实际与Convolution Filter的数量相同。) 
【本文地址】