|
之前阅读过的一篇论文,现将笔记记在此处。  论文地址 论文源码 论文地址 论文源码
简介
文章提出了一种端到端的深度学习结构,可以实现从单张彩色图片生成三角形网格的3D模型。以往的方法受限于深度神经网络性质的限制,将点云和体积表示的三维形状转换为易于使用的网格模型存在诸多问题。与以前的方法不同的是,这篇文章的网络用基于图的卷积神经网络(GCN)表示三维网格,并利用从输入图像中提取的感知特征对椭球体进行渐进式变形,从而生成正确的几何图形。采用由粗到精的策略使整个变形过程稳定,并定义了各种网格相关损失来捕捉不同层次的特性,以保证视觉上美观和物理上精确的三维几何。大量实验表明,该方法不仅能定性地生成细节较好的网格模型,而且与目前最先进的三维形状估计方法相比,具有更高的三维形状估计精度。  点云和体积都丢失了对于重建网格模型不容确实的重要表面细节,即网格,然而三维网格对于许多应用是更加可取的,因为其具有轻量级、能够模拟形变细节、容易变形为动画等诸多优点。 点云和体积都丢失了对于重建网格模型不容确实的重要表面细节,即网格,然而三维网格对于许多应用是更加可取的,因为其具有轻量级、能够模拟形变细节、容易变形为动画等诸多优点。 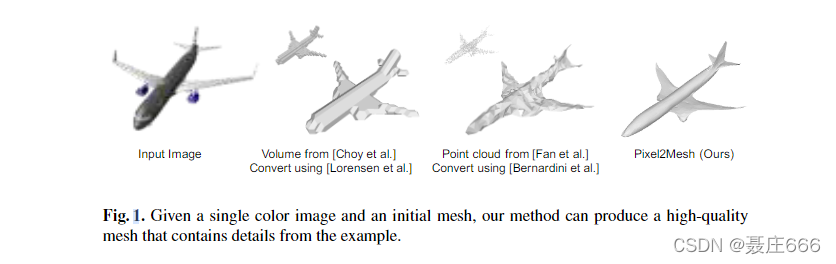 本文的模型学习将网格从一致的初始形状变形到目标几何形状。这有几个方面好处。首先,深度网络更适合预测残差,例如空间变形;而不是结构化输出,例如一个图结构。其次,可以将一系列变形叠加在一起,从而使形状逐渐细化到细节。它还可以很好把握深度学习模型的复杂性和结果质量之间的平衡。最后,它提供了将任何先验知识编码到初始网格的机会,例如拓扑。作为一个创新研究,在这篇文章中,专门研究了可以通过变形固定大小的椭球体来近似使用亏格为0的三维网格的对象。在实践中,大多数常见的对象在这种设置下都可以很好地处理,例如汽车、飞机、桌子等。 要实现上述目标,存在几个固有的挑战。第一个挑战是如何在神经网络中表示网格模型(本质上是一个不规则的图形)并且仍然能够有效地从二维规则网格表示的给定彩色图像中提取形状细节。为了解决这个问题,需要从两个方面进行考虑。在3D几何方面,文章在网格模型上直接建立了基于图的完全卷积网络(GCN),将网格中的顶点和边直接表示为图中的节点和连接。在每个顶点上保存3D形状的网络特征编码信息。通过前向传播,卷积层实现相邻节点之间的特征交换,最终回归每个顶点的三维位置。在2D方面,采用类似VGG-16的结构来提取特征。为了将3D和2D连接起来,文章设计了一种感知特征汇合层。其允许GCN中的每个节点从其在图像上的二维投影中汇集图像特征,那可以通过假设摄像机的内部矩阵来容易地获得。感知特征池在几次卷积之后被启用一次。使用更新的3D位置,因此来自正确位置的图像特征可以有效地与3D形状集成。 在给定图形表示的情况下,下一个挑战是如何有效地更新顶点位置以接近真实信息情况。在实践中可见,训练成直接预测具有大量顶点的网格的网络,在开始时容易出错,之后很难修复。原因之一是一个顶点不能有效地从远离多条边的其他顶点检索特征,即接受域受限。为了解决这个问题,文章设计了一个图解池化层,允许网络以较少的顶点开始,并在前向传播过程中增加;在开始阶段,由于顶点数量少,网络学习将周围的顶点分布到最具代表性的位置,然后随着顶点数量的增加而添加局部细节。除了图解池化层之外,文中还使用由快捷连接增强的深度GCN作为架构的主干,其支持全局上下文更大的接受域和更多的移动步骤。 用图方法表示形状有利于学习过程。已知的连通性允许定义跨相邻节点的高阶损失函数,这对于3D形状的正则化非常重要。具体地说,文章定义法线损失来使表面光滑;边缘损失来促进网格顶点均匀分布以提高召回率;以及拉普拉斯损失来防止网格面彼此相交。所有这些损失对于生成高质量的网格模型都是必不可少的,没有图表示方法就不能简单地定义这些损失。 本文的模型学习将网格从一致的初始形状变形到目标几何形状。这有几个方面好处。首先,深度网络更适合预测残差,例如空间变形;而不是结构化输出,例如一个图结构。其次,可以将一系列变形叠加在一起,从而使形状逐渐细化到细节。它还可以很好把握深度学习模型的复杂性和结果质量之间的平衡。最后,它提供了将任何先验知识编码到初始网格的机会,例如拓扑。作为一个创新研究,在这篇文章中,专门研究了可以通过变形固定大小的椭球体来近似使用亏格为0的三维网格的对象。在实践中,大多数常见的对象在这种设置下都可以很好地处理,例如汽车、飞机、桌子等。 要实现上述目标,存在几个固有的挑战。第一个挑战是如何在神经网络中表示网格模型(本质上是一个不规则的图形)并且仍然能够有效地从二维规则网格表示的给定彩色图像中提取形状细节。为了解决这个问题,需要从两个方面进行考虑。在3D几何方面,文章在网格模型上直接建立了基于图的完全卷积网络(GCN),将网格中的顶点和边直接表示为图中的节点和连接。在每个顶点上保存3D形状的网络特征编码信息。通过前向传播,卷积层实现相邻节点之间的特征交换,最终回归每个顶点的三维位置。在2D方面,采用类似VGG-16的结构来提取特征。为了将3D和2D连接起来,文章设计了一种感知特征汇合层。其允许GCN中的每个节点从其在图像上的二维投影中汇集图像特征,那可以通过假设摄像机的内部矩阵来容易地获得。感知特征池在几次卷积之后被启用一次。使用更新的3D位置,因此来自正确位置的图像特征可以有效地与3D形状集成。 在给定图形表示的情况下,下一个挑战是如何有效地更新顶点位置以接近真实信息情况。在实践中可见,训练成直接预测具有大量顶点的网格的网络,在开始时容易出错,之后很难修复。原因之一是一个顶点不能有效地从远离多条边的其他顶点检索特征,即接受域受限。为了解决这个问题,文章设计了一个图解池化层,允许网络以较少的顶点开始,并在前向传播过程中增加;在开始阶段,由于顶点数量少,网络学习将周围的顶点分布到最具代表性的位置,然后随着顶点数量的增加而添加局部细节。除了图解池化层之外,文中还使用由快捷连接增强的深度GCN作为架构的主干,其支持全局上下文更大的接受域和更多的移动步骤。 用图方法表示形状有利于学习过程。已知的连通性允许定义跨相邻节点的高阶损失函数,这对于3D形状的正则化非常重要。具体地说,文章定义法线损失来使表面光滑;边缘损失来促进网格顶点均匀分布以提高召回率;以及拉普拉斯损失来防止网格面彼此相交。所有这些损失对于生成高质量的网格模型都是必不可少的,没有图表示方法就不能简单地定义这些损失。
主要贡献
1.提出了一种新的端对端的神经网络架构,其可以从单张彩色图片生成三维网格模型。 2.设计了一个投影层,将感知图像特征融入到由GCN表示的三维几何中。 3.该网络由粗糙到细致的方式预测3D几何图形,更可靠,更易学习。
待续…
由于才刚刚进入三维重建领域学习,笔记更多的是翻译作者原文的形式记载,难以把握重点。
|