| 性能指标 | 您所在的位置:网站首页 › 测温枪说明书中技术指标的含义 › 性能指标 |
性能指标
|
软件性能的影响因素
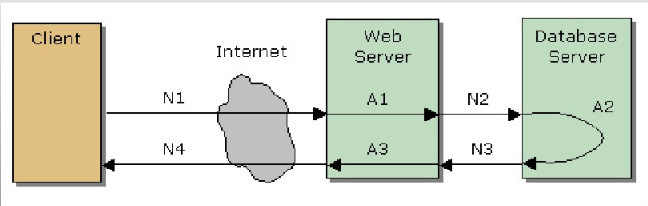
(1)硬件设施(部署结构、机器配置) (2)网络环境(客户端带宽、服务器端带宽) (3)操作系统(类型、版本、参数配置) (4)中间件(类型、版本、参数配置) (5)应用程序(性能) (6)并发用户数(系统当前访问状态) (7)客户端 (8)数据服务器 (9)编程语言、程序实现方式、算法 性能测试最基本要考虑以下几点1、时间特性,主要指的是软件产品的事务响应时间(用户发出请求到收到应答的这段时间) 2、资源利用率,包括:cpu、内存、网络、硬盘、虚拟内存(如Java虚拟机) 3、服务器可靠性,指服务器能在相对高负载情况下持续的运行 4、可配置优化性,指服务器配置优化、业务逻辑优化、代码优化等 检查系统是否满足需求规格说明书中规定的性能,通常表现在以下几个方面:1、对资源利用(包括:cpu、内存、网络、硬盘、虚拟内存(如Java虚拟机)等)进行的精确度量; 2、对执行间隔; 3、日志事件(如中断,报错) 4、响应时间 5、吞吐量(TPS) 6、辅助存储区(例如缓冲区、工作区的大小等) 7、处理精度等进行的监测 在实际工作中我们经常会对两种类型软件进行测试:bs和cs,这两方面的性能指标一般需要哪些内容呢?bs结构程序一般会关注的通用指标如下(简): Web服务器测试指标: * Avg Rps: 平均每秒钟响应次数=总请求时间 / 秒数; * Avg time to last byte per terstion (mstes):平均每秒业务脚本的迭代次数,有人会把这两者混淆; * Successful Rounds:成功的请求; * Failed Rounds :失败的请求; * Successful Hits :成功的点击次数; * Failed Hits :失败的点击次数; * Hits Per Second :每秒点击次数; * Successful Hits Per Second :每秒成功的点击次数; * Failed Hits Per Second :每秒失败的点击次数; * Attempted Connections :尝试链接数; CS结构程序,由于一般软件后台通常为数据库,所以我们更注重数据库的测试指标: * User 0 Connections :用户连接数,也就是数据库的连接数量; * Number of deadlocks:数据库死锁; * Buffer Cache hit :数据库Cache的命中情况 当然,在实际中我们还会察看多用户测试情况下的内存,CPU,系统资源调用情况。这些指标其实是引申出来性能测试中的一种:竞争测试。什么是竞争测试,软件竞争使用各种资源(数据纪录,内存等),看他与其他相关系统对资源的争夺能力。 我们知道软件架构在实际测试中制约着测试策略和工具的选择。如何选择性能测试策略是我们在实际工作中需要了解的。一般软件可以按照系统架构分成几种类型: c/s client/Server 客户端/服务器架构 基于客户端/服务器的三层架构 基于客户端/服务器的分布式架构 b/s 基于浏览器/Web服务器的三层架构 基于中间件应用服务器的三层架构l 基于Web服务器和中间件的多层架构l 性能指标的两个方面 从外部看,性能测试主要关注如下四个指标 吞吐量:每秒钟系统能够处理客户的请求数、任务数,其直接体现系统的承载的能力。 并发用户数:同一时刻与服务器进行数据交互的所有用户数量; 响应时间:服务处理一个请求或一个任务的耗时。 错误率:一批请求中结果出错的请求所占比例。 响应时间从单个请求来看就是服务响应一次请求的花费的时间。但是在性能测试中,单个请求的响应时间并没有什么参考价值,通常考虑的是完成所有请求的平均响应时间及中位数时间。 平均响应时间很好理解,就是完成请求花费的总时间/完成的请求总数。但是平均响应时间有一点不靠谱,因为系统的运行并不是平稳平滑的,如果某几个请求的时间超短或者超长就会导致平均数偏离很多。因此有时候我们会用中位数响应时间。 所谓中位数的意思就是把将一组数据按大小顺序排列,处在最中间位置的一个数叫做这组数据的中位数 ,这意味着至少有50%的数据低于或高于这个中位数。当然,最为正确的统计做法是用百分比分布统计。也就是英文中的TP – Top Percentile ,TP50的意思在,50%的请求都小于某个值,TP90表示90%的请求小于某个时间。 响应时间的指标取决于具体的服务。如智能提示一类的服务,返回的数据有效周期短(用户多输入一个字母就需要重新请求),对实时性要求比较高,响应时间的上限一般在100ms以内。而导航一类的服务,由于返回结果的使用周期比较长(整个导航过程中),响应时间的上限一般在2-5s。 决定系统响应时间要素我们做项目要排计划,可以多人同时并发做多项任务,也可以一个人或者多个人串行工作,始终会有一条关键路径,这条路径就是项目的工期。 系统一次调用的响应时间跟项目计划一样,也有一条关键路径,这个关键路径是就是系统响应时间; 关键路径是由CPU运算、IO、外部系统响应等等组成。 计算公式 1、响应时间:对一个请求做出响应所需要的时间 网络传输时间:N1+N2+N3+N4 应用服务器处理时间:A1+A3 数据库服务器处理时间:A2 响应时间=网络响应时间+应用程序响应时间=(N1+N2+N3+N4)+(A1+A2+A3) 2、平均响应时间:所有请求花费的平均时间 系统处理事务的响应时间的平均值。事务的响应时间是从客户端提交访问请求到客户端接收到服务器响应所消耗的时间。对于系统快速响应类页面,一般响应时间为3秒左右。 如:如果有100个请求,其中 98 个耗时为 1ms,其他两个为 100ms 平均响应时间: (98 * 1 + 2 * 100) / 100.0 = 2.98ms,但是,2.98ms并不能反映服务器的整体效率,因为98个请求耗时才1ms,引申出百分位数 百分位数:以响应时间为例,指的是 99% 的请求响应时间,都处在这个值以下,更能体现整体效率。 注:(一般响应时间在3s内,用户会感觉比较满意。在3s~8s之间用户勉强能接受,大于8s用户就可能无法接受,从而刷新页面或者离开,仅供参考) 响应时间与负载对应关系
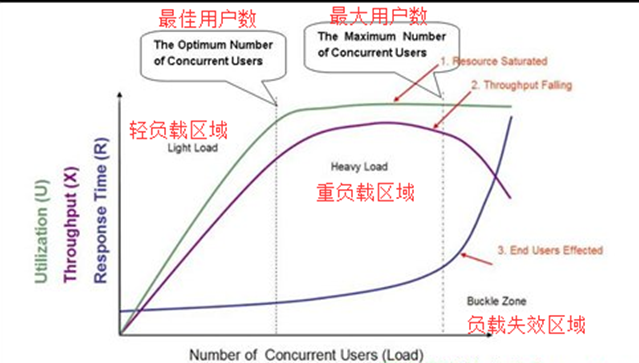
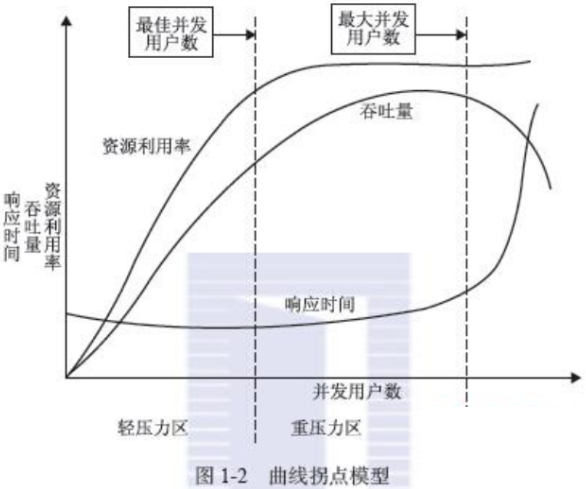
图中拐点说明:(1)响应时间突然增加(2)意味着系统的一种或多种资源利用达到的极限(3)通常可以利用拐点来进行性能测试分析与定位 并发用户数一、首先涉及到并发用户数可以从以下几个方面去做数据判断。 1.系统用户数 2.在线用户数 3.并发用户数 二、三者之间的关系 1.在线用户数的预估可以采取20%的系统用户数。例如某个系统在系统用户数有1000,则同时在线用户数据有可能达到200,或者预估200做参考。 2.在线用户数和并发用户数又存在着关系。即:平均并发用户数为:c=NL/T L为在线时长,T为考核时长。例如:考核时长为1天,即8小时,但是用户平均在线时长为2小时,则c=n*2/8 n为登录系统的用户数,L为登录的时常。例如:一个系统有400个用户登录,然后每个用户登录大概停留2小时,则以一天8小时考核,算平均并发用户则为:c=400*2/8 并发主要是针对服务器而言,在同一时刻与服务器进行交互(指向服务器发出请求)的在线用户数。 (1)并发用户数:某一物理时刻同时向系统提交请求的用户数,提交的请求可能是同一个场景或功能,也可以是不同场景或功能。 (2)在线用户数:某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求。如多个用户在浏览网页,但没有对同时对服务器进行数据请求,需要与并发用户数区分开。 (3)系统用户数:系统注册的总用户数据 三者之间的关系:系统用户数 >= 在线用户数 >= 并发用户数 同时在线用户数:在一定的时间范围内,最大的同时在线用户数量。 同时在线用户数=每秒请求数RPS(吞吐量)+并发连接数+平均用户思考时间 平均并发用户数的计算:C=nL / T 其中C是平均的并发用户数,n是平均每天访问用户数(login session),L是一天内用户从登录到退出的平均时间(login session的平均时间),T是考察时间长度(一天内多长时间有用户使用系统) 并发用户数峰值计算:C^约等于C + 3*根号C 也是峰值C1,即最大并发数,计算公式C1=C+³√C 其中C^是并发用户峰值,C是平均并发用户数,该公式遵循泊松分布理论。 注:理解最佳并发用户数和最大并发用户数 看了《LoadRunner没有告诉你的》之理发店模式,对最佳并发用户数和最大的并发用户数的理解小小整理了一下。 所谓的理发店模式,简单地阐述一下,一个理发店有3个理发师,当同时来理发店的客户有3个的时候,那么理发师的资源能够有效地利用,这时3个用户数即为最佳的并发用户数;当理发店来了9个客户的时候,3个客户理发,而6个用户在等待,3个客户的等待时间为1个小时,另外的3个客户的等待时间为2小时,客户的最大忍受时间为3小时包括理发的1个小时,所以6个客户的等待时间都在客户的可以承受范围内,故9个客户是该理发店的最大并发用户数。 吞吐量我把吞吐量定义为“单位时间内系统处理的客户请求的数量”( 吞吐量表示单位时间内能够完成的事务数量,因此也被称为每秒事务数(Transaction Per Second),计算方式是完成的事务数除以时间。),直接体现软件系统的性能承载能力,对于交互式应用系统来说、吞吐量反映的是服务器承受的压力、在容量规划的测试中、吞吐量是一个重要指标、它不但反映在中间件、数据库上、更加体现在硬件上。 吞吐量的指标受到响应时间、服务器软硬件配置、网络状态等多方面因素影响。 吞吐量越大,响应时间越长。 服务器硬件配置越高,吞吐量越大。 网络越差,吞吐量越小。在低吞吐量下的响应时间的均值、分布比较稳定,不会产生太大的波动。在高吞吐量下,响应时间会随着吞吐量的增长而增长,增长的趋势可能是线性的,也可能接近指数的。当吞吐量接近系统的峰值时,响应时间会出现激增。 系统吞度量要素 一个系统的吞度量(承压能力)与request对CPU的消耗、外部接口、IO等等紧密关联。单个reqeust 对CPU消耗越高,外部系统接口、IO影响速度越慢,系统吞吐能力越低,反之越高。 系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间 QPS(每秒请求数)(TPS (Transaction Per Second)每秒事务数):每秒钟系统处理的request/事务数量,它是衡量系统处理能力的重要指标; 并发数:系统同时处理的request/事务数 响应时间:一般取平均响应时间 理解了上面三个要素的意义之后,就能推算出它们之间的关系:QPS(TPS)= 并发数/平均响应时间 一个系统吞吐量通常由QPS(TPS)、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下降。 系统吞吐量评估我们在做系统设计的时候就需要考虑CPU运算、IO、外部系统响应因素造成的影响以及对系统性能的初步预估。而通常情况下,我们面对需求,我们评估出来的QPS、并发数之外,还有另外一个维度:日页面流量PV。 PV:访问一个URL,产生一个PV(Page View,页面访问量),每日每个网站的总PV量是形容一个 网站规模的重要指标。 UV:作为一个独立的用户,访问站点的所有页面均算作一个UV(Unique Visitor,用户访问) 通过观察系统的访问日志发现,在用户量很大的情况下,各个时间周期内的同一时间段的访问流量几乎一样。只要能拿到日流量图和QPS我们就可以推算日流量。 通常的技术方法: 1. 找出系统的最高TPS和日PV,这两个要素有相对比较稳定的关系(除了放假、季节性因素影响之外) 2. 通过压力测试或者经验预估,得出最高TPS,然后跟进1的关系,计算出系统最高的日吞吐量。 无论有无思考时间(T_think),测试所得的TPS值和并发虚拟用户数(U_concurrent)、Loadrunner读取的交易响应时间(T_response)之间有以下关系(稳定运行情况下):TPS=U_concurrent / (T_response+T_think)。 并发数、QPS、平均响应时间三者之间关系 X轴代表并发用户数,Y轴代表资源利用率、吞吐量、响应时间。 X轴与Y轴区域从左往右分别是轻压力区、重压力区、拐点区。 随着并发用户数的增加,在轻压力区的响应时间变化不大,比较平缓,进入重压力区后呈现增长的趋势,最后进入拐点区后倾斜率增大,响应时间急剧增加。接着看吞吐量,随着并发用户数的增加,吞吐量增加,进入重压力区后逐步平稳,到达拐点区后急剧下降,说明系统已经达到了处理极限,有点要扛不住的感觉。 同理,随着并发用户数的增加,资源利用率逐步上升,最后达到饱和状态。 最后,把所有指标融合到一起来分析,随着并发用户数的增加,吞吐量与资源利用率增加,说明系统在积极处理,所以响应时间增加得并不明显,处于比较好的状态。但随着并发用户数的持续增加,压力也在持续加大,吞吐量与资源利用率都达到了饱和,随后吞吐量急剧下降,造成响应时间急剧增长。轻压力区与重压力区的交界点是系统的最佳并发用户数,因为各种资源都利用充分,响应也很快;而重压力区与拐点区的交界点就是系统的最大并发 用户数,因为超过这个点,系统性能将会急剧下降甚至崩溃。 Light Load(较轻压力)-----最佳用户数(资源利用最高)---(较重压力,系统可以持续工作,但用户等待时间较长,满意度会下降)-----Heavy Load-------最大并发用户数--------Buckle Zone(用户无法忍受而放弃请求) 最佳并发用户数:当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待最大并发用户数:系统的负载一直持续,有些用户在处理而有的用户在自己最大的等待时间内等待的时候 我们需要保证的是: (1)最佳并发用户数需大于系统的平均负载 (2)系统的最大并发用户数要大于系统需要承受的峰值负载 怎么理解这两句话呢? (1)系统的平均负载:在特定的时间内,系统正在处理的用户数和等待处理的用户数的总和 如果系统的平均负载大于最佳并发用户数,则用户的满意度会下降,所以我们需要保证系统的平均负载小于或者等于最佳并发用户数 (2)峰值:指的是系统的最大能承受的用户数的极值 只有最大并发用户数大于系统所能承受的峰值负载,才不会造成等待空间资源的浪费,导致系统的效率低下 计算公式指单位时间内系统处理用户的请求数 从业务角度看,吞吐量可以用:请求数/秒、页面数/秒、人数/天或处理业务数/小时等单位来衡量 从网络角度看,吞吐量可以用:字节/秒来衡量 对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力 以不同方式表达的吞吐量可以说明不同层次的问题,例如,以字节数/秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈;已请求数/秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈。 当没有遇到性能瓶颈的时候,吞吐量与虚拟用户数之间存在一定的联系,可以采用以下公式计算:F=VU * R /T 其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间
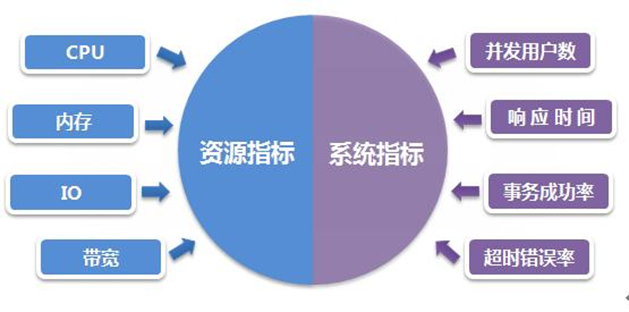
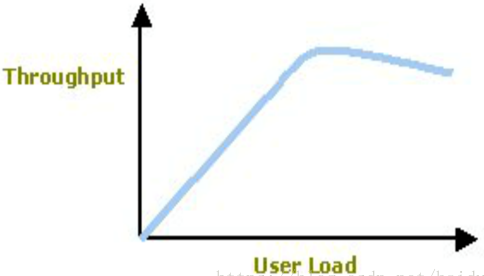
图中拐点说明:(1)吞吐量逐渐达到饱和(2)意味着系统的一种或多种资源利用达到的极限(3)通常可以利用拐点来进行性能测试分析与定位 错误率超时错误率:主要指事务由于超时或系统内部其它错误导致失败占总事务的比率。 错误率和服务的具体实现有关。通常情况下,由于网络超时等外部原因造成的错误比例不应超过5%%,由于服务本身导致的错误率不应超过1% 。 内部指标|资源指标(与硬件资源消耗相关指标) 资源利用率:资源利用率指的是对不同系统资源的使用程度,一般使用“资源实际使用/总的资源可用量”形成资源利用率。例如服务器的 CPU 利用率、磁盘利用率等。资源利用率是分析系统性能指标进而改善性能的主要依据,因此,它是 Web 性能测试工作的重点。资源利用率主要针对 Web 服务器、操作系统、数据库服务器、网络等,是测试和分析瓶颈的主要参数。在性能测试中,要根据需要采集具体的资源利用率参数来进行分析。 从服务器的角度看,性能测试主要关注CPU、内存、服务器负载、网络、磁盘IO等
注:PR数值越小,其进程优先级越高,就优先被执行。 TIME+表示的是这个进程或则命令持续在线活跃了多长时间。 1.硬件性能指标:CPU,内存Memory,磁盘I/O(Disk I/O),网络I/O(Network I/O) CPU:主要解释计算机指令以及处理计算机软件中的数据 Linux系统中top命令查看CPU的使用率 CPU的利用率( |




【本文地址】