| 清华大学车辆学院李升波 | 您所在的位置:网站首页 › 汽车如何分类别 › 清华大学车辆学院李升波 |
清华大学车辆学院李升波
|
2022年北京智源大会自动驾驶论坛,清华大学车辆与运载学院李升波教授分享了题为《混合型强化学习及其高级别自动驾驶应用》的主题报告。该报告主要探讨了如何将强化学习应用于自动驾驶汽车的问题,目标是让自动驾驶汽车具备自我学习、自我进化的能力,即与人类驾驶员的开车学习过程类似,达到越学越好、越开越好的特点。该报告首先介绍了自动驾驶与强化学习结合的必要性,分析了现有强化学习算法的特点与不足,介绍了所提出的集成式决控(IDC)架构和混合策略梯度(MPG)算法,最后以实车测试结果为例,介绍了这一技术方案应用过程的成功经验与下一步发展方向。
李升波,清华大学车辆与运载学院副院长,长聘教授,博士生导师,学习工作于斯坦福大学,密歇根大学和加州伯克利大学。从事智能网联汽车、自动驾驶汽车、强化学习、最优控制与估计等领域研究。发表SCI/EI论文>130篇,引用超过11500次,入选ESI高引11篇,国内外学术会议优秀论文奖9次。入选国家级高层次人才项目、交通部中青年科技创新领军人才、首届北京市自然科学基金杰青等。兼任IEEE OJ ITS高级副主编、IEEE Trans on ITS/IEEE ITS Mag副主编等。 整理:任黎明 Part 1: 自动驾驶选择强化学习的原因
智能化是汽车新四化变革的重要方向之一,也是人工智能(AI)的重要应用领域,受到学界和业界的广泛关注。目前,L1和L2级别的智能汽车已经实现商业化应用。具有更高智能性、接近人类驾驶水平的高级别自动驾驶汽车,是该领域每一个企业、每一个团队追求的理想和目标。因为城市道路交通场景中道路结构的高度复杂性、交通流的高度动态性以及交通参与者的高度随机性等,L3和L4级的自动驾驶功能实现具有挑战性,这需要更加安全可靠的环境感知能力和更加智能、实时、高效的决策控制能力。
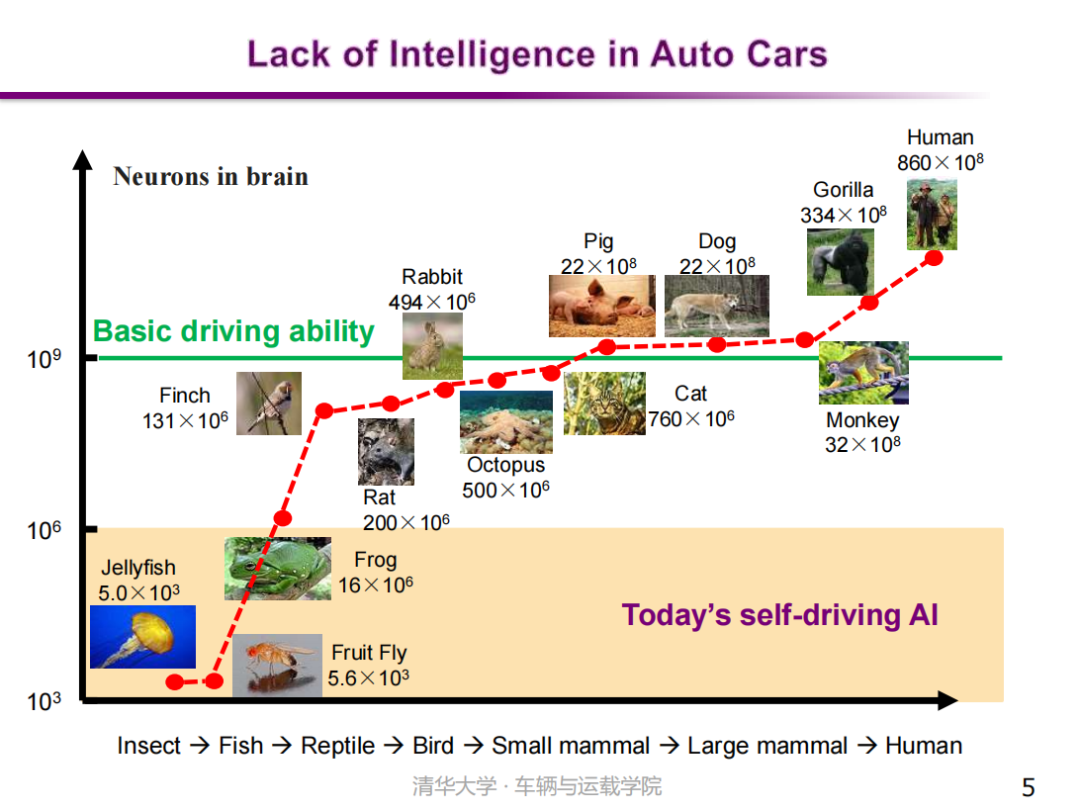
然而当前自动驾驶汽车智能水平还有待进一步提高。一个有趣的例子是很多高级哺乳动物,比如说人类的好朋友“宠物狗”也可以进行一定程度的车辆驾驶。这些都是真实的“宠物狗”开车视频,可以看出,聪明的动物们是可以做到车道保持、弯道转向等功能的。因此,如果以驾驶过程的自主性和适用性作为衡量指标,现有自动驾驶系统的水平可能还不及宠物狗的应对能力。这几乎是目前大多数自动驾驶智能水平的真实状态。
如何判断自动驾驶汽车的智能水平呢? 从生物大脑入手观察是一个不错的视角。通常的观点是,生物智能性的高低和其大脑神经元的数量密切相关。若以深度神经网络作为智能性的承载体,一个智能体(Agent)的智能性和人工神经网络的规模也有直接关系。目前,用于自动驾驶汽车的神经网络规模大概达到了百万或千万级别,但这仍然远远低于典型哺乳动物的神经元数量。更不要说,单个机器神经元的能力远远低于人类神经元的能力。所以,现有的自动驾驶技术远没有达到人类的驾驶智能,仅适用于简单稀疏交通工况,还不能应对城市复杂道路交通场景,并且对未知场景的适应能力也存在一定的不足。
近年,强化学习作为一类自主进化型学习方法得到了普遍关注。一个典型的例子是围棋智能的突破。谷歌DeepMind的第一代围棋智能(AlphaGo),采用监督学习与强化学习结合的方式训练落子的决策智能,使其具备战胜人类职业棋手的能力。电脑下围棋可以打败人类职业棋手,这一里程碑事件是之前大家不敢想象的事情。尤其是AlphaZero这一版本,采用自我更新、自我进化的机制,仅用21天的自我学习就可以战胜之前的AlphaGo版本,这展示出了强化学习具有类似人类学习机制的巨大潜力。
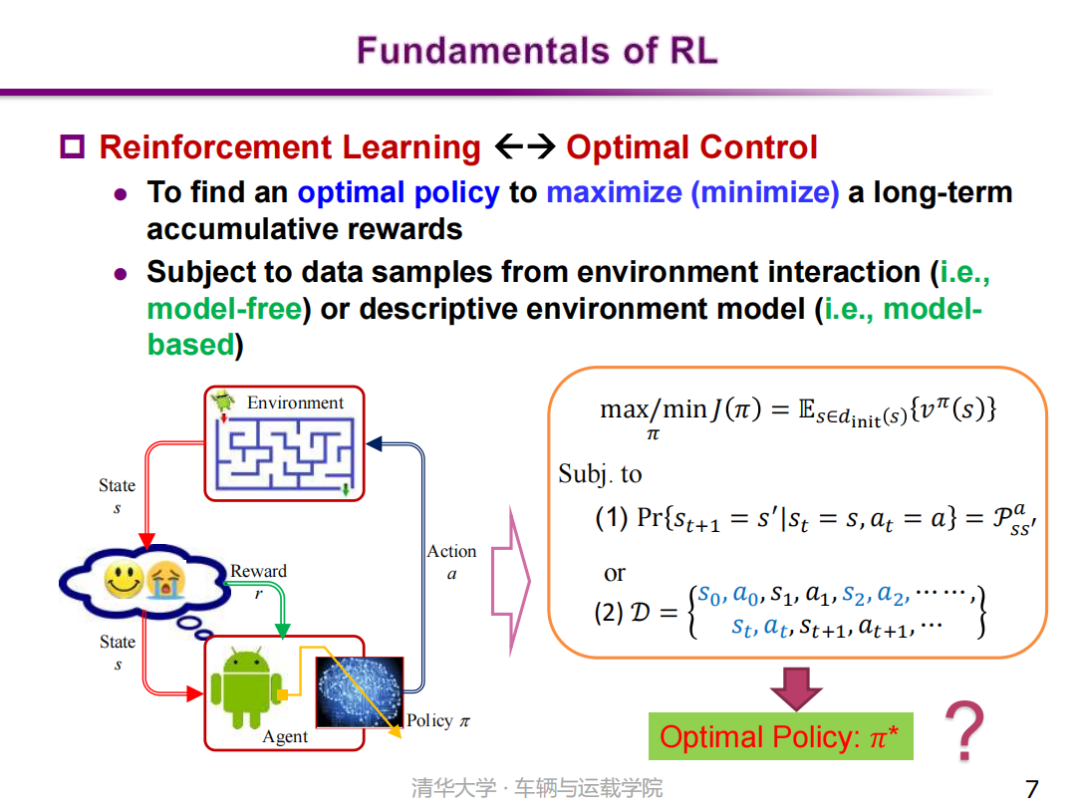
那么什么是强化学习呢?强化学习是一种模仿动物学习行为的自学习决策方法。研究表明:动物(包括人类)是通过不断地探索试错进行学习的,尽量重复带来奖励的行为,尽量避免产生惩罚的行为。实际上强化学习与最优控制是具有密切关联性的,强化学习是寻找最优策略、最大化未来累积奖励的过程,它与最优控制存在本质上的关联性。因此,我们可以将强化学习视作一个最优控制问题,只不过强化学习大多处理随机性环境,而传统的最优控制大多处理确定性环境。按照这一思想,依据强化学习是否使用环境动力学模型,分为带模型(model-based)和无模型(model-free)两类方法。
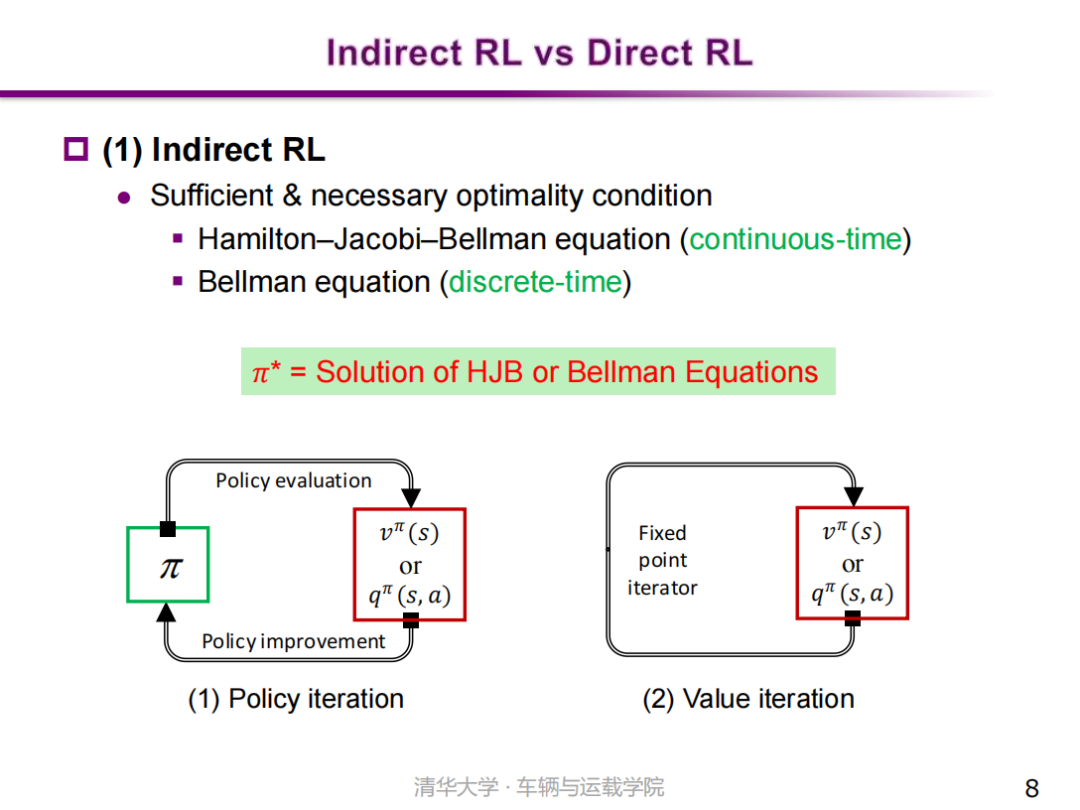
同时,按照最优策略的获得方式,又将强化学习分为间接式强化学习(Indirect RL)和直接式强化学习(Direct RL)两大类别。间接式强化学习(Indirect RL)的基本原理是通过求解问题的最优性条件得到最优策略。针对连续时间问题,一般采用哈密顿-雅可比-贝尔曼方程(HJB equation)进行求解;针对离散时间问题,则采用贝尔曼方程(Bellman equation)进行求解。 |




【本文地址】