| 汉字的编码 | 您所在的位置:网站首页 › 汉字算是字符串吗 › 汉字的编码 |
汉字的编码
|
汉字的编码
字符集和编码
字符集:是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。 字符编码:在符号集合与二进制之间建立对应关系 常用的字符集:ASCII字符集、GB2312字符集、BIG5字符集、GBK字符集、GB18030字符集、Unicode字符集等。 ASCII字符集
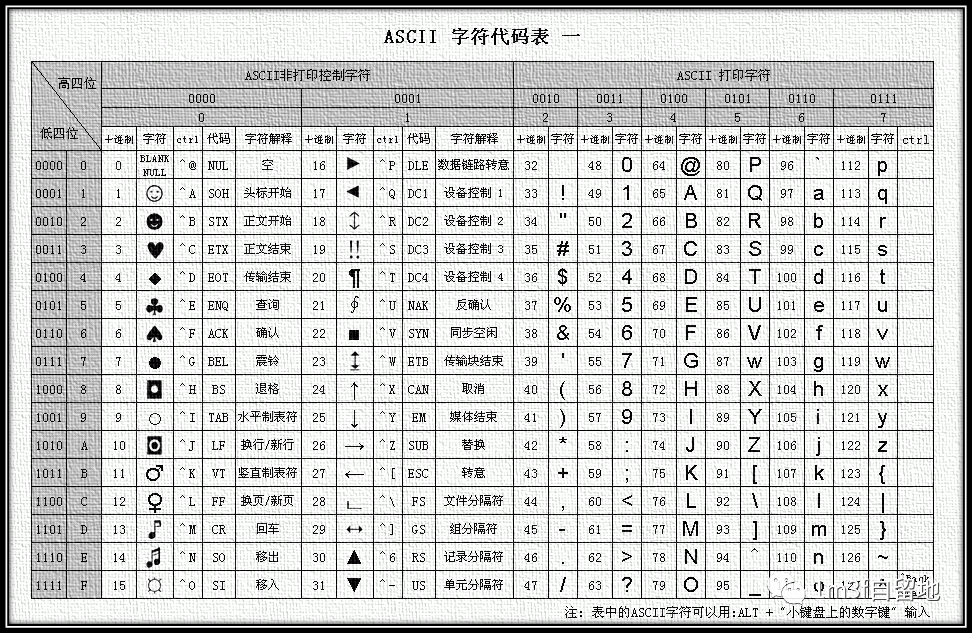
img ASCII码表只用了一个字节的低7bit来表示一个字符,一共128个,只能显示现代美国英语,同为英语国家的英国的英镑符号£也没有收录。欧洲各国纷纷为方便自己的使用,对剩下的128位进行了扩展,但是每个国家设计的又都不一样,为了结束这种混乱的局面,于是在ASCII码表的基础上扩展出了EASCII(Extended ASCII)码表。
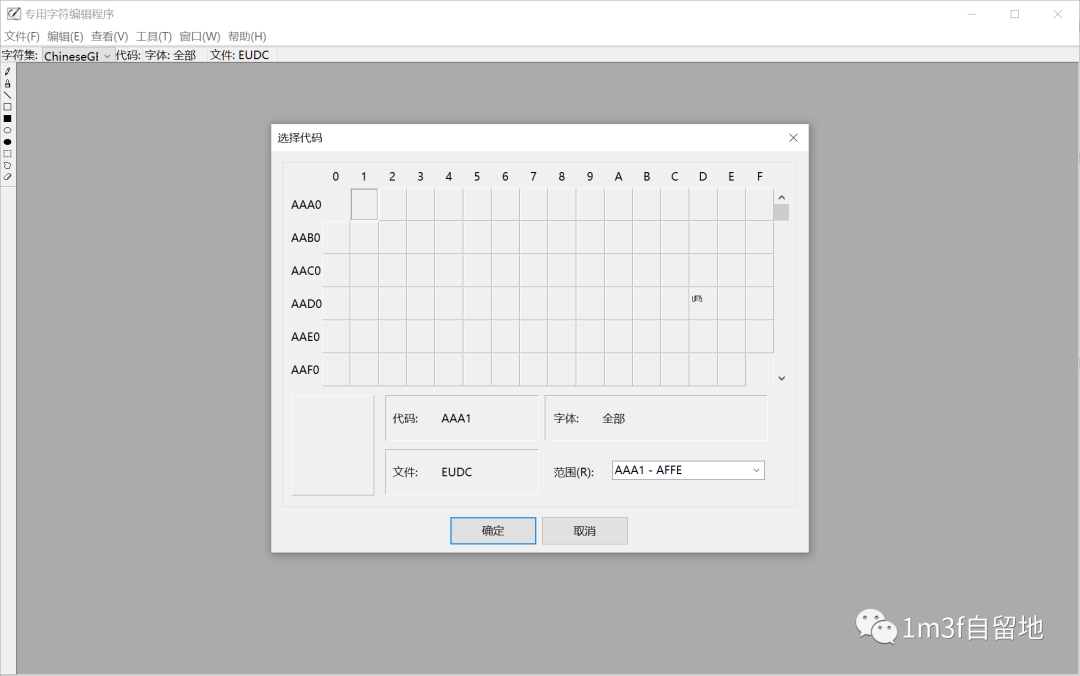
img GB2312、GBK、GB18030字符集GB 2312-1980,全称《信息交换用汉字编码字符集 基本集》,由国家标准总局于1980年3月9号发布,1981年5月1日实施,通行于大陆。新加坡等地也使用此编码。它是一个简化字的编码规范,也包括其他的符号、字母、日文假名等,共7445个图形字符,其中汉字占6763个。 GB2312采用一种叫区位码的方式进行编码,里面每一个字符都是将字符所在的区和位分别与xA0进行加法计算,得到的两个字节就是这个字符对应的机位码。每个字节从A0~`FF`(不考虑首位)有94种可能,所以理论上GB2312一共可以容纳94*94=8836个字符。 在94个区中又进一步按标点、假名、字母等进行分区 区描述01中文标点、数学符号以及一些特殊字符02序号03全角西文字符04日文平假名05日文片假名06希腊字母表07俄文字母表08中文拼音字母表09制表符号10-15未定义16-55一级汉字(以拼音字母排序)56-87二级汉字(以部首笔画排序)88-94未定义GBK编码表[1] 以第一个汉字啊为例,啊是16区01位,区位码1601(👈十进制),分别和xA0相加得xB0 xA1,所以啊在GB2312下的机位码是B0A1。GB2312里还包含了ASCII码表里的标点符号和数字,但是同样占用两个字节,这就是全角符号。 GBK是在GB2312的基础上进行的扩展,向下兼容GB2312,不是国家标准,相传由微软协助完成。 GBK的编码范围x8140 ~ xFEFE,总计23940 个码位,收录汉字21003 个,图形符号883 个。 GB18030全称《信息技术 中文编码字符集》,是中华人民共和国[2]国家标准[3]所规定的变长多字节字符集。完全兼容GB2312,基本兼容GBK。 • 采用变长多字节[4]编码,每个字可以由1个(兼容ASCII)、2个(兼容GBK)或4个字节组成。 • 编码空间庞大,最多可定义161万个字符。 • 完全支持Unicode,无需动用造字区即可支持中国国内少数民族[5]文字、中日韩和繁体汉字以及emoji[6]等字符。 Unicode字符集和UTF-8编码百度百科:Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。 Unicode只规定了每个字符对应的码点,但是没有规定怎么储存。 编码实现:UTF-8、UTF-16、UTF-32 UTF-8是1~4字节的可变长编码方式,UTF-16是2或4字节编码方式,UTF-32是4字节定长编码 UTF-8编码规则: 单字节的符号,字节第一位是0,这里码点和ASCII码是一致的 对于N字节的符号,第一个字节的前N位是1,N+1位是0,后面N-1个字节的前两位都是10,其余位用该字符的Unicode码点补齐,不足位补0 Unicode码点(16进制)UTF-8编码方式(2进制)0 - 7F0xxxxxxx80 - 7FF110xxxxx 10xxxxxx800 - FFFF1110xxxx 10xxxxxx 10xxxxxx1 0000 - 10 FFFF11110xxx 10xxxxxx 10xxxxxx 10xxxxxxANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。在国内ANSI表示GBK,在台湾ANSI表示BIG-5,在美国ANSI表示ASCII Big endian or Little endian大端(Big endian)更符合人的直观读取,比如0x12345678存储的就是 0x12 0x34 0x56 0x78,符号位的判定固定为第一个字节,容易判断正负。TCP/IP协议规定了必须大端传输,所以又叫网络字节序。 小端(Little endian)强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。Intel的大量CPU都采用小端字节序,所以又叫主机字节序。 BOM (byte order mark)用来标识大端存储还是小端存储,UTF-8不需要BOM,会在文件头部插入3个字节EF BB BF,会对linux上脚本执行造成影响(会破坏#!标识)。BOM主要是用来标注UTF-16和UTF-32的,windows 7记事本上的Unicode其实是UTF-16小端保存,windows 10 已经修改位UTF-16 LE和UTF-16 BE。 不同编码方式头部插入的BOM BOMEncodingEF BB BFUTF-8FE FFUTF-16 (big-endian)FF FEUTF-16 (little-endian)00 00 FE FFUTF-32 (big-endian)FF FE 00 00UTF-32 (little-endian)FEFF是一个叫做ZERO WIDTH NO-BREAK SPACE,是一个不可读的符号,因为FF刚好比FE大1,FFFE又不存在,所以用这两个字节来表示编码的大小端。 乱码 锟斤拷乱码的出现是由于字符的编码和解码使用了不兼容的格式 在处理显示字符时,对于无法显示的符号,Unicode会用0xFFFD来表示,也就是�,用UTF-8表示是EF BF BD,当有两个连续的无法显示的字符��(EF BF BD EF BF BD),这个时候如果用GBK解码就会变成3个字符,就对应锟斤拷三个汉字。 烫烫烫 vs 屯屯屯在VC 的debug模式下,在栈中新分配的内存会初始化为0xCC,在堆中新分配的内存会初始化为0xCD,这时打印出来分别对应烫和屯 记事本和联通的矛盾(win7)打开记事本,输入联通两个汉字,用默认的ANSI(GBK)保存,再次打开这个文件会发现出现乱码��。 首先看一下“联通”的GBK编码:C1 AA CD A8 其二进制表示是1100 0001 1010 1010 1100 1101 1010 1000 其二进制形式110x xxxx 10xx xxxx匹配了UTF-8的2字节表示形式,所以记事本推测是UTF-8的编码,但是又不存在对应的UTF-8编码的字符,所以会显示Unicode的替换字符� 一般情况下,出现�时说明是以UTF-8的编码方式打开/读取的文件,而文件本身不是以UTF-8保存的,所以会出现乱码。这个时候应该以其他编码方式重新打开,而不是另存为修改编码,否则就会出现锟斤拷。 造字win+R打开运行窗口,输入eudcedit,打开专用字符编辑程序
image-20201015174815406 在选择代码区域选择一个码点之后点击确定,这里码点对应的是GBK的码点,需要切换成Unicode显示
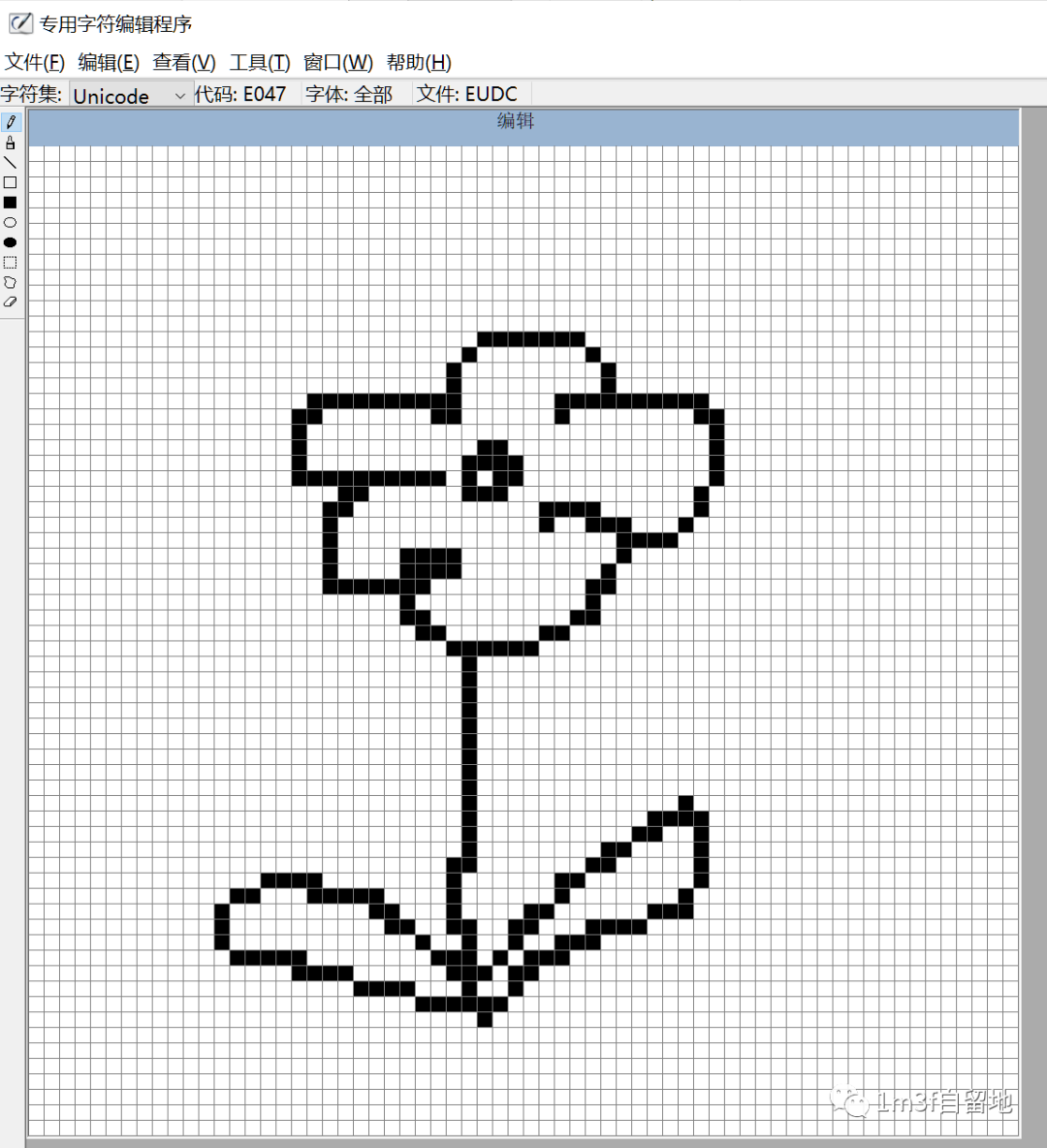
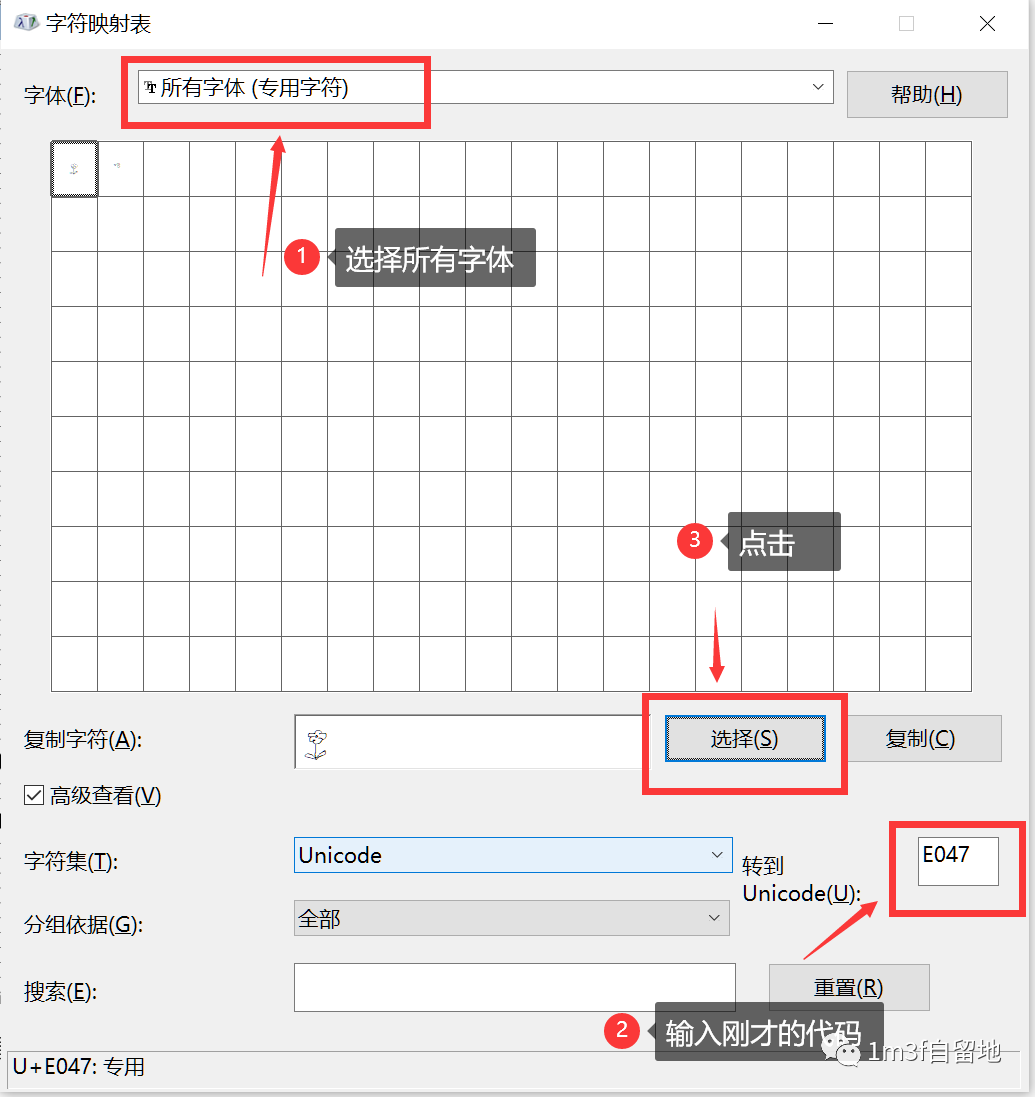
在编辑区域画出你想要的符号,然后点击编辑→保存字符,记住这里的代码,上面是E047 然后打开字符映射表
image-20201015175318059 然后复制所选择的字符,打开notepad粘贴,保存文件 这个符号可以复制粘贴到windows自带的一些软件上,包括Microsoft Edge浏览器、Office办公、记事本等,IDEA代码编辑区粘贴显示其Unicode码点,通过输出可以显示该符号。但是不支持复制到Chrome浏览器和其他的编辑器比如VS Code 用十六进制编辑器打开刚才的文件
image-20201015175444088 可以看到ANSI默认使用的UTF-8编码,和刚才的代码进行下转换,E047落在UTF-8第3档,所以是3字节 E0 -> 1110 0000 47 -> 0100 0111 3字节模板:1110 ____ 10__ ____ 10__ ____从右往左填冲:1110 1110 1000 0001 1000 0111转成十六进制:EE 81 87 引用链接[1] GBK编码表: https://www.qqxiuzi.cn/zh/hanzi-gb2312-bianma.php [2] 中华人民共和国: https://baike.baidu.com/item/中华人民共和国 [3] 国家标准: https://baike.baidu.com/item/国家标准 [4] 字节: https://baike.baidu.com/item/字节 [5] 少数民族: https://baike.baidu.com/item/少数民族 [6] emoji: https://baike.baidu.com/item/emoji ---------------------------END--------------------------- 题外话“不是只有程序员才要学编程?!” 认真查了一下招聘网站,发现它其实早已变成一项全民的基本技能了。 连国企都纷纷要求大家学Python! 世界飞速发展,互联网、大数据冲击着一切,各行各业对数据分析能力的要求越来越高,这便是工资差距的原因,学习编程顺应了时代的潮流。 在这个大数据时代,从来没有哪一种语言可以像Python一样,在自动化办公、爬虫、数据分析等领域都有众多应用。 更没有哪一种语言,语法如此简洁易读,消除了普通人对于“编程”这一行为的恐惧,从小学生到老奶奶都可以学会。 《2020年职场学习趋势报告》显示,在2020年最受欢迎的技能排行榜,Python排在第一。 它的角色类似于现在Office,成了进入职场的第一项必备技能。 如果你也想增强自己的竞争力,分一笔时代的红利,我的建议是,少加点班,把时间腾出来,去学一学Python。 因为,被誉为“未来十年的职场红利”的Python,赚钱、省钱、找工作、升职加薪简直无所不能! 目前,Python人才需求增速高达**174%,人才缺口高达50万,**部分领域如人工智能、大数据开发, 年薪30万都招不到人! 感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。 
一、Python所有方向的学习路线 Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具 工具都帮大家整理好了,安装就可直接上手! 三、最新Python学习笔记 当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集 观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例 纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。 六、面试宝典

|













【本文地址】