| AI:机器学习的正则化 (Regularization) | 您所在的位置:网站首页 › 正则化规则 › AI:机器学习的正则化 (Regularization) |
AI:机器学习的正则化 (Regularization)
|
目录
机器学习:正则化 (Regularization)正则化的方法1.参数正则化1.0 范数1.1 L2 Regularization(Ridge Regression,权重衰减)1.2 L1 Regularization:将噪点相关权重系数设为0(也叫稀疏正则化)1.3 L1/L2对比:
2. 经验正则化(早停、丢弃Dropout)博主热门文章推荐:
机器学习:正则化 (Regularization)
先一波总结: 为什么要正则化:让模型不要过于依赖样本数据正则化主要思想:降低模型的复杂度正则化主要目的:防止模型过拟合正则化实现思路:最小化损失Loss+ 最小复杂度正则化终极目标:提升模型泛化Generalization的能力
那么正则化是啥,为什么需要正则化?:因为要让AI模型不过于信赖样本数据,否则是不是就不能好好学习了, 举个栗子,比如让模型小A备考一个考试,学习过程他每天过于研究历年真题,真题固定题型完全不在话下,学到只会做真题,那么真正考试中出现新题型,悲剧 , 不会了,这里也是一样。这时候老师就说了,小A要使用正则化方法,平衡真题学习力度,做到既研究好真题,又不只限于真题。。。嗯 好像老师真这样说过。。 所以说Regularization 本质上是防止模型过拟合 正则化的方法正则化有不同的策略,目前来讲主要有参数正则化、经验正则化 1.参数正则化参数正则的L2/L1 Regularization 范数正则化目前用的是最多的。。。 参数正则化方法的核心主要是对损失函数Loss Function 添加惩罚项 Penalty: 上面所谓的L1/L2是数学中向量空间的范数 L1范数,其表示某个向量中所有元素绝对值的和。L2范数, 表示某个向量中所有元素平方和再开根, 也就是欧氏距离常用的最小二乘法(LS算法)就是L2的一个具体应用 在学习参数正则化前, 回顾下正则化核心思想和目标 思想:降低模型复杂度,(根据奥卡姆剃刀定律)目标:最小化 损失+复杂度 为目标(结构风险最小化)即: 为避免离群值这种影响,引入Lambda(又称正则化率)来调制正则化项的整体影响 则变成: 模型学习速率和Lambda之间强相关 现在训练优化算法有2项内容组成:损失项 + 正则化项 • 损失项:用于衡量算法模型与数据的拟合度 • 正则化项:衡量算法模型的复杂度 1.1 L2 Regularization(Ridge Regression,权重衰减)L2范数在回归里面,它的回归叫“岭回归”(Ridge Regression),也叫它“权值衰减weight decay” L2范数向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,即前面所说的惩罚项为:
这个过程中,更小的权值w,即表示模型的复杂度更低,对数据的拟合就不会过于强烈 L2正则化核心是量化模型复杂度:L2 = 所有特征权重的平方和
在L2正则中,接近于0的权重对复杂度几乎没有影响,而离群值权重会产生巨大影响,所以是时候回引申出L1 Regularization了: 1.2 L1 Regularization:将噪点相关权重系数设为0(也叫稀疏正则化)L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。所以L1正则化可以产生稀疏模型。 在原始的损失函数后面加上一个L1正则化项 为什么需要用L1: 特征组合可能会包含许多维度,模型太庞大占用大量RAM,因此,对权重降为0,既可以节省空间,也可以减少模型中的噪点 L1核心思想:将无意义的特征维度降为0
• L2只能将权重变小,但是不能将他们降为0 • 采用不同方式降低权重w:L2会降低w的平方,L1是减w的绝对值,因此L2与L1具有不同的导数 2. 经验正则化(早停、丢弃Dropout)还有一些通过经验实现正则化,例如早停法(但该方法实际操作起来困难) 另一种形式的正则是丢弃法Dropout,经常用于神经网络: https://howiexue.blog.csdn.net/article/details/104271227 其原理就是:在梯度下降法的每一步中,随机丢弃一些网络单元,丢弃的越多,正则化效果越强 0 = 无丢弃正则化1 = 丢弃所有内容,模型学不到任何规律
一篇读懂系列: 一篇读懂无线充电技术(附方案选型及原理分析)一篇读懂:Android/iOS手机如何通过音频接口(耳机孔)与外设通信一篇读懂:Android手机如何通过USB接口与外设通信(附原理分析及方案选型)LoRa Mesh系列: LoRa学习:LoRa关键参数(扩频因子,编码率,带宽)的设定及解释LoRa学习:信道占用检测原理(CAD)LoRa/FSK 无线频谱波形分析(频谱分析仪测试LoRa/FSK带宽、功率、频率误差等)网络安全系列: ATECC508A芯片开发笔记(一):初识加密芯片SHA/HMAC/AES-CBC/CTR 算法执行效率及RAM消耗 测试结果常见加密/签名/哈希算法性能比较 (多平台 AES/DES, DH, ECDSA, RSA等)AES加解密效率测试(纯软件AES128/256)–以嵌入式Cortex-M0与M3 平台为例嵌入式开发系列: 嵌入式学习中较好的练手项目和课题整理(附代码资料、学习视频和嵌入式学习规划)IAR调试使用技巧汇总:数据断点、CallStack、设置堆栈、查看栈使用和栈深度、Memory、Set Next Statement等Linux内核编译配置(Menuconfig)、制作文件系统 详细步骤Android底层调用C代码(JNI实现)树莓派到手第一步:上电启动、安装中文字体、虚拟键盘、开启SSH等Android/Linux设备有线&无线 双网共存(同时上内、外网)AI / 机器学习系列: AI: 机器学习必须懂的几个术语:Lable、Feature、Model…AI:卷积神经网络CNN 解决过拟合的方法 (Overcome Overfitting)AI: 什么是机器学习的数据清洗(Data Cleaning)AI: 机器学习的模型是如何训练的?(在试错中学习)数据可视化:TensorboardX安装及使用(安装测试+实例演示) |
 图自台湾大学林轩田老师 Machine Learning Techniques (机器学习技法)
图自台湾大学林轩田老师 Machine Learning Techniques (机器学习技法)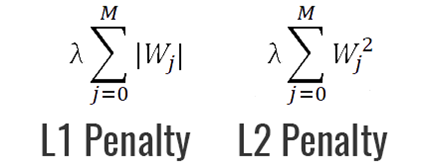 L2/L1正则化都是通过添加一个惩罚项,来调节模型参数(权重w),使loss最小,(例如w一开始数值大,则loss会变大,则在反向传播每次更新权重时,就会对这个w进行惩罚,既降低w,直到模型认为loss已经最优)
L2/L1正则化都是通过添加一个惩罚项,来调节模型参数(权重w),使loss最小,(例如w一开始数值大,则loss会变大,则在反向传播每次更新权重时,就会对这个w进行惩罚,既降低w,直到模型认为loss已经最优)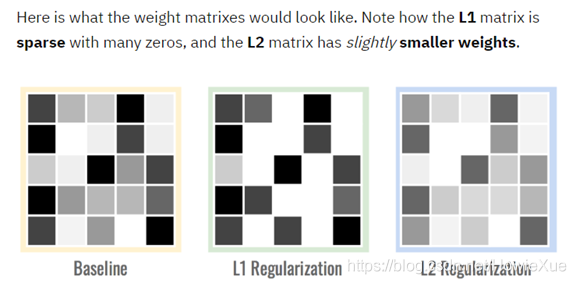
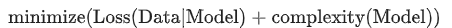
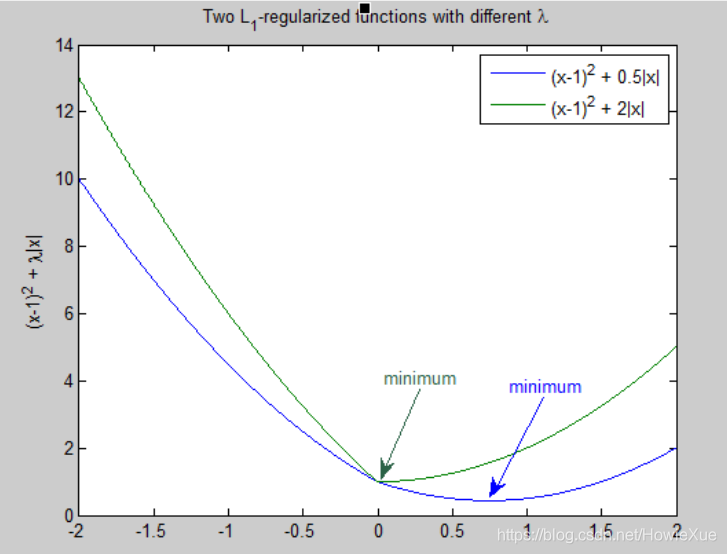
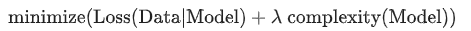 Lambda值需要在模型简单化和训练数据拟合之间达到适当的平衡 • Lambda高,模型简单,数据欠拟合 • Lambda低,模型复杂,数据过拟合
Lambda值需要在模型简单化和训练数据拟合之间达到适当的平衡 • Lambda高,模型简单,数据欠拟合 • Lambda低,模型复杂,数据过拟合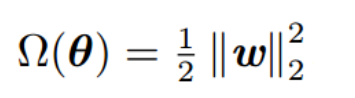 L2实现上,直接在原来的损失函数基础上加上权重参数的平方和如下,这样调节权重w变小,实现最小化loss 损失+复杂度的小目标:
L2实现上,直接在原来的损失函数基础上加上权重参数的平方和如下,这样调节权重w变小,实现最小化loss 损失+复杂度的小目标: 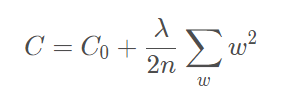
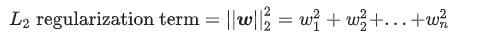 加入L2正则化结果:测试Lost明显减少,训练损失有所上升,特征权重的绝对值降低(模型复杂度降低) 例如大多数LR(逻辑回归)模型都会使用L2正则化来降低模型复杂度,并且LR非常容易过拟合,因为LR会尝试让所有样本的Lost减少到0,但始终达不到,所以每个LR指示器特征的权重就会不断增大到正无穷或负无穷
加入L2正则化结果:测试Lost明显减少,训练损失有所上升,特征权重的绝对值降低(模型复杂度降低) 例如大多数LR(逻辑回归)模型都会使用L2正则化来降低模型复杂度,并且LR非常容易过拟合,因为LR会尝试让所有样本的Lost减少到0,但始终达不到,所以每个LR指示器特征的权重就会不断增大到正无穷或负无穷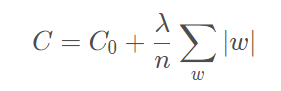

【本文地址】